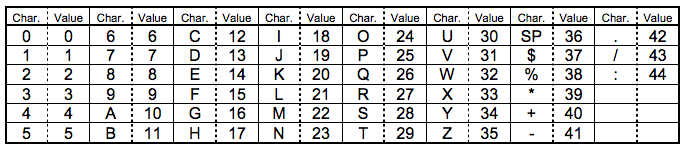
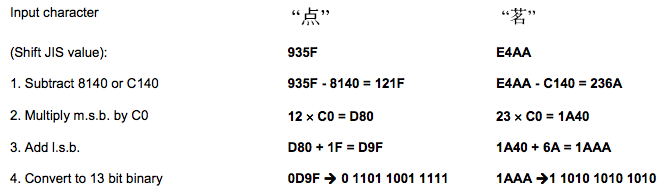
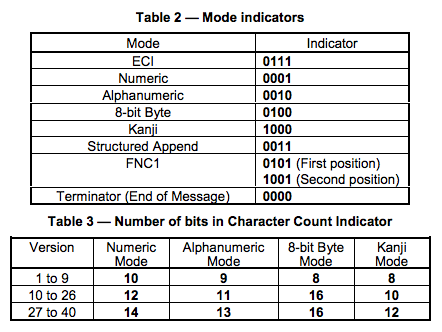
| 編碼 | 字符 | HELLO WORLD編碼 |
| 0010 | 000001011 | 01100001011 01111000110 10001011100 10110111000 10011010100 001101 |
我們還要加上結束符:
| 編碼 | 字符數 | HELLO WORLD編碼 | 結束 |
| 0010 | 000001011 | 01100001011 01111000110 10001011100 10110111000 10011010100 001101 | 0000 |
按8bits重排
如果所有的編碼加起來不是8個倍數我們還要在后面加上足夠的0,比如上面一共有78個bits,所以,我們還要加上2個0,然后按8個bits分好組:
00100000 01011011 00001011 01111000 11010001 01110010 11011100 01001101 01000011 01000000
補齊碼(Padding Bytes)
最后,如果如果還沒有達到我們最大的bits數的限制,我們還要加一些補齊碼(Padding Bytes),Padding Bytes就是重復下面的兩個bytes:11101100 00010001 (這兩個二進制轉成十進制是236和17,我也不知道為什么,只知道Spec上是這么寫的)關于每一個Version的每一種糾錯級別的最大Bits限制,可以參看QR Code Spec的第28頁到32頁的Table-7一表。
假設我們需要編碼的是Version 1的Q糾錯級,那么,其最大需要104個bits,而我們上面只有80個bits,所以,還需要補24個bits,也就是需要3個Padding Bytes,我們就添加三個,于是得到下面的編碼:
00100000 01011011 00001011 01111000 11010001 01110010 11011100 01001101 01000011 01000000 11101100 00010001 11101100
上面的編碼就是數據碼了,叫Data Codewords,每一個8bits叫一個codeword,我們還要對這些數據碼加上糾錯信息。
糾錯碼
上面我們說到了一些糾錯級別,Error Correction Code Level,二維碼中有四種級別的糾錯,這就是為什么二維碼有殘缺還能掃出來,也就是為什么有人在二維碼的中心位置加入圖標。
| 錯誤修正容量 | |
|---|---|
| L水平 | 7%的字碼可被修正 |
| M水平 | 15%的字碼可被修正 |
| Q水平 | 25%的字碼可被修正 |
| H水平 | 30%的字碼可被修正 |
那么,QR是怎么對數據碼加上糾錯碼的?首先,我們需要對數據碼進行分組,也就是分成不同的Block,然后對各個Block進行糾錯編碼,對于如何分組,我們可以查看QR Code Spec的第33頁到44頁的Table-13到Table-22的定義表。注意最后兩列:
Number of Error Code Correction Blocks :需要分多少個塊。
Error Correction Code Per Blocks:每一個塊中的code個數,所謂的code的個數,也就是有多少個8bits的字節。
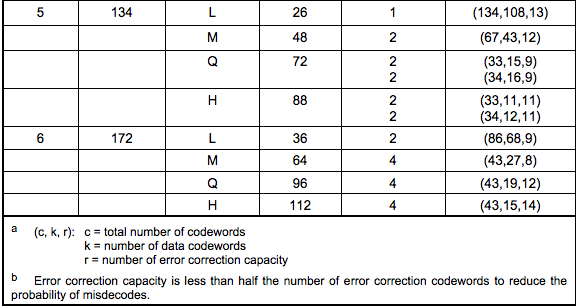
舉個例子:上述的Version 5 + Q糾錯級:需要4個Blocks(2個Blocks為一組,共兩組),頭一組的兩個Blocks中各15個bits數據 + 各 9個bits的糾錯碼(注:表中的codewords就是一個8bits的byte)(再注:最后一例中的(c, k, r )的公式為:c = k + 2 * r,因為后腳注解釋了:糾錯碼的容量小于糾錯碼的一半)
下圖給一個5-Q的示例(因為二進制寫起來會讓表格太大,所以,我都用了十進制,我們可以看到每一塊的糾錯碼有18個codewords,也就是18個8bits的二進制數)
| 組 | 塊 | 數據 | 對每個塊的糾錯碼 |
| 1 | 1 | 67 85 70 134 87 38 85 194 119 50 6 18 6 103 38 |
213 199 11 45 115 247 241 223 229 248 154 117 154 111 86 161 111 39 |
| 2 | 246 246 66 7 118 134 242 7 38 86 22 198 199 146 6 |
87 204 96 60 202 182 124 157 200 134 27 129 209 17 163 163 120 133 |
|
| 2 | 1 | 182 230 247 119 50 7 118 134 87 38 82 6 134 151 50 7 |
148 116 177 212 76 133 75 242 238 76 195 230 189 10 108 240 192 141 |
| 2 | 70 247 118 86 194 6 151 50 16 236 17 236 17 236 17 236 |
235 159 5 173 24 147 59 33 106 40 255 172 82 2 131 32 178 236 |
注:二維碼的糾錯碼主要是通過Reed-Solomon error correction(里德-所羅門糾錯算法)來實現的。對于這個算法,對于我來說是相當的復雜,里面有很多的數學計算,比如:多項式除法,把1-255的數映射成2的n次方(0=n=255)的伽羅瓦域Galois Field之類的神一樣的東西,以及基于這些基礎的糾錯數學公式,因為我的數據基礎差,對于我來說太過復雜,所以我一時半會兒還有點沒搞明白,還在學習中,所以,我在這里就不展開說這些東西了。還請大家見諒了。(當然,如果有朋友很明白,也繁請教教我)
最終編碼
穿插放置
如果你以為我們可以開始畫圖,你就錯了。二維碼的混亂技術還沒有玩完,它還要把數據碼和糾錯碼的各個codewords交替放在一起。如何交替呢,規則如下:
對于數據碼:把每個塊的第一個codewords先拿出來按順度排列好,然后再取第一塊的第二個,如此類推。如:上述示例中的Data Codewords如下:
| 塊1 | 67 | 85 | 70 | 134 | 87 | 38 | 85 | 194 | 119 | 50 | 6 | 18 | 6 | 103 | 38 | |
| 塊2 | 246 | 246 | 66 | 7 | 118 | 134 | 242 | 7 | 38 | 86 | 22 | 198 | 199 | 146 | 6 | |
| 塊3 | 182 | 230 | 247 | 119 | 50 | 7 | 118 | 134 | 87 | 38 | 82 | 6 | 134 | 151 | 50 | 7 |
| 塊4 | 70 | 247 | 118 | 86 | 194 | 6 | 151 | 50 | 16 | 236 | 17 | 236 | 17 | 236 | 17 | 236 |
我們先取第一列的:67, 246, 182, 70
然后再取第二列的:67, 246, 182, 70, 85,246,230 ,247
如此類推:67, 246, 182, 70, 85,246,230 ,247 ……… ……… ,38,6,50,17,7,236
對于糾錯碼,也是一樣:
| 塊1 | 213 | 199 | 11 | 45 | 115 | 247 | 241 | 223 | 229 | 248 | 154 | 117 | 154 | 111 | 86 | 168 | 111 | 39 |
| 塊2 | 87 | 204 | 96 | 60 | 202 | 182 | 124 | 157 | 200 | 134 | 27 | 129 | 209 | 17 | 163 | 163 | 120 | 133 |
| 塊3 | 148 | 116 | 177 | 212 | 76 | 133 | 75 | 242 | 238 | 76 | 195 | 230 | 189 | 10 | 108 | 240 | 192 | 141 |
| 塊4 | 235 | 159 | 5 | 173 | 24 | 147 | 59 | 33 | 106 | 40 | 255 | 172 | 82 | 2 | 131 | 32 | 178 | 236 |
和數據碼取的一樣,得到:213,87,148,235,199,204,116,159,…… …… 39,133,141,236
然后,再把這兩組放在一起(糾錯碼放在數據碼之后)得到:
67, 246, 182, 70, 85, 246, 230, 247, 70, 66, 247, 118, 134, 7, 119, 86, 87, 118, 50, 194, 38, 134, 7, 6, 85, 242, 118, 151, 194, 7, 134, 50, 119, 38, 87, 16, 50, 86, 38, 236, 6, 22, 82, 17, 18, 198, 6, 236, 6, 199, 134, 17, 103, 146, 151, 236, 38, 6, 50, 17, 7, 236, 213, 87, 148, 235, 199, 204, 116, 159, 11, 96, 177, 5, 45, 60, 212, 173, 115, 202, 76, 24, 247, 182, 133, 147, 241, 124, 75, 59, 223, 157, 242, 33, 229, 200, 238, 106, 248, 134, 76, 40, 154, 27, 195, 255, 117, 129, 230, 172, 154, 209, 189, 82, 111, 17, 10, 2, 86, 163, 108, 131, 161, 163, 240, 32, 111, 120, 192, 178, 39, 133, 141, 236
這就是我們的數據區。
Remainder Bits
最后再加上Reminder Bits,對于某些Version的QR,上面的還不夠長度,還要加上Remainder Bits,比如:上述的5Q版的二維碼,還要加上7個bits,Remainder Bits加零就好了。關于哪些Version需要多少個Remainder bit,可以參看QR Code Spec的第15頁的Table-1的定義表。
畫二維碼圖
Position Detection Pattern
首先,先把Position Detection圖案畫在三個角上。(無論Version如何,這個圖案的尺寸就是這么大)

Alignment Pattern
然后,再把Alignment圖案畫上(無論Version如何,這個圖案的尺寸就是這么大)

關于Alignment的位置,可以查看QR Code Spec的第81頁的Table-E.1的定義表(下表是不完全表格)

下圖是根據上述表格中的Version8的一個例子(6,24,42)
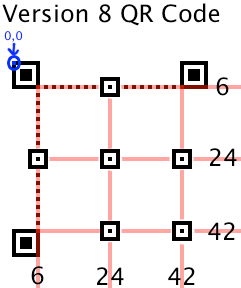
Timing Pattern
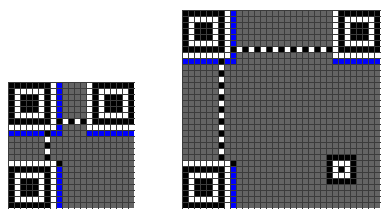
接下來是Timing Pattern的線(這個不用多說了)
Format Information
再接下來是Formation Information,下圖中的藍色部分。
Format Information是一個15個bits的信息,每一個bit的位置如下圖所示:(注意圖中的Dark Module,那是永遠出現的)
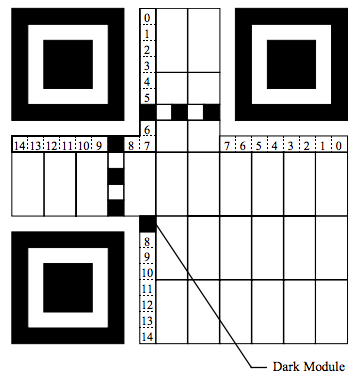
這15個bits中包括:
5個數據bits:其中,2個bits用于表示使用什么樣的Error Correction Level, 3個bits表示使用什么樣的Mask
10個糾錯bits。主要通過BCH Code來計算
然后15個bits還要與101010000010010做XOR操作。這樣就保證不會因為我們選用了00的糾錯級別和000的Mask,從而造成全部為白色,這會增加我們的掃描器的圖像識別的困難。
下面是一個示例:

關于Error Correction Level如下表所示:
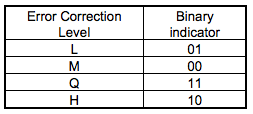
關于Mask圖案如后面的Table 23所示。
Version Information
再接下來是Version Information(版本7以后需要這個編碼),下圖中的藍色部分。
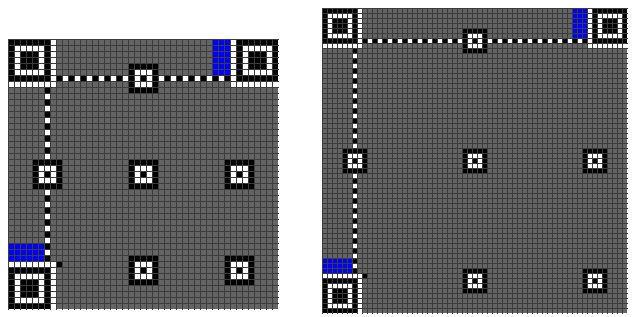
Version Information一共是18個bits,其中包括6個bits的版本號以及12個bits的糾錯碼,下面是一個示例:

而其填充位置如下:

數據和數據糾錯碼
然后是填接我們的最終編碼,最終編碼的填充方式如下:從左下角開始沿著紅線填我們的各個bits,1是黑色,0是白色。如果遇到了上面的非數據區,則繞開或跳過。

掩碼圖案
這樣下來,我們的圖就填好了,但是,也許那些點并不均衡,如果出現大面積的空白或黑塊,會告訴我們掃描識別的困難。所以,我們還要做Masking操作(靠,還嫌不復雜)QR的Spec中說了,QR有8個Mask你可以使用,如下所示:其中,各個mask的公式在各個圖下面。所謂mask,說白了,就是和上面生成的圖做XOR操作。Mask只會和數據區進行XOR,不會影響功能區。(注:選擇一個合適的Mask也是有算法的)

其Mask的標識碼如下所示:(其中的i,j分別對應于上圖的x,y)

下面是Mask后的一些樣子,我們可以看到被某些Mask XOR了的數據變得比較零散了。
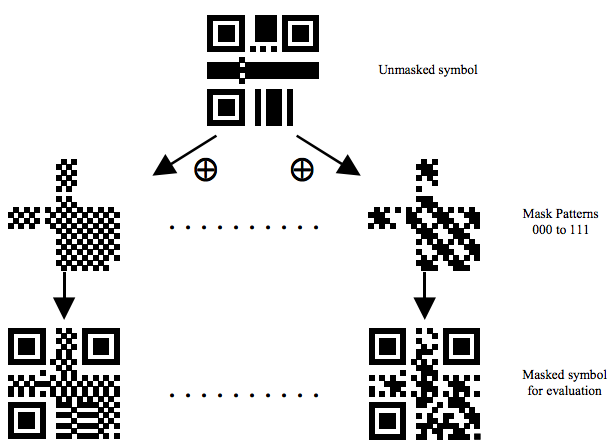
Mask過后的二維碼就成最終的圖了。
好了,大家可以去嘗試去寫一下QR的編碼程序,當然,你可以用網上找個Reed Soloman的糾錯算法的庫,或是看看別人的源代碼是怎么實現這個繁鎖的編碼。
(全文完)