POST TIME:2021-05-24 02:40
前言:本文是“含有分頁的普通文章的采集方法“的第二節,在前一節的基礎上,這一節會對新增采集節點中的第二步:“設置字段獲取規則”做詳細的介紹。為了與前文保持一致,本文將延續使用前文的章節標記。
上接第一節。
單擊“保存信息并進入下一步設置”后,便可進入“新增采集節點:第二步設置內容字段獲取規則”頁面,如(圖14)所示,

(此圖片來源于網絡,如有侵權,請聯系刪除! )
圖14-設置內容字段獲取規則
系統將會自動指定一個“預覽網址”,一般是文章列表頁的第一篇文章的網址。但是,由于第一篇文章中沒有涉及到分頁的部分,所以在這里手動更改為,第二篇文章的網址:“http://www.bitscn.com/network/protocol/201105/193110.html”,更改后,如(圖15)所示,

(此圖片來源于網絡,如有侵權,請聯系刪除! )
圖15-更改后的預覽地址
下面來設定分頁部分的匹配規則。其具體操作步驟為:
打開文章內容頁面,在網頁上單擊右鍵,在彈出的對話框中單擊“查看源文件“。在源代碼中,找到分頁代碼的開始部分和結束部分,如(圖16)所示,

(此圖片來源于網絡,如有侵權,請聯系刪除! )
圖16-分頁代碼
經過觀察可知,分頁代碼位于“<div class=”page next-page”>“和”</div>”之間。因此,在”內容分頁導航所在的區域匹配規則“中,應填寫”<div class=”page next-page”>[內容]</div> “。對于分頁代碼的樣式,一共有三種可供選擇,這里應選擇第一種” 全部列出的分頁列表”。填寫后,如(圖17)所示,

(此圖片來源于網絡,如有侵權,請聯系刪除! )
圖17-設置后的網頁內容獲取規則
對于“固定采集項目”中的“內容摘要、關鍵字和縮略圖“三個部分,系統會用正則進行自動匹配,這里僅需配置過濾內容即可。下面主要介紹如何獲取“文章標題、文章作者、文章來源、發布時間和文章內容”的采集規則,過濾規則僅簡單涉及。
首先,打開“預覽網址“的頁面并單擊右鍵,選擇”查看源代碼“,找到文章標題” OpenFlow網絡是空談嗎?“,如(圖18)所示,

(此圖片來源于網絡,如有侵權,請聯系刪除! )
圖18-在源代碼中的文章標題
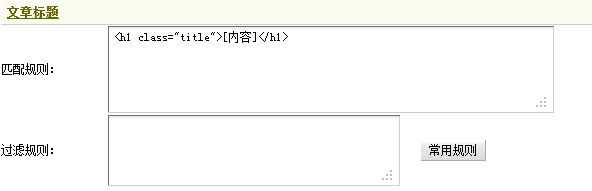
這里的文章標題處在”<h1 class=“title”></h1>”之間,因此這里應該填寫”<h1 class=“title”>[內容]</h1>”作為文章標題的匹配規則。如果在文章標題中含有相關鏈接等,可使用過濾規則加以處理,這里無需設置。填寫后,如(圖19)所示,
(此圖片來源于網絡,如有侵權,請聯系刪除! )
圖19-文章標題的采集規則
經過查找源代碼和對比原文的標題部分,可發現本文沒有涉及到文章作者,所以這里不用填寫,空著即可。
在上圖19中,可發現來源的內容介于“<span>來源:“和“</span>”之間,因此這里應填寫“<span>來源:[內容]</span>”作為文章來源的采集規則。同樣,這里也不需要使用過濾規則。填寫后,如圖20所示,

(此圖片來源于網絡,如有侵權,請聯系刪除! )
圖20-文章來源的采集規則
再次回到圖17,可找到“時間:2011-05-13 11:47”,因此這里應把“時間:[內容]<span>”作為發布時間的采集規則。同樣,這里也不需要使用過濾規則。填寫后,如圖21所示,

(此圖片來源于網絡,如有侵權,請聯系刪除! )
圖21-文章發布時間的采集規則
這個部分是編寫采集規則的重點,也是難點。需要特別注意。
具體操作步驟:
(a)在在打開的文章內容頁面的源代碼中,找到文章內容的開始部分“計算機網絡知識的學習”,如圖22所示,

(此圖片來源于網絡,如有侵權,請聯系刪除! )
圖22-文章內容的開始部分
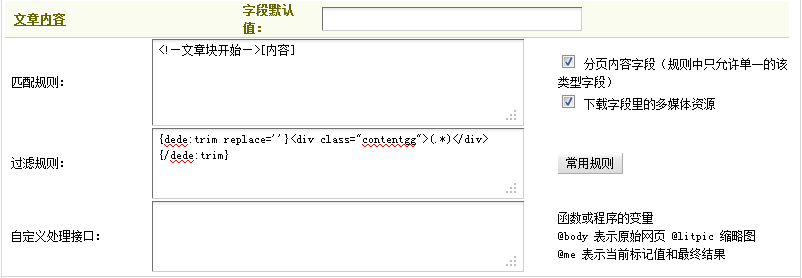
這里應把”<!—文章塊開始—>”作為匹配規則的開始部分,注意到這段代碼中包含一段廣告代碼,需要采用過濾規則把其去除。經觀察發現,這段JS廣告代碼是位于“<div class=”contentgg”>”和“</div>”之間的。因此,應在“過濾規則”中填寫:“{dede:trim replace=’’}<div class=”contentgg”>(.*)</div>”{/dede:trim}。填寫后,如(圖23)所示,
(此圖片來源于網絡,如有侵權,請聯系刪除! )
圖23-開始部分的匹配規則及其過濾規則
(b)找到文章內容的結束部分,因為涉及到分頁部分,所以應該選取分頁結束的位置,如圖24所示,

(此圖片來源于網絡,如有侵權,請聯系刪除! )
圖24-文章內容的結束部分
這里應選取“<!—文章內分頁結束-->”作為文章內容的結束部分,由于在選取的內容中又包含了一段JS代碼,因此應再次使用過濾規則,把其去除。同時,考慮到本頁沒有涉及到分頁,所以在分頁代碼中的<ul></ul>之間是空的。但是,如果頁面包含分頁的話,也是應該使用過濾規則去除的。此外,如果所設定的文章內容中,含有圖片、鏈接等不希望被采集到的內容,也應該使用過濾規則一并去除掉。填寫完成后,如(圖25)所示,

(此圖片來源于網絡,如有侵權,請聯系刪除! )
圖25-文章內容的匹配規則
到這里,“新增采集節點:第二步設置內容字段獲取規則”,就設置完成了。來看一下整個配置頁面,如(圖26)所示,

(此圖片來源于網絡,如有侵權,請聯系刪除! )
圖26-設置后的新增采集節點:第二步設置內容字段獲取規則
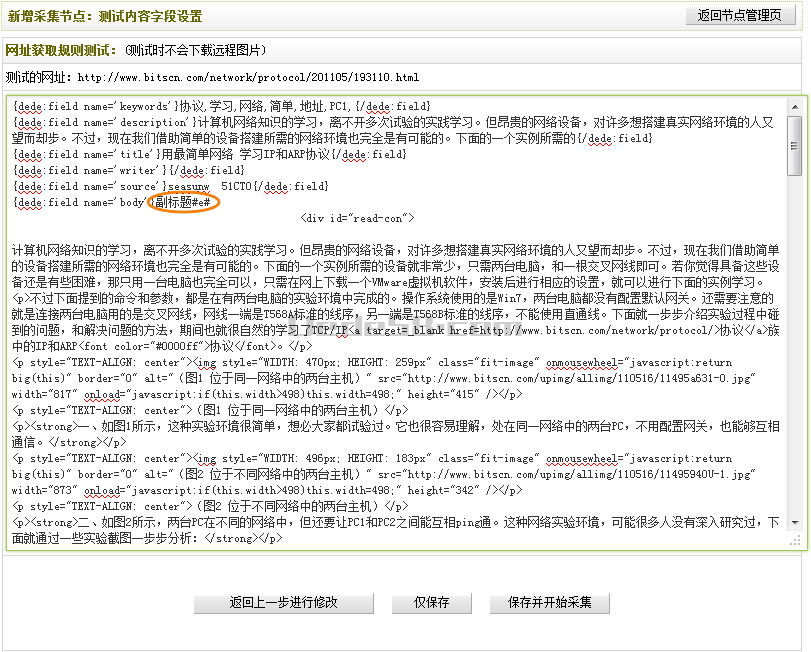
檢查無誤后,單擊“保存配置并預覽”。如果之前設置正確,單擊后,將會進入“新增采集節點:測試內容字段設置”頁面并看到相應的文章內容。如(圖27)和(圖28)所示,
(此圖片來源于網絡,如有侵權,請聯系刪除! )
圖27-新增采集節點:測試內容字段設置

(此圖片來源于網絡,如有侵權,請聯系刪除! )
圖28-新增采集節點:測試內容字段設置
其中,圖中畫圈的地方代表的是分頁符號。
確定正確無誤后,如果單擊“僅保存”,系統將會提示“成功保存配置“并返回”采集節點管理“界面;如果單擊“保存并開始采集“,將會進入”采集指定節點“界面。否則,請單擊“返回上一步進行修改”。
關于第二節的介紹就到這里。下面進入第三節。。。

| ? |
|
|
|
|||||||||||||||
| 全國咨詢熱線 | |||||||||||||||||
| 400-1100-266 | |||||||||||||||||
| 在線客服( QQ:340506921 ) | |||||||||||||||||