POST TIME:2021-05-24 02:39
前言:這篇文章主要是介紹如何使用采集功能去采集一個(gè)圖片類的網(wǎng)站。這次選取的目標(biāo)站點(diǎn)為:站酷網(wǎng)的佳作欣賞欄目,其URL為:http://www.zcool.com.cn/shows/。本文將會(huì)涉及到如何處理被采集頁面含有分頁以及如何使用簡單的過濾規(guī)則。本文共分為三節(jié):第一節(jié),主要是介紹如何進(jìn)入采集界面和新增采集節(jié)點(diǎn)中的第一步:設(shè)置基本信息及網(wǎng)址索引頁規(guī)則;第二節(jié),主要是介紹新增采集節(jié)點(diǎn)中的第二步:設(shè)置字段獲取規(guī)則;第三節(jié),主要是介紹如何采集指定節(jié)點(diǎn)和如何導(dǎo)出采集內(nèi)容。
下面進(jìn)入第一節(jié)。
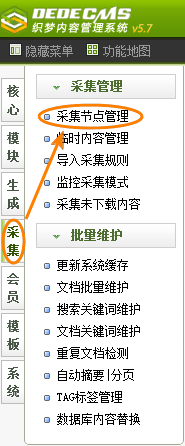
如(圖1)所示,在后臺(tái)管理界面的主菜單中單擊“采集”,然后單擊“采集節(jié)點(diǎn)管理”,即可進(jìn)入采集節(jié)點(diǎn)管理界面,如(圖2)所示。
(此圖片來源于網(wǎng)絡(luò),如有侵權(quán),請聯(lián)系刪除! )
圖1-后臺(tái)管理界面

(此圖片來源于網(wǎng)絡(luò),如有侵權(quán),請聯(lián)系刪除! )
圖2-采集節(jié)點(diǎn)管理界面
在采集節(jié)點(diǎn)管理界面中,單擊左下角的“增加新節(jié)點(diǎn)”或者右上角的“添加新節(jié)點(diǎn)”(如圖2),都可進(jìn)入“選擇內(nèi)容模型”界面,如(圖3)所示,

(此圖片來源于網(wǎng)絡(luò),如有侵權(quán),請聯(lián)系刪除! )
圖3-選擇內(nèi)容模型界面
在“選擇內(nèi)容模型”界面的下拉列表框中,有“普通文章”和“圖片集”可供選擇。
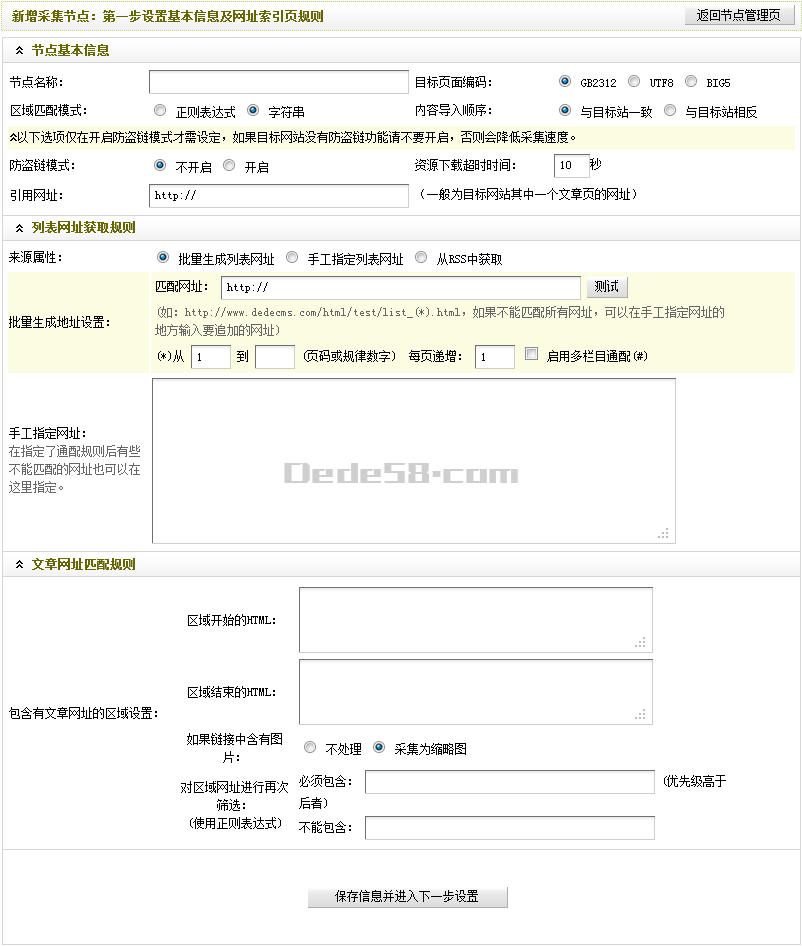
根據(jù)被采集頁面的類型,選擇相應(yīng)的內(nèi)容模型。本文這里選擇“圖片集”,單擊確定后,便可進(jìn)入“新增采集節(jié)點(diǎn):第一步設(shè)置基本信息及網(wǎng)址索引頁規(guī)則”界面,如(圖4)所示,
(此圖片來源于網(wǎng)絡(luò),如有侵權(quán),請聯(lián)系刪除! )
圖4-新增采集節(jié)點(diǎn):第一步設(shè)置基本信息及網(wǎng)址索引頁規(guī)則
(此圖片來源于網(wǎng)絡(luò),如有侵權(quán),請聯(lián)系刪除! )
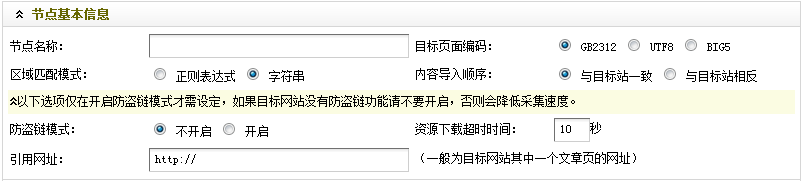
圖5-節(jié)點(diǎn)基本信息
如(圖5)所示,這里只是介紹如何獲取“目標(biāo)頁面編碼”,對于其他的設(shè)定,可參見之前的文章。具體操作步驟:
(a)打開被采集的目標(biāo)頁:http://www.zcool.com.cn/shows/;
(b)單擊右鍵后選擇“查看源文件”,找到“charset”, 如(圖6)所示,

(此圖片來源于網(wǎng)絡(luò),如有侵權(quán),請聯(lián)系刪除! )
圖6-查看源文件
其等號(hào)后面的代碼就是所需填寫的“編碼格式”,這里是“utf-8”。
填寫后,如(圖7)所示,
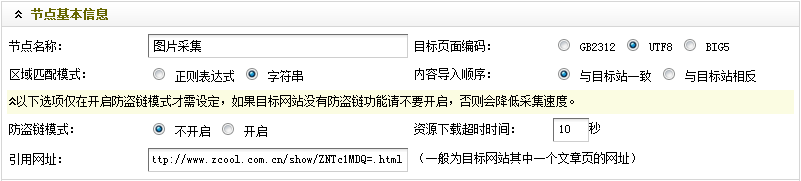
(此圖片來源于網(wǎng)絡(luò),如有侵權(quán),請聯(lián)系刪除! )
圖7-設(shè)置后的節(jié)點(diǎn)基本信息
檢查無誤后,進(jìn)入下一步設(shè)置。
(此圖片來源于網(wǎng)絡(luò),如有侵權(quán),請聯(lián)系刪除! )
圖8-列表網(wǎng)址獲取規(guī)則
如(圖8)所示,這里是設(shè)置被采集的文章列表頁的匹配規(guī)則。具體操作步驟:
(a)首先,回到已打開的列表頁,找到瀏覽器的URL地址欄中顯示的網(wǎng)址和頁面的換頁部分。如(圖9)和(圖10)所示,

(此圖片來源于網(wǎng)絡(luò),如有侵權(quán),請聯(lián)系刪除! )
圖9-瀏覽器的URL地址欄

(此圖片來源于網(wǎng)絡(luò),如有侵權(quán),請聯(lián)系刪除! )
圖10-換頁
(b)單擊“2”,打開文章列表頁的第二頁,再次找到瀏覽器的URL地址欄中所顯示的網(wǎng)址和頁面的換頁部分,如(圖12)和(圖13)所示,

(此圖片來源于網(wǎng)絡(luò),如有侵權(quán),請聯(lián)系刪除! )
圖11-第二頁的網(wǎng)址

(此圖片來源于網(wǎng)絡(luò),如有侵權(quán),請聯(lián)系刪除! )
圖12-第二頁的換頁
(c)在已打開的列表頁的第二頁上面,單擊(1),回到列表頁的首頁,這時(shí)頁面的換頁部分與之前的圖10是相同的,然而瀏覽器的URL地址欄中所顯示的網(wǎng)址與之前圖9并不相同,如(圖13)所示,

(此圖片來源于網(wǎng)絡(luò),如有侵權(quán),請聯(lián)系刪除! )
圖13-第一頁的網(wǎng)址
(d)由(b)和(c)可推知,這里被采集的列表頁的網(wǎng)址所遵循規(guī)律為:
http://www.zcool.com.cn/shows/0!0!0!200!(*)!1!0!0/。穩(wěn)妥起見,請自行測試更多列表頁。確定規(guī)律后,在“匹配網(wǎng)址”中,填入列表頁所遵循的規(guī)律。
(e)最后,根據(jù)需要指定采集的頁碼或者規(guī)律數(shù)字,并設(shè)定其遞增規(guī)律。
到這里,“列表網(wǎng)址獲取規(guī)則”部分就設(shè)置結(jié)束了。最后結(jié)果,如(圖14)所示,
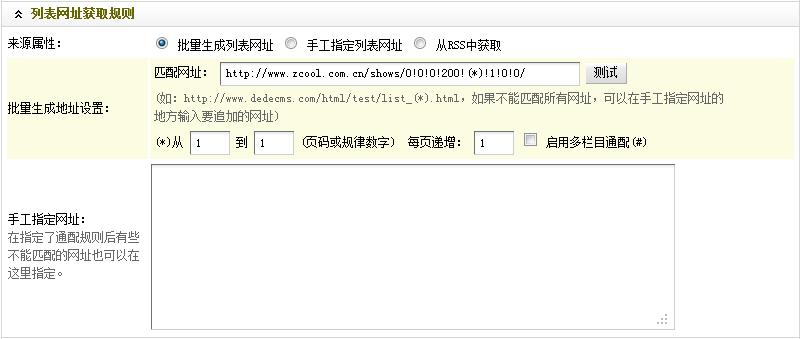
(此圖片來源于網(wǎng)絡(luò),如有侵權(quán),請聯(lián)系刪除! )
圖14-設(shè)置后的列表網(wǎng)址獲取規(guī)則
確定正確后,進(jìn)入下一步設(shè)置。
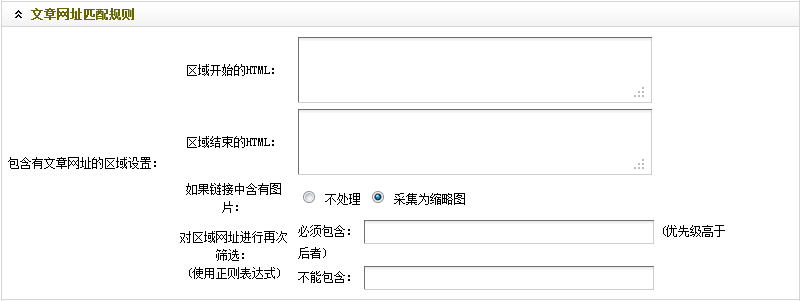
(此圖片來源于網(wǎng)絡(luò),如有侵權(quán),請聯(lián)系刪除! )
圖15-文章網(wǎng)址匹配規(guī)則
這里是設(shè)置被采集的列表頁的匹配規(guī)則。
具體操作步驟:
(a)對于“區(qū)域開始的HTML”,可以在已打開的列表首頁,單擊右鍵后選擇“查看源文件”查找出第一篇文章的標(biāo)題“高清壁紙”來獲得,如(圖16)所示,

(此圖片來源于網(wǎng)絡(luò),如有侵權(quán),請聯(lián)系刪除! )
圖16-查看源文件中,第一篇文章的標(biāo)題
通過觀察,不難看出“<ul class="list_left_nr">”為整個(gè)列表的開始部分。因此,在“區(qū)域開始的HTML”中,應(yīng)填入“<ul class="list_left_nr">”。
(b)在源文件中,找到最后一篇文章標(biāo)題“阿奴比斯”,如(圖17)所示,

(此圖片來源于網(wǎng)絡(luò),如有侵權(quán),請聯(lián)系刪除! )
圖17-查看源文件中,最后一篇文章的標(biāo)題
結(jié)合列表的開始部分并通過觀察可知,第一個(gè)“</ul>”為整個(gè)列表的結(jié)束部分,而其后的從“<ul class=”list_left_bottomw”>”到第二個(gè)“</ul>”,則為頁面的換頁部分。因此,在“區(qū)域結(jié)束的HTML”中,應(yīng)填入”</ul>”,意思是到第一個(gè)</ul>結(jié)束。
(c)經(jīng)過觀察圖16和圖17的文章標(biāo)題部分,可以發(fā)現(xiàn),標(biāo)題的鏈接地址都是含有“=.html”的。因此,可在“必須包含”中,填入“=.html”。
到這里,“文章網(wǎng)址匹配規(guī)則“就設(shè)置結(jié)束了。填寫后,如(圖18)所示,
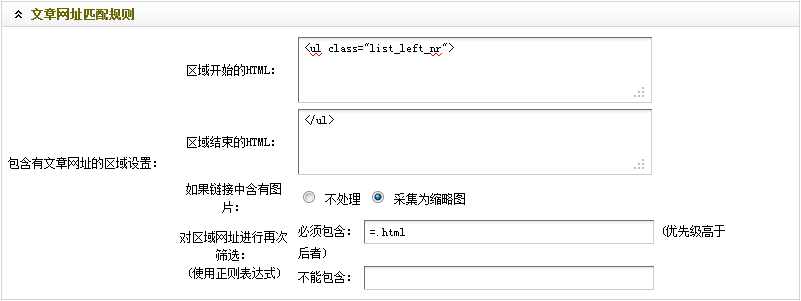
(此圖片來源于網(wǎng)絡(luò),如有侵權(quán),請聯(lián)系刪除! )
圖18-設(shè)置后的文章網(wǎng)址匹配規(guī)則
通過以上的三個(gè)小節(jié),新增采集節(jié)點(diǎn)的第一步就已經(jīng)設(shè)置完成了。設(shè)置后的最終結(jié)果,如(圖19)所示,
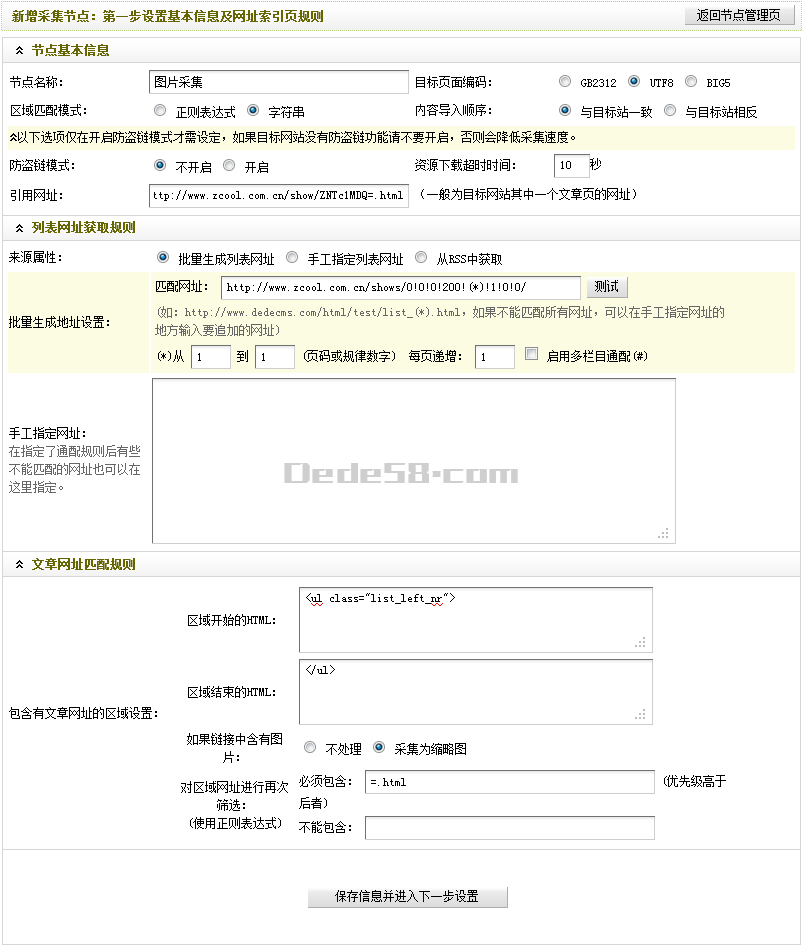
(此圖片來源于網(wǎng)絡(luò),如有侵權(quán),請聯(lián)系刪除! )
圖19-設(shè)置后的新增采集節(jié)點(diǎn):第一步設(shè)置基本信息及網(wǎng)址索引頁規(guī)則
全部完成并檢查無誤后,單擊“保存信息并進(jìn)入下一步設(shè)置“。如果之前設(shè)置正確,單擊后,將會(huì)進(jìn)入“新增采集節(jié)點(diǎn):測試基本信息及網(wǎng)址索引頁規(guī)則設(shè)置的網(wǎng)址獲取規(guī)則測試”頁面并看到相應(yīng)的文章列表地址。如(圖20)所示,

(此圖片來源于網(wǎng)絡(luò),如有侵權(quán),請聯(lián)系刪除! )
圖20-網(wǎng)址獲取規(guī)則測試
確定正確無誤后,單擊“保存信息并進(jìn)入下一步設(shè)置”。否則,請單擊“返回上一步進(jìn)行修改“。
到這里,第一節(jié)就結(jié)束了。下面進(jìn)入第二節(jié)。。。

| ? |
|
|
|
|||||||||||||||
| 全國咨詢熱線 | |||||||||||||||||
| 400-1100-266 | |||||||||||||||||
| 在線客服( QQ:340506921 ) | |||||||||||||||||