1.綜述
又稱單詞查找樹,Trie樹,是一種樹形結構,是一種哈希樹的變種。典型應用是用于統計,排序和保存大量的字符串(但不僅限于字符串),所以經常被搜索引擎系統用于文本詞頻統計。
它的優點是:利用字符串的公共前綴來節約存儲空間,最大限度地減少無謂的字符串比較,查詢效率比哈希表高。
Trie樹結構的優點在于:
1) 不限制子節點的數量;
2) 自定義的輸入序列化,突破了具體語言、應用的限制,成為一個通用的框架;
3) 可以進行最大Tokens序列長度的限制;
4) 根據已定閾值輸出重復的字符串;
5) 提供單個字符串頻度查找功能;
6) 速度快,在兩分鐘內完成1998年1月份人民日報(19056行)的重復字符串抽取工作。
2.性質
它有3個基本性質:
1) 根節點不包含字符,除根節點外每一個節點都只包含一個字符。
2) 從根節點到某一節點,路徑上經過的字符連接起來,為該節點對應的字符串。
3) 每個節點的所有子節點包含的字符都不相同。
3.基本操作
其基本操作有:查找、插入和刪除,當然刪除操作比較少見.我在這里只是實現了對整個樹的刪除操作,至于單個word的刪除操作也很簡單.
4.實現方法
搜索字典項目的方法為:
(1) 從根結點開始一次搜索;
(2) 取得要查找關鍵詞的第一個字母,并根據該字母選擇對應的子樹并轉到該子樹繼續進行檢索;
(3) 在相應的子樹上,取得要查找關鍵詞的第二個字母,并進一步選擇對應的子樹進行檢索。
(4) 迭代過程……
(5) 在某個結點處,關鍵詞的所有字母已被取出,則讀取附在該結點上的信息,即完成查找。
其他操作類似處理
5. Trie原理——Trie的核心思想是空間換時間。利用字符串的公共前綴來降低查詢時間的開銷以達到提高效率的目的。
6.代碼實現
復制代碼 代碼如下:
const int branchNum = 26; //聲明常量
int i;
struct Trie_node
{
boolisStr; //記錄此處是否構成一個串。
Trie_node*next[branchNum];//指向各個子樹的指針,下標0-25代表26字符
Trie_node():isStr(false)
{
memset(next,NULL,sizeof(next));
}
};
class Trie
{
public:
Trie();
voidinsert(const char* word);
boolsearch(char* word);
voiddeleteTrie(Trie_node *root);
// voidprintTrie(Trie_node *root); //new add
private:
Trie_node* root;
};
Trie::Trie()
{
root =new Trie_node();
}
void Trie::insert(const char* word)
{
Trie_node*location = root;
while(*word)
{
if(location->next[*word-'a'] == NULL)//不存在則建立
{
Trie_node *tmp = new Trie_node();
location->next[*word-'a'] = tmp;
}
location = location->next[*word-'a']; //每插入一步,相當于有一個新串經過,指針要向下移動
word++;
}
location->isStr = true; //到達尾部,標記一個串
}
bool Trie::search(char *word)
{
Trie_node*location = root;
while(*word location)
{
location= location->next[*word-'a'];
word++;
}
return(location!=NULL location->isStr);
}
void Trie::deleteTrie(Trie_node *root)
{
for(i =0; i branchNum; i++)
{
if(root->next[i]!= NULL)
{
deleteTrie(root->next[i]);
}
}
deleteroot;
}
void main() //簡單測試
{
Trie t;
t.insert("a");
t.insert("abandon");
char * c= "abandoned";
t.insert(c);
t.insert("abashed");
if(t.search("abashed"))
{
printf("true\n"); //已經插入了
}
}
有時,我們會碰到對字符串的排序,若采用一些經典的排序算法,則時間復雜度一般為O(n*lgn),但若采用Trie樹,則時間復雜度僅為O(n)。
Trie樹又名字典樹,從字面意思即可理解,這種樹的結構像英文字典一樣,相鄰的單詞一般前綴相同,之所以時間復雜度低,是因為其采用了以空間換取時間的策略。
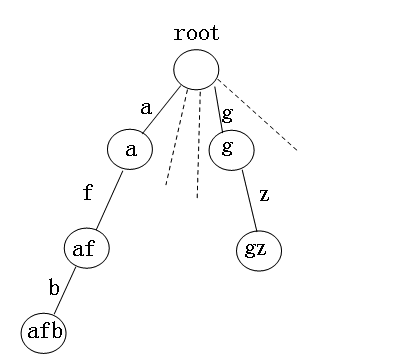
下圖為一個針對字符串排序的Trie樹(我們假設在這里字符串都是小寫字母),每個結點有26個分支,每個分支代表一個字母,結點存放的是從root節點到達此結點的路經上的字符組成的字符串。
將每個字符串插入到trie樹中,到達特定的結尾節點時,在這個節點上進行標記,如插入"afb",第一個字母為a,沿著a往下,然后第二個字母為f,沿著f往下,第三個為b,沿著b往下,由于字符串最后一個字符為'\0',因而結束,不再往下了,然后在這個節點上標記afb.count++,即其個數增加1.
之后,通過前序遍歷此樹,即可得到字符串從小到大的順序。
實現代碼如下(g++、VC++都編譯通過):
復制代碼 代碼如下:
#include iostream>
#include string.h>
using namespace std;
#define NUM 26
class Node
{
public:
int count; //記錄該處字符串個數
Node* char_arr[NUM]; //分支
char* current_str; //記錄到達此處的路徑上的所有字母組成的字符串
Node();
};
class Trie
{
public:
Node* root;
Trie();
void insert(char* str);
void output(Node* node, char** str, int count);
};
//程序未考慮delete動態內存
int main()
{
char** str = new char*[12];
str[0] = "zbdfasd";
str[1] = "zbcfd";
str[2] = "zbcdfdasfasf";
str[3] = "abcdaf";
str[4] = "defdasfa";
str[5] = "fedfasfd";
str[6] = "dfdfsa";
str[7] = "dadfd";
str[8] = "dfdfasf";
str[9] = "abcfdfa";
str[10] = "fbcdfd";
str[11] = "abcdaf";
//建立trie樹
Trie* trie = new Trie();
for(int i = 0; i 12; i++)
trie->insert(str[i]);
int count = 0;
trie->output(trie->root, str, count);
for(int i = 0; i 12; i++)
coutstr[i]endl;
return 0;
}
Node::Node()
{
count = 0;
for(int i = 0; i NUM; i++)
char_arr[i] = NULL;
current_str = new char[100];
current_str[0] = '\0';
}
Trie::Trie()
{
root = new Node();
}
void Trie::insert(char* str)
{
int i = 0;
Node* parent = root;
//將str[i]插入到trie樹中
while(str[i] != '\0')
{
//如果包含str[i]的分支存在,則新建此分支
if(parent->char_arr[str[i] - 'a'] == NULL)
{
parent->char_arr[str[i] - 'a'] = new Node();
//將父節點中的字符串添加到當前節點的字符串中
strcat(parent->char_arr[str[i] - 'a']->current_str, parent->current_str);
char str_tmp[2];
str_tmp[0] = str[i];
str_tmp[1] = '\0';
//將str[i]添加到當前節點的字符串中
strcat(parent->char_arr[str[i] - 'a']->current_str, str_tmp);
parent = parent->char_arr[str[i] - 'a'];
}
else
{
parent = parent->char_arr[str[i] - 'a'];
}
i++;
}
parent->count++;
}
//采用前序遍歷
void Trie::output(Node* node, char** str, int count)
{
if(node != NULL)
{
if(node->count != 0)
{
for(int i = 0; i node->count; i++)
str[count++] = node->current_str;
}
for(int i = 0; i NUM; i++)
{
output(node->char_arr[i], str, count);
}
}
}
您可能感興趣的文章:- Java中實現雙數組Trie樹實例
- Python Trie樹實現字典排序
- C# TrieTree介紹及實現方法
- TrieTree服務-組件構成及其作用介紹
- 詳解字典樹Trie結構及其Python代碼實現
- Trie樹(字典樹)的介紹及Java實現
