0514-86177077
9:00-17:00(工作日)
如下:
將html文件下載后,使用BeauifulSoup讀取文件,并且使用html.parser
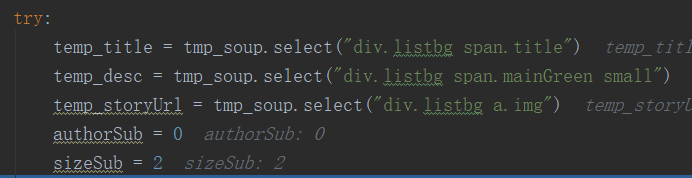
tmp_soup.select里面的參數為:
div標簽中class中帶有listbg 下面 span標簽中帶有title,這種意思:
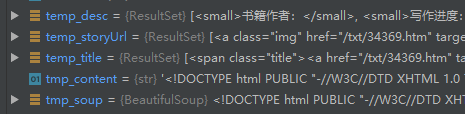
并且他們的類型如下:
都是ResultSet類型。
可以通過下面這種方式獲取,
find('某個標簽')['中包含的域']
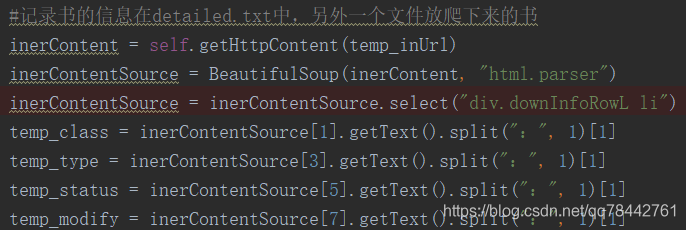
當為li標簽的時候,可以通過這樣的方式獲取:
到此這篇關于Python BeautifulSoup基本用法(通過標簽及class定位元素)的文章就介紹到這了,更多相關Python BeautifulSoup用法內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
標簽:呼倫貝爾 安慶 湘西 三亞 銀川 葫蘆島 呼倫貝爾 烏魯木齊
上一篇:python beautiful soup庫入門安裝教程
下一篇:pygame庫pgu使用示例代碼
Copyright ? 1999-2012 誠信 合法 規范的巨人網絡通訊始建于2005年
蘇ICP備15040257號-8