1.什么是多線程?
多線程是為了同步完成多項任務,不是為了提高運行效率,而是為了提高資源使用效率來提高系統的效率。線程是在同一時間需要完成多項任務的時候實現的。
為什么要使用多線程
線程在程序中是獨立的、并發的執行流。與分隔的進程相比,進程中線程之間的隔離程度要小,它們共享內存、文件句柄和其他進程應有的狀態。
因為線程的劃分尺度小于進程,使得多線程程序的并發性高。進程在執行過程中擁有獨立的內存單元,而多個線程共享內存,從而極大地提高了程序的運行效率。
線程比進程具有更高的性能,這是由于同一個進程中的線程都有共性多個線程共享同一個進程的虛擬空間。線程共享的環境包括進程代碼段、進程的公有數據等,利用這些共享的數據,線程之間很容易實現通信。
操作系統在創建進程時,必須為該進程分配獨立的內存空間,并分配大量的相關資源,但創建線程則簡單得多。因此,使用多線程來實現并發比使用多進程的性能要高得多。
總結起來,使用多線程編程具有如下幾個優點:
進程之間不能共享內存,但線程之間共享內存非常容易。
操作系統在創建進程時,需要為該進程重新分配系統資源,但創建線程的代價則小得多。因此,使用多線程來實現多任務并發執行比使用多進程的效率高。
Python 語言內置了多線程功能支持,而不是單純地作為底層操作系統的調度方式,從而簡化了 Python 的多線程編程。
2.原理
實現多線程是采用一種并發執行機制 。
并發執行機制原理:簡單地說就是把一個處理器劃分為若干個短的時間片,每個時間片依次輪流地執行處理各個應用程序,由于一個時間片很短,相對于一個應用程序來說,就好像是處理器在為自己單獨服務一樣,從而達到多個應用程序在同時進行的效果 。
多線程就是把操作系統中的這種并發執行機制原理運用在一個程序中,把一個程序劃分為若干個子任務,多個子任務并發執行,每一個任務就是一個線程。這就是多線程程序 。

3.優點
1、使用線程可以把占據時間長的程序中的任務放到后臺去處理 。
2、用戶界面可以更加吸引人,這樣比如用戶點擊了一個按鈕去觸發某些事件的處理,可以彈出一個進度條來顯示處理的進度。
3、程序的運行速度可能加快 。
4、在一些等待的任務實現上如用戶輸入、文件讀寫和網絡收發數據等,線程就比較有用了。在這種情況下可以釋放一些珍貴的資源如內存占用等 。
5、多線程技術在IOS軟件開發中也有舉足輕重的作用。
4.缺點
1、如果有大量的線程,會影響性能,因為操作系統需要在它們之間切換。
2、更多的線程需要更多的內存空間。
3、線程可能會給程序帶來更多“bug”,因此要小心使用。
4、線程的中止需要考慮其對程序運行的影響。
5、通常塊模型數據是在多個線程間共享的,需要防止線程死鎖情況的發生。
好的廢話不多說,我們直接來實戰吧
1.進入英雄聯盟官網點擊游戲資料進入此畫面
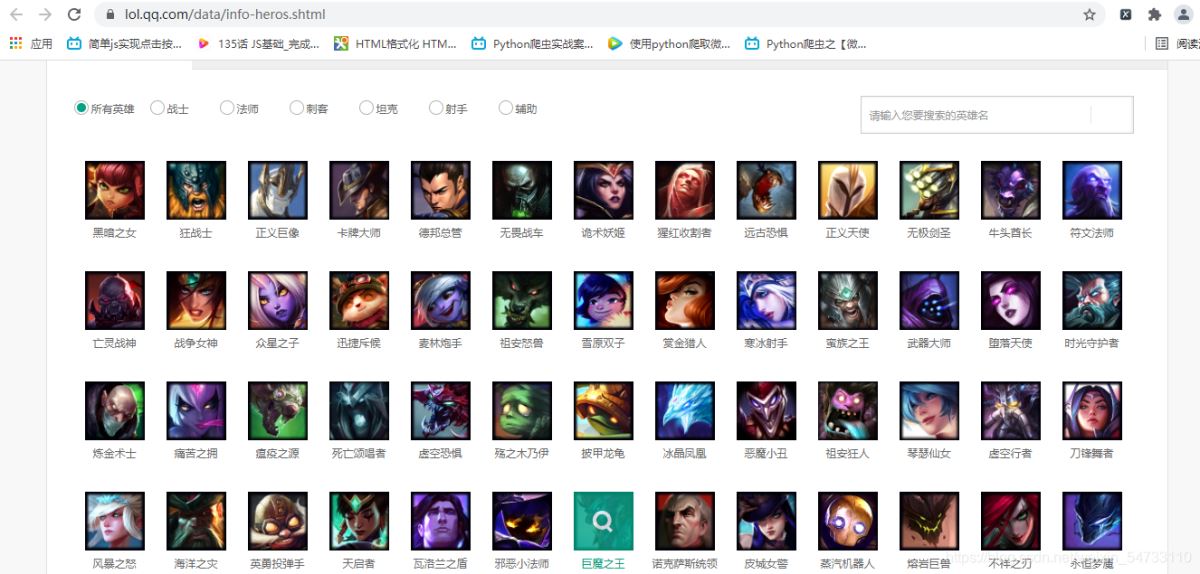
2.確定爬取的網頁是同步加載還是異步加載
1.鼠標右鍵打開網頁源代碼
2.ctrl+f打開搜索框
3.在搜索框了輸入英雄的名字
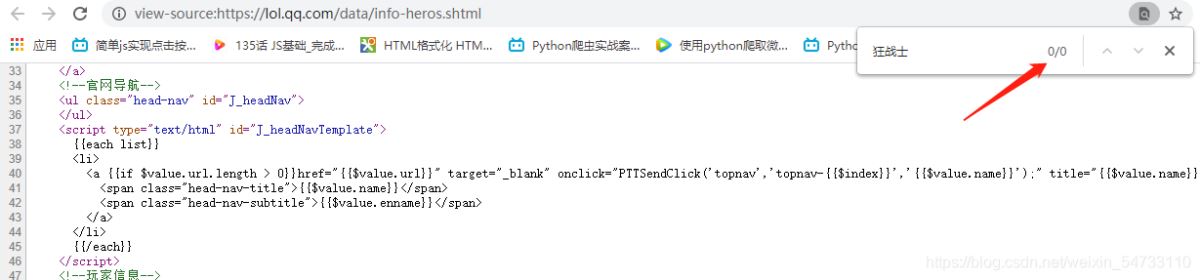
沒有搜索結果則為異步加載 3.尋找英雄url地址
回到英雄頁面鼠標右擊打開檢查。
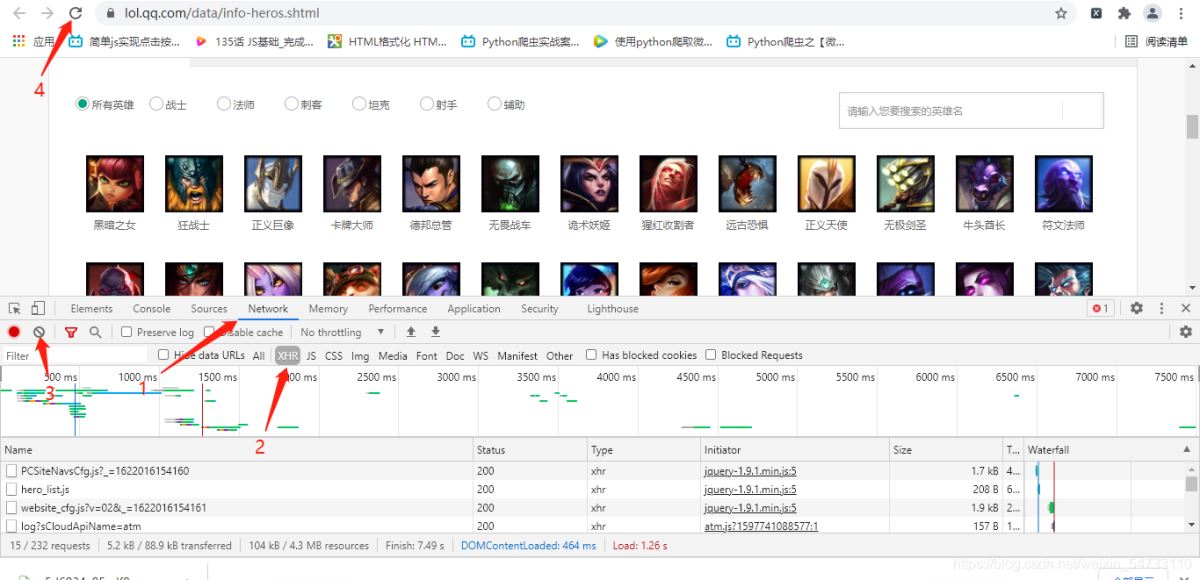
在獲取的包中找到hero_list.js這個包 英語翻譯過來英雄列表.js文件
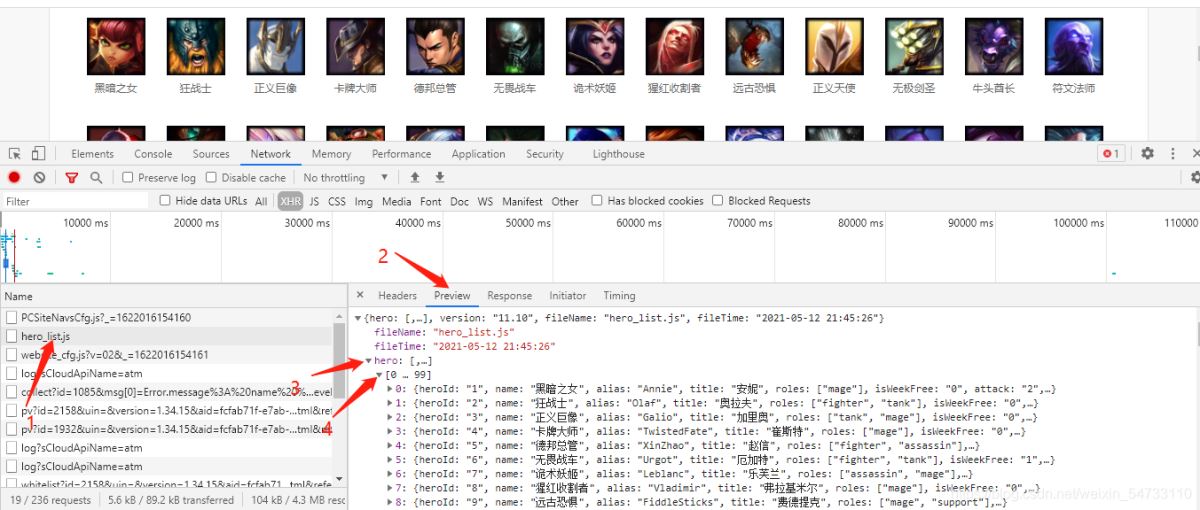
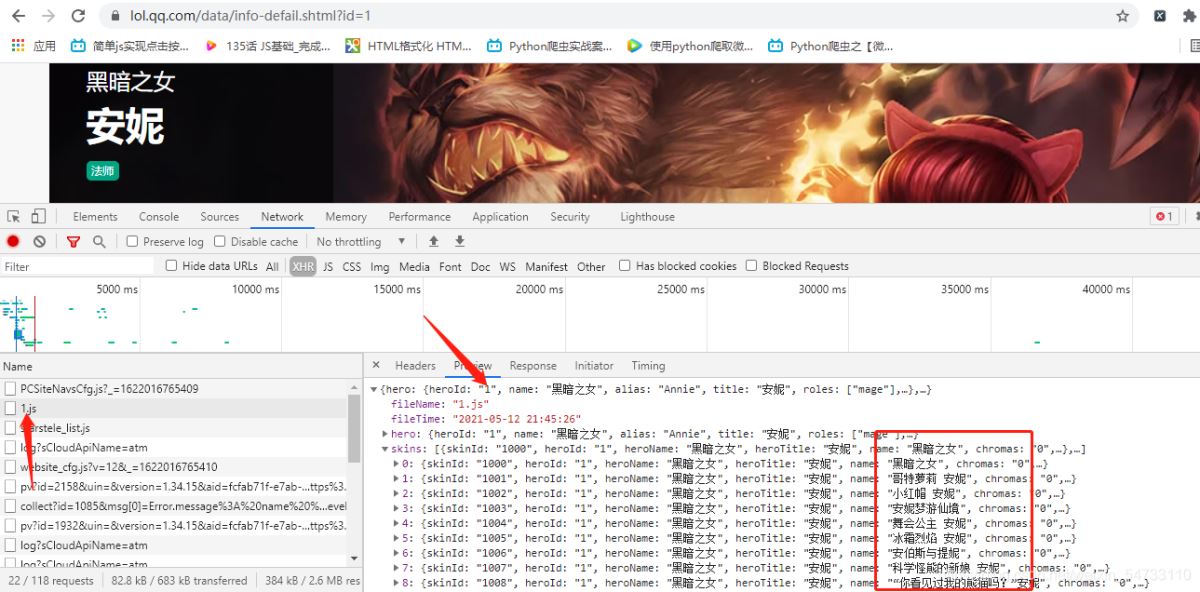
點擊網頁上英雄安妮拿回地址再點擊其他英雄拿回地址做比較。
安妮:
狂戰士:
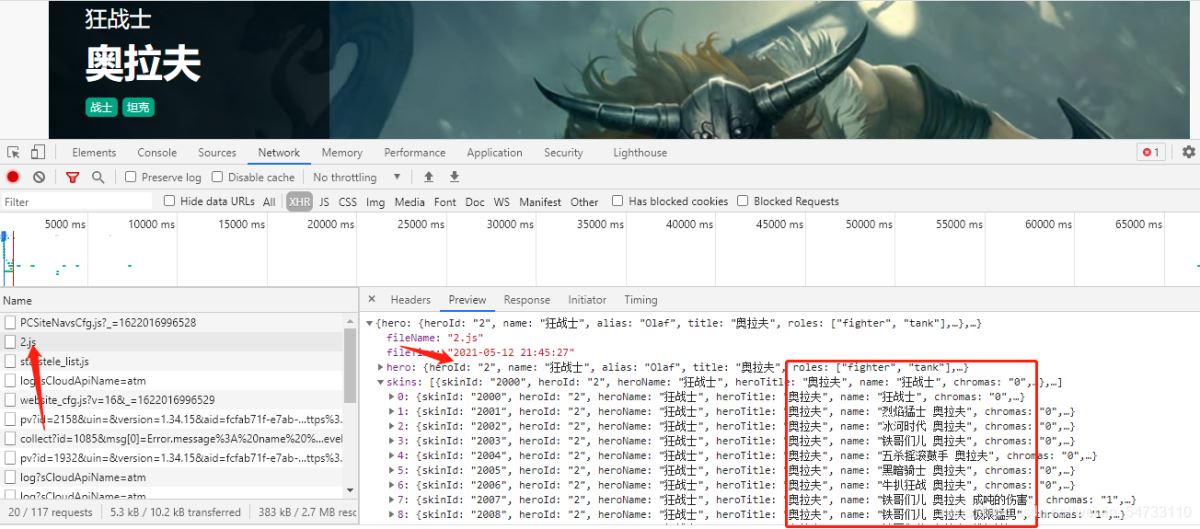
點擊headers拿回resquests url
安妮:https://game.gtimg.cn/images/lol/act/img/js/hero/1.js
狂戰士:https://game.gtimg.cn/images/lol/act/img/js/hero/2.js
可以發現變化在最后面 是英雄的id 這樣我們有思路了
1.第一次發送請求,拿回所有英雄的id和名字
2.第二次請求,得到英雄皮膚名,英雄手機皮膚url, 英雄電腦皮膚url
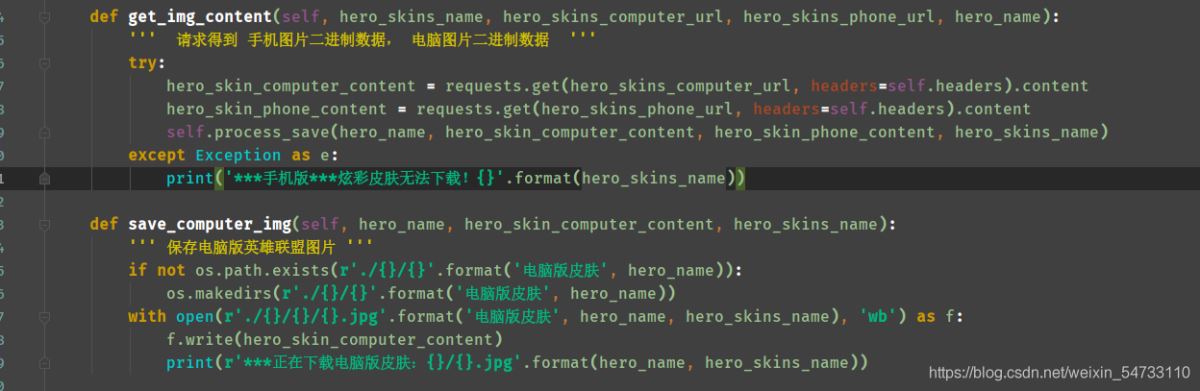
3.請求得到 手機圖片二進制數據, 電腦圖片二進制數據
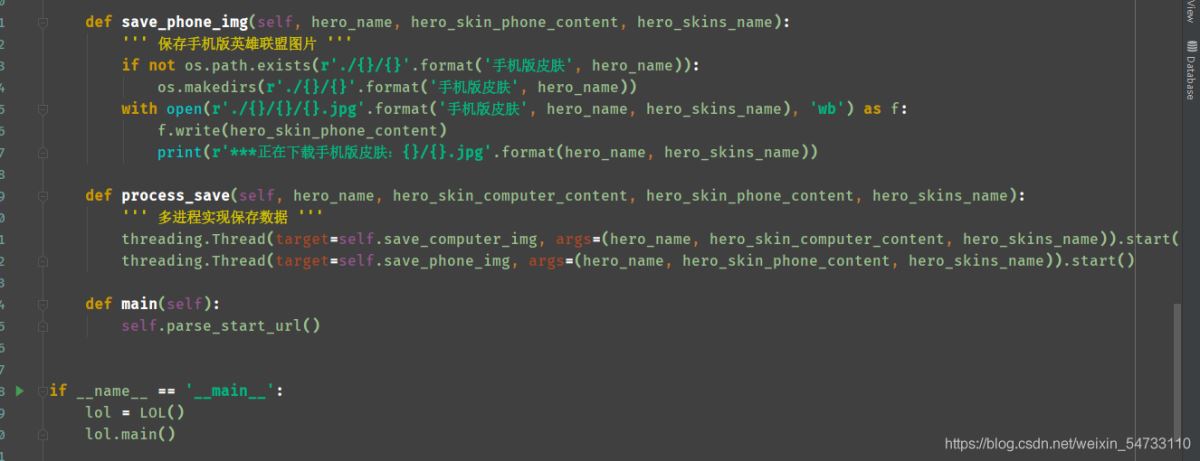
4.保存電腦版英雄聯盟圖片,保存手機版英雄聯盟圖片
5.多進程實現保存數據
是時候寫一點代碼了。。。嘿嘿
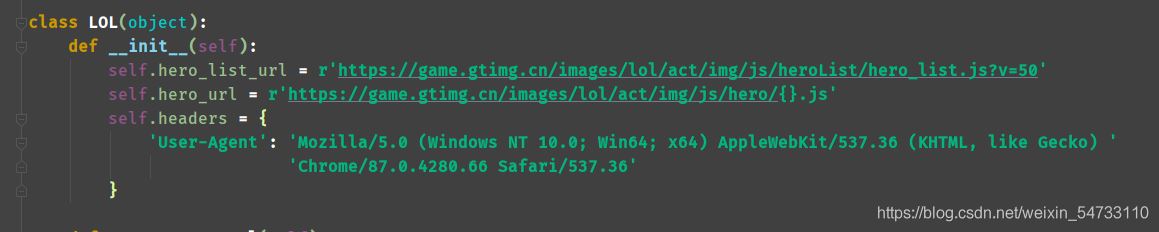
起始地址弄成全局變量
觀察網頁
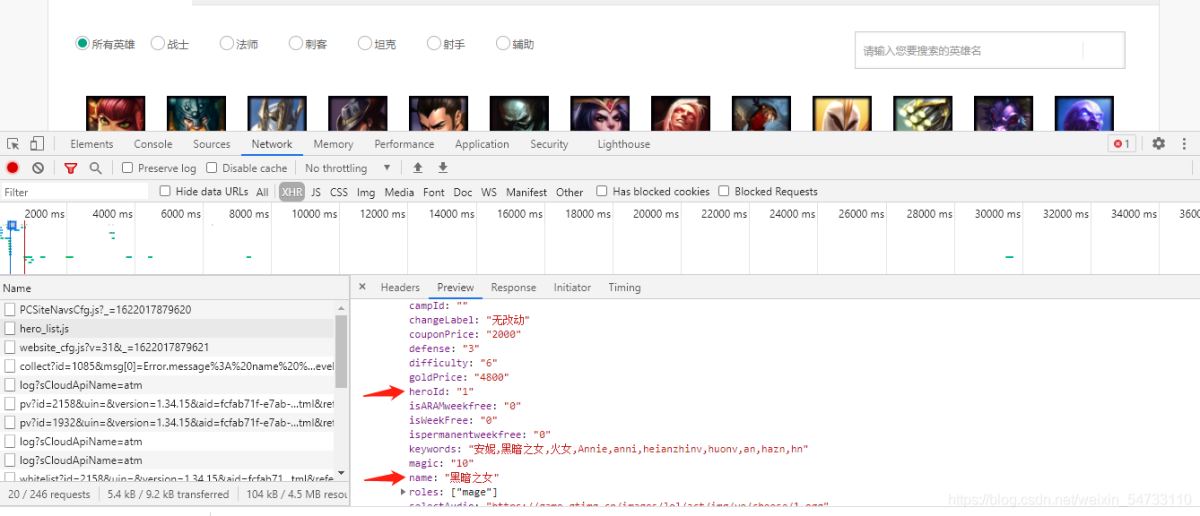
1第一次請求,我們要拿回這兩個數據。可以看出preview里面是個json數據,導入jsonpath庫進行提取數據。

2第二次請求,得到英雄皮膚名,英雄手機皮膚url, 英雄電腦皮膚url
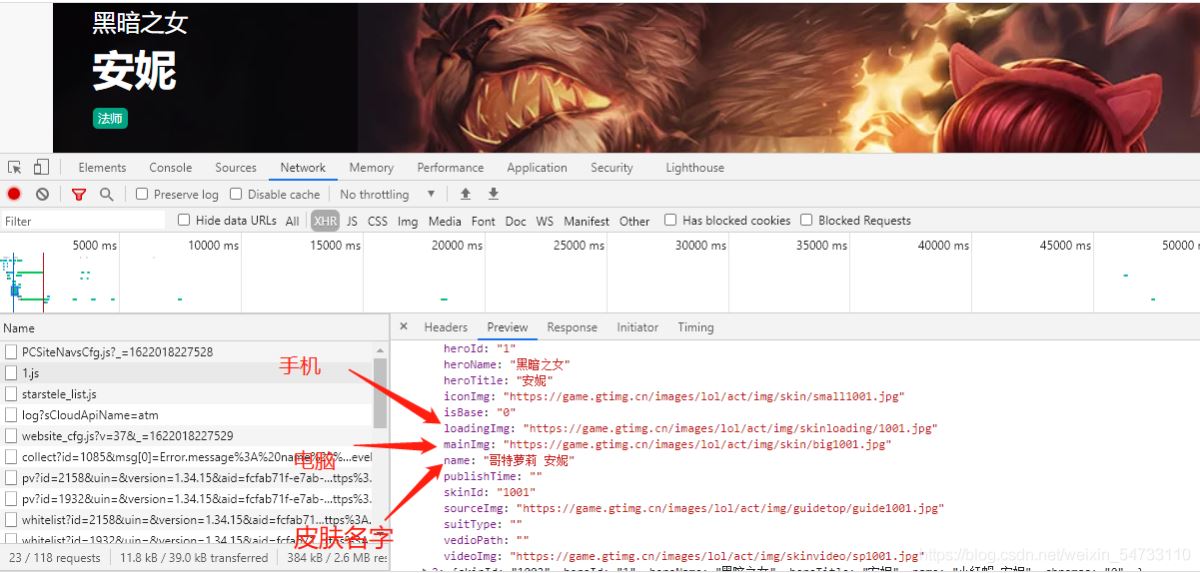

3 請求得到 手機圖片二進制數據, 電腦圖片二進制數據 利用try-except語句防止報錯停止代碼運行。

4.保存電腦版英雄聯盟圖片,保存手機版英雄聯盟圖片,利用try-except語句防止報錯停止代碼運行。
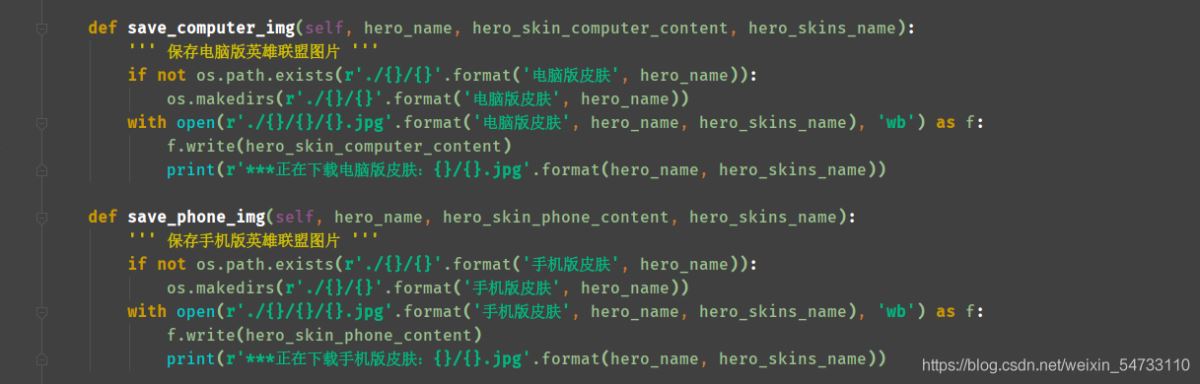
5.多進程實現保存數據 導包:import threading
threading.Thread(target=self.函數名, args=(用到的參數)) 寫法

代碼全解:
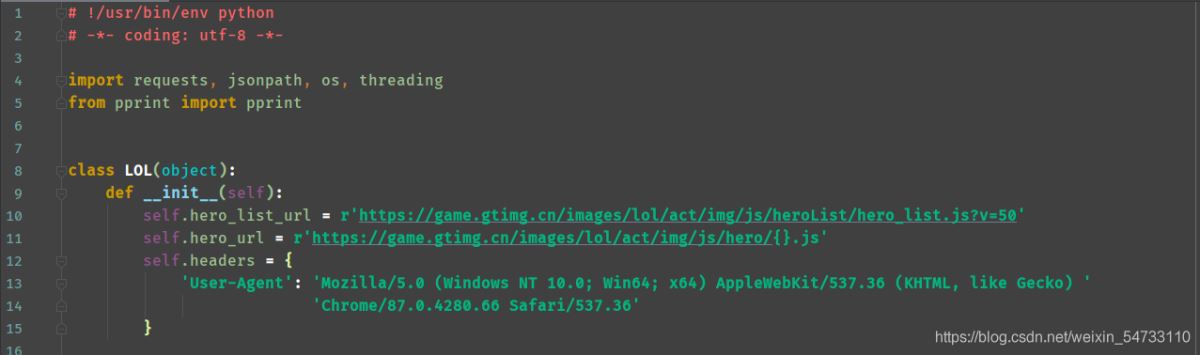
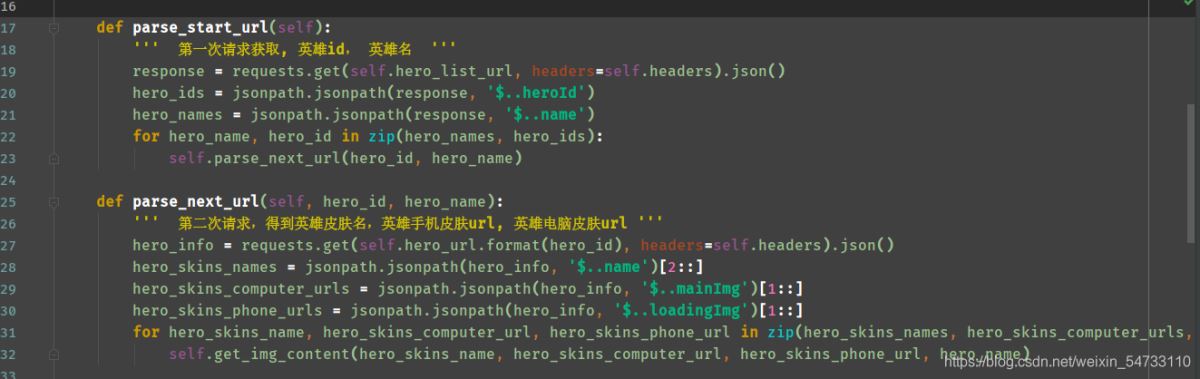
最后在發一個守護線程防止報錯的模板,大家好好參考。
from threading import Thread
from queue import Queue
class Love(object):
def init(self):
# 隊列容量,隊列創建 ,[], {}
self.q = Queue()
def parse_data(self):
"""功能:往隊列添加數據"""
data = "第{}天----我愛你----"
for i in range(1, 100):
# 將數據放入隊列,put的時候計數+1,get不會-1,get需要和task_done一起使用才會-1
self.q.put(data.format(i))
# 等待task_done()返回的信號量和put進去的數量一直才會往下執行
# join所完成的工作就是線程同步,即主線程任務結束之后,進入阻塞狀態,一
# 直等待其他的子線程執行結束之后,主線程在終止,否則主線程會殺死子線程
# 主線程結束后子線程無論是否執行完畢都將結束,因此join的作用就顯現出來了
self.q.join()
def func2(self):
"""功能:從隊列中獲取數據"""
while True:
# 循環從隊列中獲取, 取出數據,隊列為空的時候會等待
result = self.q.get()
print(result)
# 使隊列計數-1
self.q.task_done()
def run(self):
# 進程創建
"""進程:功能:往隊列中添加數據"""
m1 = Thread(target=self.parse_data)
"""進程:功能:從隊列里面獲取數據"""
m2 = Thread(target=self.func2)
m1.start()
# 將m2設置成守護進程 因為m2一直是死循環,設置成守護進程之后當主程序代碼運行完畢,m2就會結束,不會成為僵尸進程
# 即只在需要的時候才啟動,完成任務后就自動結束
m2.daemon = True
m2.start()
# 隊列中維持了一個計數,計數不為0時候讓主線程阻塞等待,隊列計數為0的時候才會繼續往后執行
m1.join()
if name == ‘main':
love = Love()
love.run()
祝大家學習python順利
以上就是python爬取英雄聯盟皮膚結合多線程的方法的詳細內容,更多關于python爬取英雄聯盟皮膚的資料請關注腳本之家其它相關文章!
您可能感興趣的文章:- python 爬取英雄聯盟皮膚圖片
- python 爬取英雄聯盟皮膚并下載的示例
- 用Python爬取LOL所有的英雄信息以及英雄皮膚的示例代碼
- python爬取王者榮耀全皮膚的簡單實現代碼
- Python3爬取英雄聯盟英雄皮膚大圖實例代碼
- 教你用Python爬取英雄聯盟皮膚原畫
