一、前言

二、爬取觀影數(shù)據(jù)
https://movie.douban.com/
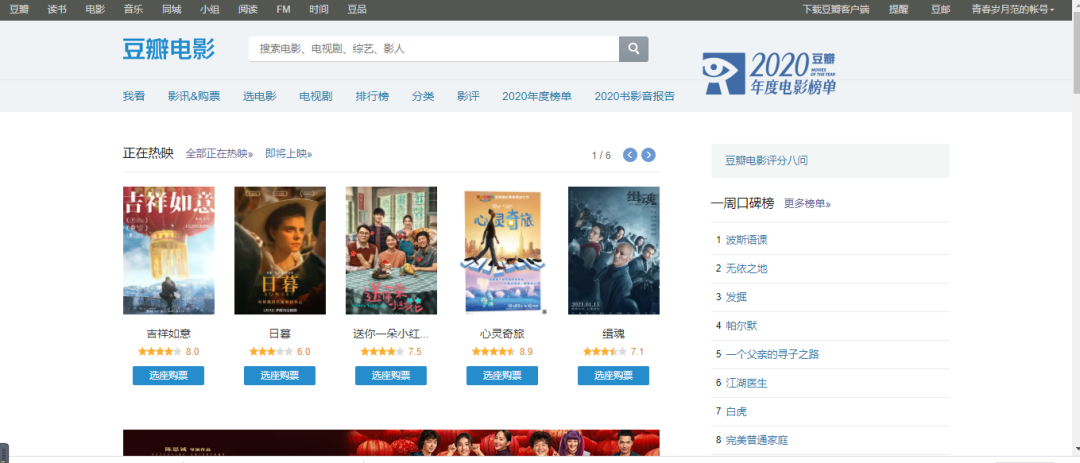
在『豆瓣』平臺(tái)爬取用戶觀影數(shù)據(jù)。
爬取用戶列表
網(wǎng)頁分析
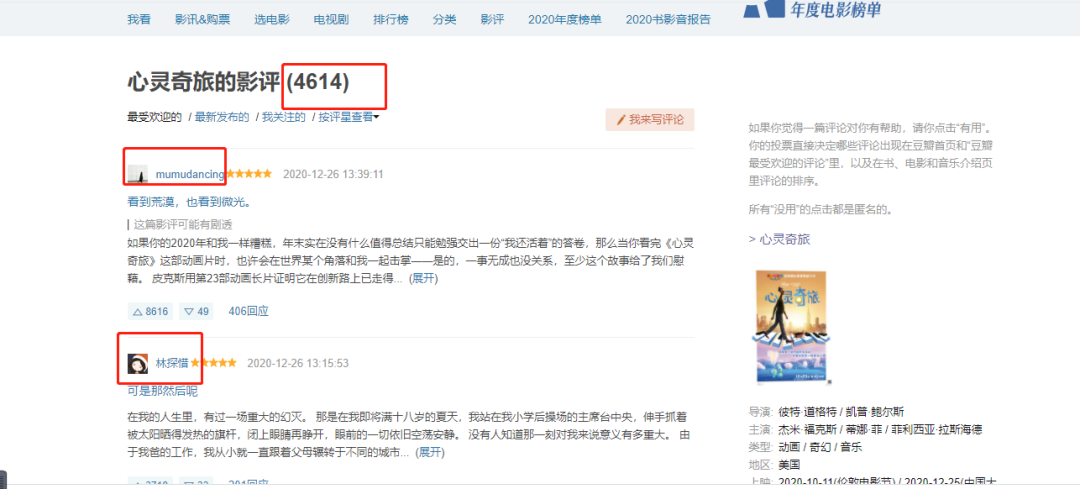
為了獲取用戶,我選擇了其中一部電影的影評(píng),這樣可以根據(jù)評(píng)論的用戶去獲取其用戶名稱(后面爬取用戶觀影記錄只需要『用戶名稱』)。
https://movie.douban.com/subject/24733428/reviews?start=0
url中start參數(shù)是頁數(shù)(page*20,每一頁20條數(shù)據(jù)),因此start=0、20、40...,也就是20的倍數(shù),通過改變start參數(shù)值就可以獲取這4614條用戶的名稱。

查看網(wǎng)頁的標(biāo)簽,可以找到『用戶名稱』值對應(yīng)的標(biāo)簽屬性。
編程實(shí)現(xiàn)
i=0
url = "https://movie.douban.com/subject/24733428/reviews?start=" + str(i * 20)
r = requests.get(url, headers=headers)
r.encoding = 'utf8'
s = (r.content)
selector = etree.HTML(s)
for item in selector.xpath('//*[@class="review-list "]/div'):
userid = (item.xpath('.//*[@class="main-hd"]/a[2]/@href'))[0].replace("https://www.douban.com/people/","").replace("/", "")
username = (item.xpath('.//*[@class="main-hd"]/a[2]/text()'))[0]
print(userid)
print(username)
print("-----")

爬取用戶的觀影記錄
上一步爬取到『用戶名稱』,接著爬取用戶觀影記錄需要用到『用戶名稱』。
網(wǎng)頁分析
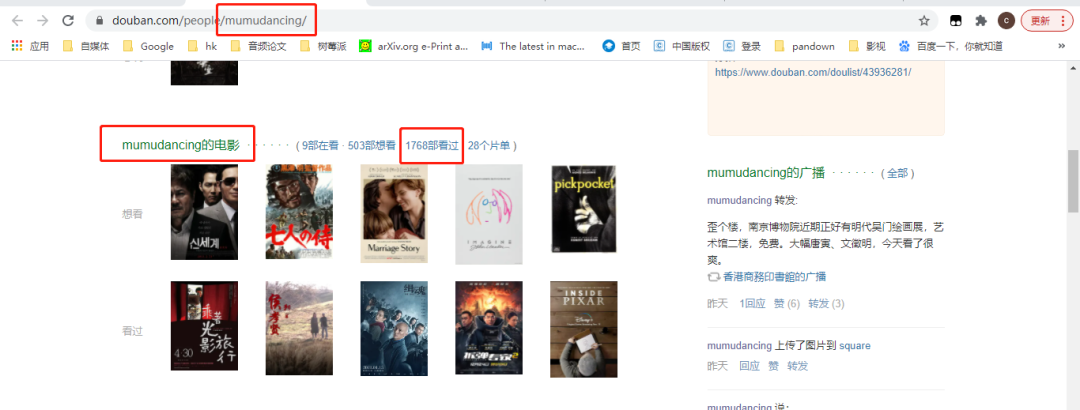
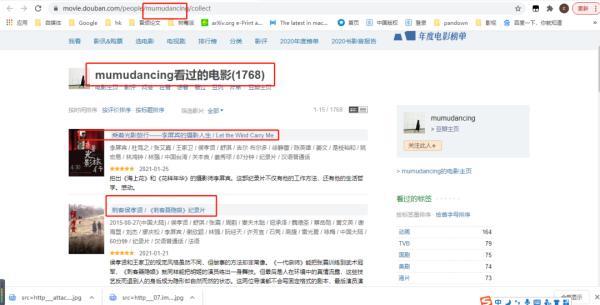
#https://movie.douban.com/people/{用戶名稱}/collect?start=15sort=timerating=allfilter=allmode=grid
https://movie.douban.com/people/mumudancing/collect?start=15sort=timerating=allfilter=allmode=grid
通過改變『用戶名稱』,可以獲取到不同用戶的觀影記錄。
url中start參數(shù)是頁數(shù)(page*15,每一頁15條數(shù)據(jù)),因此start=0、15、30...,也就是15的倍數(shù),通過改變start參數(shù)值就可以獲取這1768條觀影記錄稱。

查看網(wǎng)頁的標(biāo)簽,可以找到『電影名』值對應(yīng)的標(biāo)簽屬性。
編程實(shí)現(xiàn)
url = "https://movie.douban.com/people/mumudancing/collect?start=15sort=timerating=allfilter=allmode=grid"
r = requests.get(url, headers=headers)
r.encoding = 'utf8'
s = (r.content)
selector = etree.HTML(s)
for item in selector.xpath('//*[@class="grid-view"]/div[@class="item"]'):
text1 = item.xpath('.//*[@class="title"]/a/em/text()')
text2 = item.xpath('.//*[@class="title"]/a/text()')
text1 = (text1[0]).replace(" ", "")
text2 = (text2[1]).replace(" ", "").replace("\n", "")
print(text1+text1)
print("-----")
保存到excel
定義表頭
# 初始化execl表
def initexcel(filename):
# 創(chuàng)建一個(gè)workbook 設(shè)置編碼
workbook = xlwt.Workbook(encoding='utf-8')
# 創(chuàng)建一個(gè)worksheet
worksheet = workbook.add_sheet('sheet1')
workbook.save(str(filename)+'.xls')
##寫入表頭
value1 = [["用戶", "影評(píng)"]]
book_name_xls = str(filename)+'.xls'
write_excel_xls_append(book_name_xls, value1)
excel表有兩個(gè)標(biāo)題(用戶, 影評(píng))
寫入excel
# 寫入execl
def write_excel_xls_append(path, value):
index = len(value) # 獲取需要寫入數(shù)據(jù)的行數(shù)
workbook = xlrd.open_workbook(path) # 打開工作簿
sheets = workbook.sheet_names() # 獲取工作簿中的所有表格
worksheet = workbook.sheet_by_name(sheets[0]) # 獲取工作簿中所有表格中的的第一個(gè)表格
rows_old = worksheet.nrows # 獲取表格中已存在的數(shù)據(jù)的行數(shù)
new_workbook = copy(workbook) # 將xlrd對象拷貝轉(zhuǎn)化為xlwt對象
new_worksheet = new_workbook.get_sheet(0) # 獲取轉(zhuǎn)化后工作簿中的第一個(gè)表格
for i in range(0, index):
for j in range(0, len(value[i])):
new_worksheet.write(i+rows_old, j, value[i][j]) # 追加寫入數(shù)據(jù),注意是從i+rows_old行開始寫入
new_workbook.save(path) # 保存工作簿
定義了寫入excel函數(shù),這樣爬起每一頁數(shù)據(jù)時(shí)候調(diào)用寫入函數(shù)將數(shù)據(jù)保存到excel中。
最后采集了44130條數(shù)據(jù)(原本是4614個(gè)用戶,每個(gè)用戶大約有500~1000條數(shù)據(jù),預(yù)計(jì)400萬條數(shù)據(jù))。但是為了演示分析過程,只爬取每一個(gè)用戶的前30條觀影記錄(因?yàn)榍?0條是最新的)。
最后這44130條數(shù)據(jù)會(huì)在下面分享給大家。
三、數(shù)據(jù)分析挖掘
讀取數(shù)據(jù)集
def read_excel():
# 打開workbook
data = xlrd.open_workbook('豆瓣.xls')
# 獲取sheet頁
table = data.sheet_by_name('sheet1')
# 已有內(nèi)容的行數(shù)和列數(shù)
nrows = table.nrows
datalist=[]
for row in range(nrows):
temp_list = table.row_values(row)
if temp_list[0] != "用戶" and temp_list[1] != "影評(píng)":
data = []
data.append([str(temp_list[0]), str(temp_list[1])])
datalist.append(data)
return datalist

從豆瓣.xls中讀取全部數(shù)據(jù)放到datalist集合中。
分析1:電影觀看次數(shù)排行
###分析1:電影觀看次數(shù)排行
def analysis1():
dict ={}
###從excel讀取數(shù)據(jù)
movie_data = read_excel()
for i in range(0, len(movie_data)):
key = str(movie_data[i][0][1])
try:
dict[key] = dict[key] +1
except:
dict[key]=1
###從小到大排序
dict = sorted(dict.items(), key=lambda kv: (kv[1], kv[0]))
name=[]
num=[]
for i in range(len(dict)-1,len(dict)-16,-1):
print(dict[i])
name.append(((dict[i][0]).split("/"))[0])
num.append(dict[i][1])
plt.figure(figsize=(16, 9))
plt.title('電影觀看次數(shù)排行(高->低)')
plt.bar(name, num, facecolor='lightskyblue', edgecolor='white')
plt.savefig('電影觀看次數(shù)排行.png')
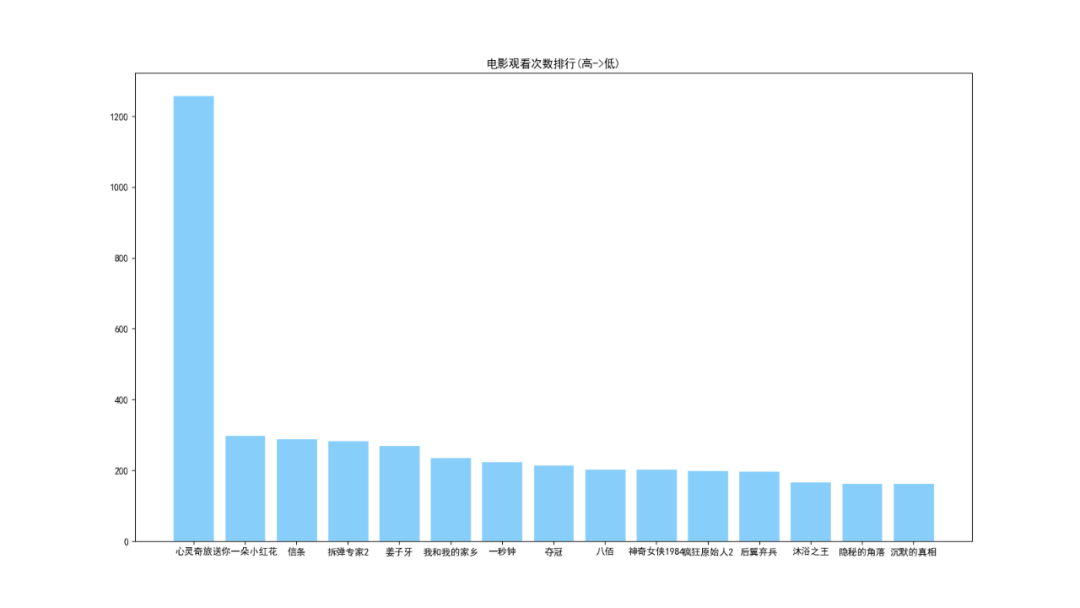
分析由于用戶信息來源于 『心靈奇旅』 評(píng)論,因此其用戶觀看量最大。最近的熱播電影中,播放量排在第二的是 『送你一朵小紅花』,信條和拆彈專家2也緊跟其后。
分析2:用戶畫像(用戶觀影相同率最高)
###分析2:用戶畫像(用戶觀影相同率最高)
def analysis2():
dict = {}
###從excel讀取數(shù)據(jù)
movie_data = read_excel()
userlist=[]
for i in range(0, len(movie_data)):
user = str(movie_data[i][0][0])
moive = (str(movie_data[i][0][1]).split("/"))[0]
#print(user)
#print(moive)
try:
dict[user] = dict[user]+","+str(moive)
except:
dict[user] =str(moive)
userlist.append(user)
num_dict={}
# 待畫像用戶(取第一個(gè))
flag_user=userlist[0]
movies = (dict[flag_user]).split(",")
for i in range(0,len(userlist)):
#判斷是否是待畫像用戶
if flag_user != userlist[i]:
num_dict[userlist[i]]=0
#待畫像用戶的所有電影
for j in range(0,len(movies)):
#判斷當(dāng)前用戶與待畫像用戶共同電影個(gè)數(shù)
if movies[j] in dict[userlist[i]]:
# 相同加1
num_dict[userlist[i]] = num_dict[userlist[i]]+1
###從小到大排序
num_dict = sorted(num_dict.items(), key=lambda kv: (kv[1], kv[0]))
#用戶名稱
username = []
#觀看相同電影次數(shù)
num = []
for i in range(len(num_dict) - 1, len(num_dict) - 9, -1):
username.append(num_dict[i][0])
num.append(num_dict[i][1])
plt.figure(figsize=(25, 9))
plt.title('用戶畫像(用戶觀影相同率最高)')
plt.scatter(username, num, color='r')
plt.plot(username, num)
plt.savefig('用戶畫像(用戶觀影相同率最高).png')
分析
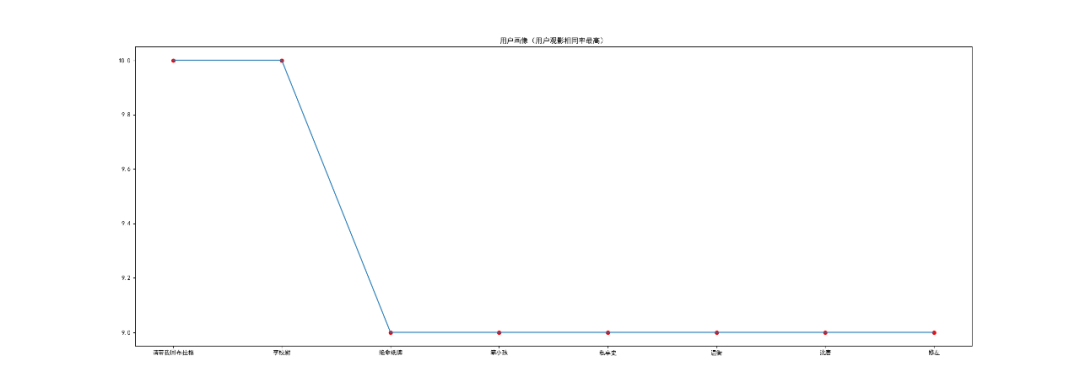
以用戶 『mumudancing』 為例進(jìn)行用戶畫像
1.從圖中可以看出,與用戶 『mumudancing』 觀影相同率最高的是:“請帶我回布拉格”,其次是“李校尉”。
2.用戶:'絕命紙牌', '笨小孩', '私享史', '溫衡', '沈唐', '修左',的觀影相同率****相同。
分析3:用戶之間進(jìn)行電影推薦
###分析3:用戶之間進(jìn)行電影推薦(與其他用戶同時(shí)被觀看過)
def analysis3():
dict = {}
###從excel讀取數(shù)據(jù)
movie_data = read_excel()
userlist=[]
for i in range(0, len(movie_data)):
user = str(movie_data[i][0][0])
moive = (str(movie_data[i][0][1]).split("/"))[0]
#print(user)
#print(moive)
try:
dict[user] = dict[user]+","+str(moive)
except:
dict[user] =str(moive)
userlist.append(user)
num_dict={}
# 待畫像用戶(取第2個(gè))
flag_user=userlist[0]
print(flag_user)
movies = (dict[flag_user]).split(",")
for i in range(0,len(userlist)):
#判斷是否是待畫像用戶
if flag_user != userlist[i]:
num_dict[userlist[i]]=0
#待畫像用戶的所有電影
for j in range(0,len(movies)):
#判斷當(dāng)前用戶與待畫像用戶共同電影個(gè)數(shù)
if movies[j] in dict[userlist[i]]:
# 相同加1
num_dict[userlist[i]] = num_dict[userlist[i]]+1
###從小到大排序
num_dict = sorted(num_dict.items(), key=lambda kv: (kv[1], kv[0]))
# 去重(用戶與觀影率最高的用戶兩者之間重復(fù)的電影去掉)
user_movies = dict[flag_user]
new_movies = dict[num_dict[len(num_dict)-1][0]].split(",")
for i in range(0,len(new_movies)):
if new_movies[i] not in user_movies:
print("給用戶("+str(flag_user)+")推薦電影:"+str(new_movies[i]))

分析
以用戶 『mumudancing』 為例,對用戶之間進(jìn)行電影推薦
1.根據(jù)與用戶 『mumudancing』 觀影率最高的用戶(A)進(jìn)行進(jìn)行關(guān)聯(lián),然后獲取用戶(A)的全部觀影記錄
2.將用戶(A)的觀影記錄推薦給用戶 『mumudancing』(去掉兩者之間重復(fù)的電影)。
分析4:電影之間進(jìn)行電影推薦
###分析4:電影之間進(jìn)行電影推薦(與其他電影同時(shí)被觀看過)
def analysis4():
dict = {}
###從excel讀取數(shù)據(jù)
movie_data = read_excel()
userlist=[]
for i in range(0, len(movie_data)):
user = str(movie_data[i][0][0])
moive = (str(movie_data[i][0][1]).split("/"))[0]
try:
dict[user] = dict[user]+","+str(moive)
except:
dict[user] =str(moive)
userlist.append(user)
movie_list=[]
# 待獲取推薦的電影
flag_movie = "送你一朵小紅花"
for i in range(0,len(userlist)):
if flag_movie in dict[userlist[i]]:
moives = dict[userlist[i]].split(",")
for j in range(0,len(moives)):
if moives[j] != flag_movie:
movie_list.append(moives[j])
data_dict = {}
for key in movie_list:
data_dict[key] = data_dict.get(key, 0) + 1
###從小到大排序
data_dict = sorted(data_dict.items(), key=lambda kv: (kv[1], kv[0]))
for i in range(len(data_dict) - 1, len(data_dict) -16, -1):
print("根據(jù)電影"+str(flag_movie)+"]推薦:"+str(data_dict[i][0]))
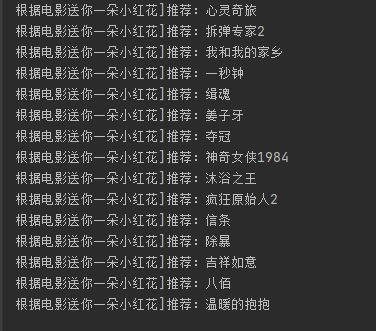
分析
以電影 『送你一朵小紅花』 為例,對電影之間進(jìn)行電影推薦
1.獲取觀看過 『送你一朵小紅花』 的所有用戶,接著獲取這些用戶各自的觀影記錄。
2.將這些觀影記錄進(jìn)行統(tǒng)計(jì)匯總(去掉“送你一朵小紅花”),然后進(jìn)行從高到低進(jìn)行排序,最后可以獲取到與電影 『送你一朵小紅花』 關(guān)聯(lián)度最高排序的集合。
3.將關(guān)聯(lián)度最高的前15部電影給用戶推薦。
四、總結(jié)
1.分析爬取豆瓣平臺(tái)數(shù)據(jù)思路,并編程實(shí)現(xiàn)。
2.對爬取的數(shù)據(jù)進(jìn)行分析(電影觀看次數(shù)排行、用戶畫像、用戶之間進(jìn)行電影推薦、電影之間進(jìn)行電影推薦)
到此這篇關(guān)于Python爬取用戶觀影數(shù)據(jù)并分析用戶與電影之間的隱藏信息!的文章就介紹到這了,更多相關(guān)Python爬取數(shù)據(jù)并分析內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- python爬蟲之Appium爬取手機(jī)App數(shù)據(jù)及模擬用戶手勢
- Python中Cookies導(dǎo)出某站用戶數(shù)據(jù)的方法
- Python編寫檢測數(shù)據(jù)庫SA用戶的方法
- 如何用Python數(shù)據(jù)可視化來分析用戶留存率
