如何使用雙向RNN
在《深度學習之TensorFlow入門、原理與進階實戰》一書的9.4.2中的第4小節中,介紹過變長動態RNN的實現。
這里在來延伸的講解一下雙向動態rnn在處理變長序列時的應用。其實雙向RNN的使用中,有一個隱含的注意事項,非常容易犯錯。
本文就在介紹下雙向RNN的常用函數、用法及注意事項。
動態雙向rnn有兩個函數:
stack_bidirectional_dynamic_rnn
bidirectional_dynamic_rnn
二者的實現上大同小異,放置的位置也不一樣,前者放在contrib下面,而后者顯得更加根紅苗正,放在了tf的核心庫下面。在使用時二者的返回值也有所區別。下面就來一一介紹。
示例代碼
先以GRU的cell代碼為例:
import tensorflow as tf
import numpy as np
tf.reset_default_graph()
# 創建輸入數據
X = np.random.randn(2, 4, 5)# 批次 、序列長度、樣本維度
# 第二個樣本長度為3
X[1,2:] = 0
seq_lengths = [4, 2]
Gstacked_rnn = []
Gstacked_bw_rnn = []
for i in range(3):
Gstacked_rnn.append(tf.contrib.rnn.GRUCell(3))
Gstacked_bw_rnn.append(tf.contrib.rnn.GRUCell(3))
#建立前向和后向的三層RNN
Gmcell = tf.contrib.rnn.MultiRNNCell(Gstacked_rnn)
Gmcell_bw = tf.contrib.rnn.MultiRNNCell(Gstacked_bw_rnn)
sGbioutputs, sGoutput_state_fw, sGoutput_state_bw = tf.contrib.rnn.stack_bidirectional_dynamic_rnn([Gmcell],[Gmcell_bw], X,sequence_length=seq_lengths, dtype=tf.float64)
Gbioutputs, Goutput_state_fw = tf.nn.bidirectional_dynamic_rnn(Gmcell,Gmcell_bw, X,sequence_length=seq_lengths,dtype=tf.float64)
上面例子中是創建雙向RNN的方法示例。可以看到帶有stack的雙向RNN會輸出3個返回值,而不帶有stack的雙向RNN會輸出2個返回值。
這里面還要注意的是,在沒有未cell初始化時必須要將dtype參數賦值。不然會報錯。
代碼:BiRNN輸出
下面添加代碼,將輸出的值打印出來,看一下,這兩個函數到底是輸出的是啥?
#建立一個會話
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
sgbresult,sgstate_fw,sgstate_bw=sess.run([sGbioutputs,sGoutput_state_fw,sGoutput_state_bw])
print("全序列:\n", sgbresult[0])
print("短序列:\n", sgbresult[1])
print('Gru的狀態:',len(sgstate_fw[0]),'\n',sgstate_fw[0][0],'\n',sgstate_fw[0][1],'\n',sgstate_fw[0][2])
print('Gru的狀態:',len(sgstate_bw[0]),'\n',sgstate_bw[0][0],'\n',sgstate_bw[0][1],'\n',sgstate_bw[0][2])
先看一下帶有stack的雙向RNN輸出的內容:
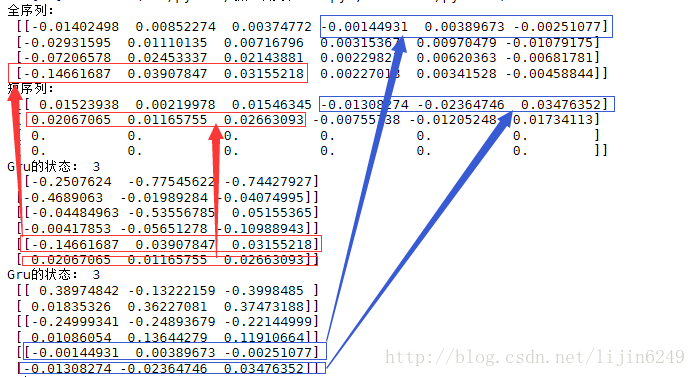
我們輸入的數據的批次是2,第一個序列長度是4,第二個序列長度是2.
圖中共有4部分輸出,可以看到,第一部分(全序列)就是序列長度為4的結果,第二部分(短序列)就是序列長度為2的結果。由于沒一層都是由3個RNN的GRU cell組成,所以每個序列的輸出都為3.很顯然,對于這樣的結果輸出,必須要將短序列后面的0去掉才可以用。
好在該函數還有第二個輸出值,GRU的狀態。可以直接使用狀態里的值,而不需要對原始結果進行去0的變化。
由于單個GRU本來就是沒有狀態的。所以該函數將最后的輸出作為狀態返回。該函數有兩個狀態返回,分別代表前向和后向。每一個方向的狀態都會返回3個元素。這是因為每個方向的網絡都有3層GRU組成。在使用時,一般都會取最后一個狀態。圖中紅色部分為前向中,兩個樣本對應的輸出,這個很好理解。
重點要看藍色的部分,即反向的狀態值對應的是原始數據中最其實的序列輸入。因為是反向RNN,在反向循環時,是會把序列中最后的放在最前面,所以反向網絡的生成結果就會與最開始的序列相對應。
對于特征提取任務處理時,正向與反向的最后值都為該序列的特征,需要合并起來統一處理。但是對于下一個序列預測任務時,建議直接使用正向的RNN網絡就可以了。
如果要獲取雙向RNN的結果,尤其是變長情況下,通過狀態拿到值直接拼接起來才是正確的做法。即便不是變長。直接使用輸出值來拼接,會損失掉反向的一部分特征結果。這是需要值得注意的地方。
代碼:BiRNN輸出
好了。在接著看下不帶stack的函數輸出是什么樣子的
gbresult,state_fw=sess.run([Gbioutputs,Goutput_state_fw])
print("正向:\n", gbresult[0])
print("反向:\n", gbresult[1])
print('狀態:',len(state_fw),'\n',state_fw[0],'\n',state_fw[1]) #state_fw[0]:【層,批次,cell個數】 重頭到最后一個序列
print(state_fw[0][-1],state_fw[1][-1])
out = np.concatenate((state_fw[0][-1],state_fw[1][-1]),axis = 1)
print("拼接",out)
這次,在輸出基本內容基礎上,直接將結果拼接起來。上面代碼運行后會輸出如下內容。
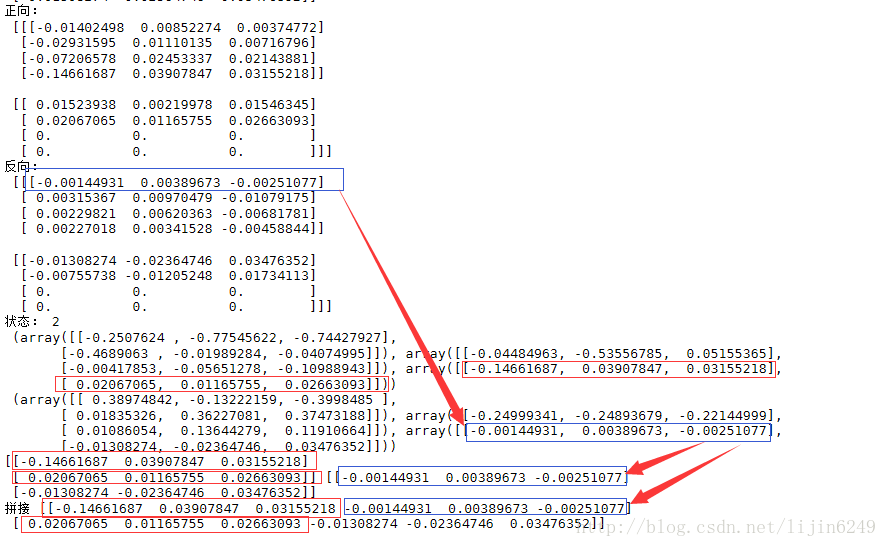
同樣正向用紅色,反向用藍色。改函數返回的輸出值,沒有將正反向拼接。輸出的狀態雖然是一個值,但是里面有兩個元素,一個代表正向狀態,一個代表反向狀態.
從輸出中可以看到,最后一行實現了最終結果的真正拼接。在使用雙向rnn時可以按照上面的例子代碼將其狀態拼接成一條完整輸出,然后在進行處理。
代碼:LSTM的雙向RNN
類似的如果想使用LSTM cell。將前面的GRU部分替換即可,代碼如下:
stacked_rnn = []
stacked_bw_rnn = []
for i in range(3):
stacked_rnn.append(tf.contrib.rnn.LSTMCell(3))
stacked_bw_rnn.append(tf.contrib.rnn.LSTMCell(3))
mcell = tf.contrib.rnn.MultiRNNCell(stacked_rnn)
mcell_bw = tf.contrib.rnn.MultiRNNCell(stacked_bw_rnn)
bioutputs, output_state_fw, output_state_bw = tf.contrib.rnn.stack_bidirectional_dynamic_rnn([mcell],[mcell_bw], X,sequence_length=seq_lengths,
dtype=tf.float64)
bioutputs, output_state_fw = tf.nn.bidirectional_dynamic_rnn(mcell,mcell_bw, X,sequence_length=seq_lengths,
dtype=tf.float64)
至于輸出的內容是什么,可以按照前面GRU的輸出部分顯示出來自己觀察。如何拼接,也可以參照GRU的例子來做。
通過將正反向的狀態拼接起來才可以獲得雙向RNN的最終輸出特征。千萬不要直接拿著輸出不加處理的來進行后續的運算,這會損失一大部分的運算特征。
該部分內容屬于《深度學習之TensorFlow入門、原理與進階實戰》一書的內容補充。關于RNN的更多介紹可以參看書中第九章的詳細內容。
我對雙向RNN 的理解
1、雙向RNN使用的場景:有些情況下,當前的輸出不只依賴于之前的序列元素,還可能依賴之后的序列元素; 比如做完形填空,機器翻譯等應用。
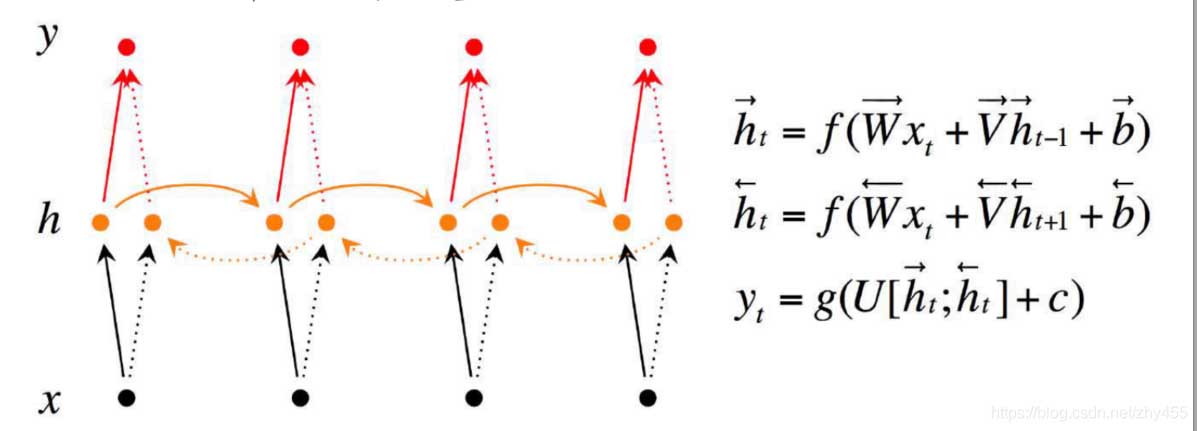
2、Tensorflow 中實現雙向RNN 的API是:bidirectional_dynamic_rnn; 其本質主要是做了兩次reverse:
第一次reverse:將輸入序列進行reverse,然后送入dynamic_rnn做一次運算.
第二次reverse:將上面dynamic_rnn返回的outputs進行reverse,保證正向和反向輸出的time是對上的.
以上為個人經驗,希望能給大家一個參考,也希望大家多多支持腳本之家。
您可能感興趣的文章:- Tensorflow與RNN、雙向LSTM等的踩坑記錄及解決
- 淺談Tensorflow 動態雙向RNN的輸出問題
- 雙向RNN:bidirectional_dynamic_rnn()函數的使用詳解
