目錄
- 過擬合
- Regulation
- 動量
- 學習率遞減
- Early Stopping
- Dropout
過擬合
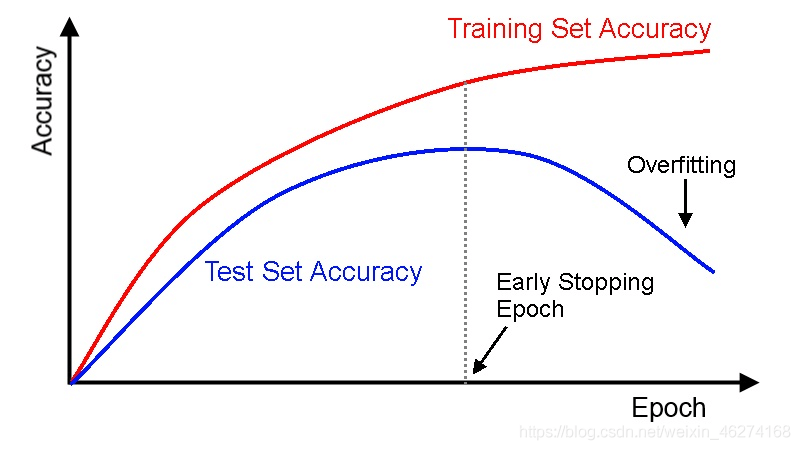
當訓練集的的準確率很高, 但是測試集的準確率很差的時候就, 我們就遇到了過擬合 (Overfitting) 的問題. 如圖:
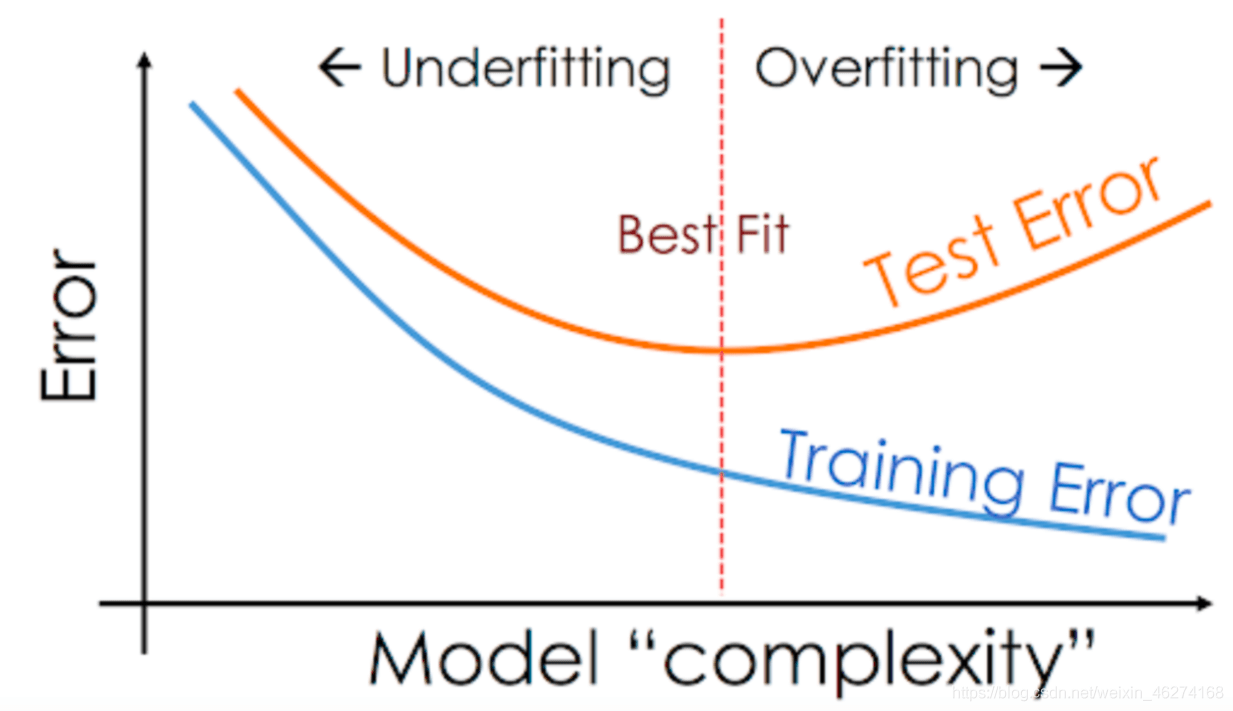
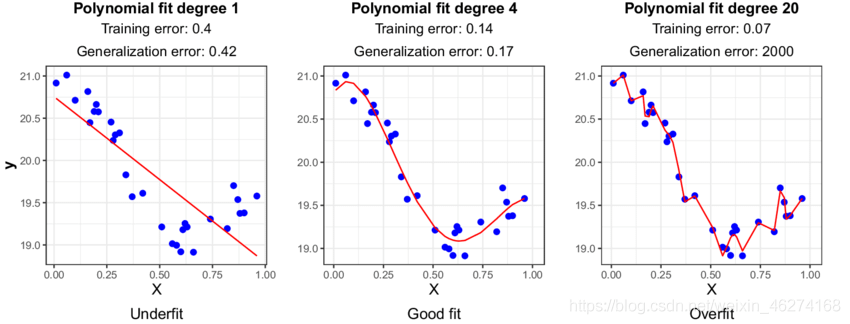
過擬合產生的一大原因是因為模型過于復雜. 下面我們將通過講述 5 種不同的方法來解決過擬合的問題, 從而提高模型準確度.
Regulation
Regulation 可以幫助我們通過約束要優化的參數來防止過擬合.
公式
未加入 regulation 的損失:
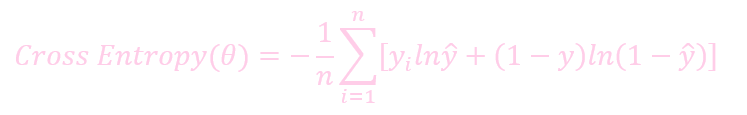
加入 regulation 的損失:
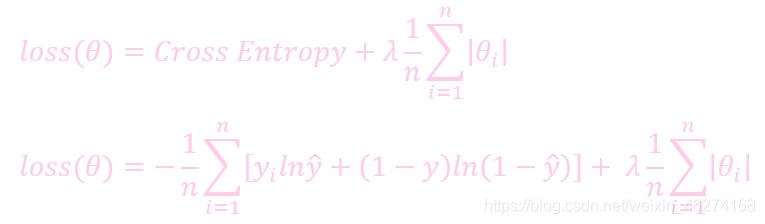
λ 和 lr (learning rate) 類似. 如果 λ 的值越大, regularion 的力度也就越強, 權重的值也就越小.
例子
添加了 l2 regulation 的網絡:
network = tf.keras.Sequential([
tf.keras.layers.Dense(256, kernel_regularizer=tf.keras.regularizers.l2(0.001), activation=tf.nn.relu),
tf.keras.layers.Dense(128, kernel_regularizer=tf.keras.regularizers.l2(0.001), activation=tf.nn.relu),
tf.keras.layers.Dense(64, kernel_regularizer=tf.keras.regularizers.l2(0.001), activation=tf.nn.relu),
tf.keras.layers.Dense(32, kernel_regularizer=tf.keras.regularizers.l2(0.001), activation=tf.nn.relu),
tf.keras.layers.Dense(10)
])
動量
動量 (Momentum) 是指運動物體的租用效果. 在梯度下降的過程中, 通過在優化器中加入動量, 我們可以減少擺動從而達到更優的效果.
未添加動量:

添加動量:

公式
未加動量的權重更新:
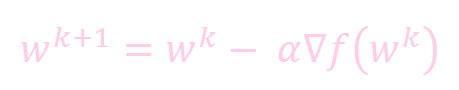
- w: 權重 (weight)
- k: 迭代的次數
- α: 學習率 (learning rate)
- ∇f(): 微分
添加動量的權重更新:
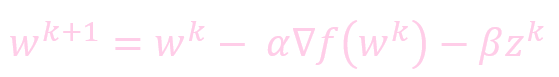
例子
添加了動量的優化器:
optimizer = tf.keras.optimizers.SGD(learning_rate=0.02, momentum=0.9)
optimizer = tf.keras.optimizers.RMSprop(learning_rate=0.02, momentum=0.9)
注: Adam 優化器默認已經添加動量, 所以無需自行添加.
學習率遞減
簡單的來說, 如果學習率越大, 我們訓練的速度就越大, 但找到最優解的概率也就越小. 反之, 學習率越小, 訓練的速度就越慢, 但找到最優解的概率就越大.
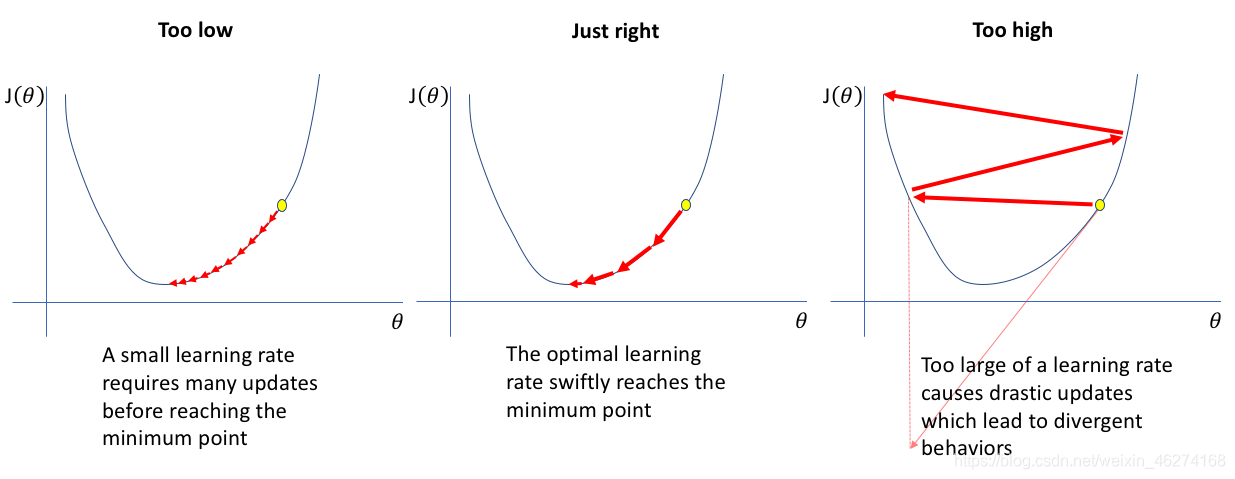
過程
我們可以在訓練初期把學習率調的稍大一些, 使得網絡迅速收斂. 在訓練后期學習率小一些, 使得我們能得到更好的收斂以獲得最優解. 如圖:
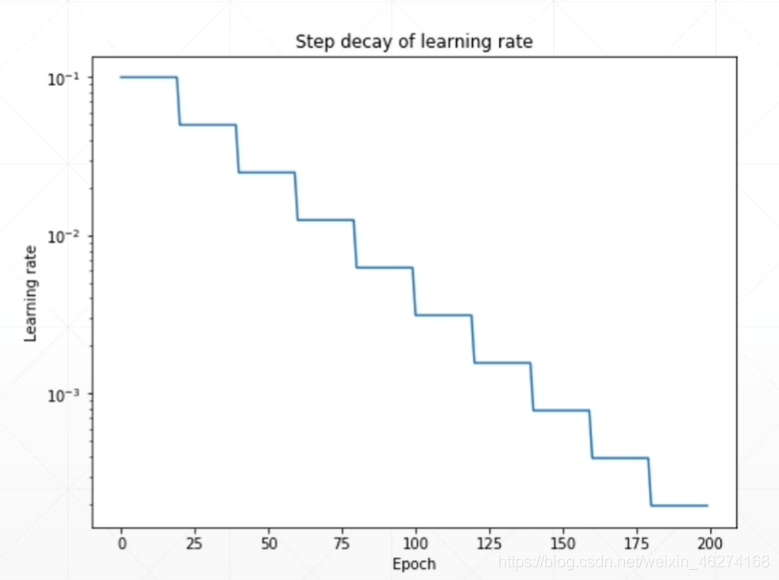
例子
learning_rate = 0.2 # 學習率
optimizer = tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=0.9) # 優化器
# 迭代
for epoch in range(iteration_num):
optimizer.learninig_rate = learning_rate * (100 - epoch) / 100 # 學習率遞減
Early Stopping
之前我們提到過, 當訓練集的準確率仍在提升, 但是測試集的準確率反而下降的時候, 我們就遇到了過擬合 (overfitting) 的問題.
Early Stopping 可以幫助我們在測試集的準確率下降的時候停止訓練, 從而避免繼續訓練導致的過擬合問題.
Dropout
Learning less to learn better
Dropout 會在每個訓練批次中忽略掉一部分的特征, 從而減少過擬合的現象.
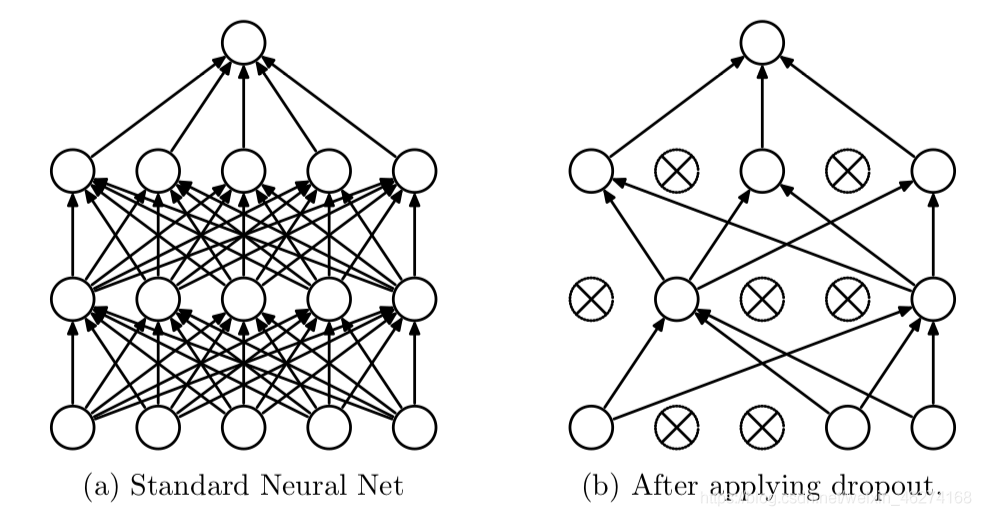
dropout, 通過強迫神經元, 和隨機跳出來的其他神經元共同工作, 達到好的效果. 消除減弱神經元節點間的聯合適應性, 增強了泛化能力.
例子:
network = tf.keras.Sequential([
tf.keras.layers.Dense(256, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.5), # 忽略一半
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.5), # 忽略一半
tf.keras.layers.Dense(64, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.5), # 忽略一半
tf.keras.layers.Dense(32, activation=tf.nn.relu),
tf.keras.layers.Dense(10)
])
到此這篇關于一小時學會TensorFlow2之大幅提高模型準確率的文章就介紹到這了,更多相關TensorFlow2模型準確率內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家�!
您可能感興趣的文章:- TensorFlow2.0使用keras訓練模型的實現
- 入門tensorflow教程之TensorBoard可視化模型訓練
- TensorFlow2.X使用圖片制作簡單的數據集訓練模型
- 如何將tensorflow訓練好的模型移植到Android (MNIST手寫數字識別)
