| 基本元素 | 說明 |
|---|---|
| Tag | 標簽,最基本的信息組織單元,分別用>和/>標明開頭和結尾 |
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
print(soup.title)
tag = soup.a
print(tag)
title>This is a python demo page/title> a >Basic Python/a>
任何存在于HTML語法中的標簽都可以用soup.訪問獲得。當HTML文檔中存在多個相同對應內容時,soup.返回第一個
| 基本元素 | 說明 |
|---|---|
| Name | 標簽的名字,
… 的名字是'p',格式:.name |
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
print(soup.a.name)
print(soup.a.parent.name)
print(soup.a.parent.parent.name)
a p body
| 基本元素 | 說明 |
|---|---|
| Attributes | 標簽的屬性,字典形式組織,格式:.attrs |
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
tag = soup.a
print(tag.attrs)
print(tag.attrs['class'])
print(tag.attrs['href'])
print(type(tag.attrs))
print(type(tag))
{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'}
['py1']
http://www.icourse163.org/course/BIT-268001
class 'dict'>
class 'bs4.element.Tag'>
Tag的NavigableString
| 基本元素 | 說明 |
|---|---|
| NavigableString | 標簽內非屬性字符串,>…/>中字符串,格式:.string |
| 基本元素 | 說明 |
|---|---|
| Comment | 標簽內字符串的注釋部分,一種特殊的Comment類型 |
import requests
from bs4 import BeautifulSoup
newsoup = BeautifulSoup("b>!--This is a comment-->/b>p>This is not a comment/p>","html.parser")
print(newsoup.b.string)
print(type(newsoup.b.string))
print(newsoup.p.string)
print(type(newsoup.p.string))
This is a comment class 'bs4.element.Comment'> This is not a comment class 'bs4.element.NavigableString'>
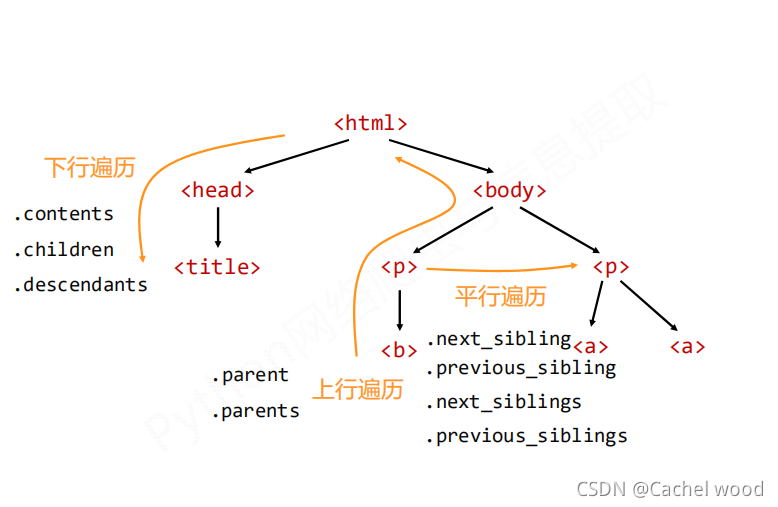
| 屬性 | 說明 |
|---|---|
| .contents | 子節點的列表,將所有兒子結點存入列表 |
| .children | 子節點的迭代類型,與.contents類似,用于循環遍歷兒子結點 |
| .descendents | 子孫節點的迭代類型,包含所有子孫節點,用于循環遍歷 |
BeautifulSoup類型是標簽樹的根節點
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
print(soup.head)
print(soup.head.contents)
print(soup.body.contents)
print(len(soup.body.contents))
print(soup.body.contents[1])
head>title>This is a python demo page/title>/head> [title>This is a python demo page/title>] ['\n', p >b>The demo python introduces several python courses./b>/p>, '\n', p >Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: a >Basic Python/a> and a >Advanced Python/a>./p>, '\n'] 5 p >b>The demo python introduces several python courses./b>/p>
for child in soup.body.children: print(child) #遍歷兒子結點 for child in soup.body.descendants: print(child) #遍歷子孫節點
| 屬性 | 說明 |
|---|---|
| .parent | 節點的父親標簽 |
| .parents | 節點先輩標簽的迭代類型,用于循環遍歷先輩節點 |
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
print(soup.title.parent)
print(soup.html.parent)
head>title>This is a python demo page/title>/head> html>head>title>This is a python demo page/title>/head> body> p >b>The demo python introduces several python courses./b>/p> p >Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: a >Basic Python/a> and a >Advanced Python/a>./p> /body>/html>
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)
p body html [document]
| 屬性 | 說明 |
|---|---|
| .next_sibling | 返回按照HTML文本順序的下一個平行節點標簽 |
| .previous.sibling | 返回按照HTML文本順序的上一個平行節點標簽 |
| .next_siblings | 迭代類型,返回按照HTML文本順序的后續所有平行節點標簽 |
| .previous.siblings | 迭代類型,返回按照HTML文本順序的前續所有平行節點標簽 |
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
print(soup.a.next_sibling)
print(soup.a.next_sibling.next_sibling)
print(soup.a.previous_sibling)
print(soup.a.previous_sibling.previous_sibling)
print(soup.a.parent)
and a class="py2" id="link2">Advanced Python/a> Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: None p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: a class="py1" id="link1">Basic Python/a> and a class="py2" id="link2">Advanced Python/a>./p>
for sibling in soup.a.next_sibling: print(sibling) #遍歷后續節點 for sibling in soup.a.previous_sibling: print(sibling) #遍歷前續節點
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
print(soup.prettify())
html>
head>
title>
This is a python demo page
/title>
/head>
body>
p class="title">
b>
The demo python introduces several python courses.
/b>
/p>
p class="course">
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
Basic Python
/a>
and
a class="py2" id="link2">
Advanced Python
/a>
.
/p>
/body>
/html>
.prettify()為HTML文本>及其內容增加更加'\n'
.prettify()可用于標簽,方法:.prettify()
bs4庫將任何HTML輸入都變成utf-8編碼
python 3.x默認支持編碼是utf-8,解析無障礙
import requests
from bs4 import BeautifulSoup
soup = BeautifulSoup("p>中文/p>","html.parser")
print(soup.p.string)
print(soup.p.prettify())
中文 p> 中文 /p>
到此這篇關于python beautiful soup庫入門安裝教程的文章就介紹到這了,更多相關python beautiful soup庫入門內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
標簽:銀川 葫蘆島 湘西 呼倫貝爾 安慶 呼倫貝爾 烏魯木齊 三亞
巨人網絡通訊聲明:本文標題《python beautiful soup庫入門安裝教程》,本文關鍵詞 python,beautiful,soup,庫,入門,;如發現本文內容存在版權問題,煩請提供相關信息告之我們,我們將及時溝通與處理。本站內容系統采集于網絡,涉及言論、版權與本站無關。