1 re.search() 的作用:
re.search會匹配整個字符串,并返回第一個成功的匹配。如果匹配失敗,則返回None
從源碼里面可以看到re.search()方法里面有3個參數

pattern: 匹配的規則,
string : 要匹配的內容,
flags 標志位 這個是可選的,就是可以不寫,可以寫, 比如要忽略字符的大小寫就可以使用標志位
flags 的主要內容如下
flags : 可選,表示匹配模式,比如忽略大小寫,多行模式等,具體參數為:
- re.I 忽略大小寫
- re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依賴于當前環境
- re.M 多行模式
- re.S 即為 . 并且包括換行符在內的任意字符(. 不包括換行符)
- re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依賴于 Unicode 字符屬性數據庫
- re.X 為了增加可讀性,忽略空格和 # 后面的注釋
2 demo 練習re.search() 的使用
2.1 search 簡單的匹配
import re
content = "abcabcabc"
rex = re.search("c", content)
print(rex)
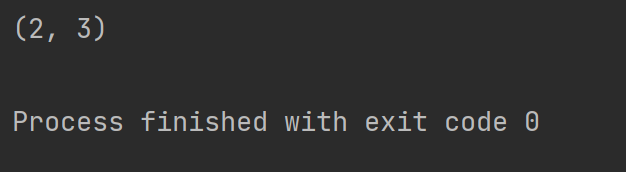
打印結果如下

從內容我們可以看到span(2, 3) 這個應該是對應的下標,所以我們想獲取匹配的下標可以使用span
match 是匹配的內容, 內容為c
2.2 獲取匹配的下標
import re
content = "abcabcabc"
rex = re.search("c", content)
print(rex.group())
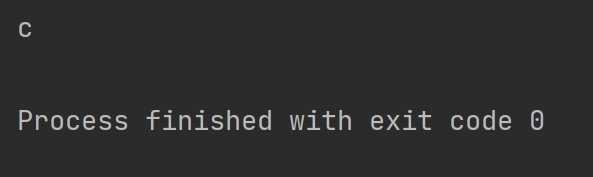
打印結果如下
2.3 獲取匹配的內容 ,使用group(匹配的整個表達式的字符串)
import re
content = "abcabcabc"
rex = re.search("c", content)
print(rex.group())
打印結果如下
注意group 和span 不能同時使用, 否則會報錯
2.4 使用標志位忽略匹配的大小寫
import re
content = "abcabcabc"
rex = re.search("C", content, re.I)
print(rex.group())
打印結果如下
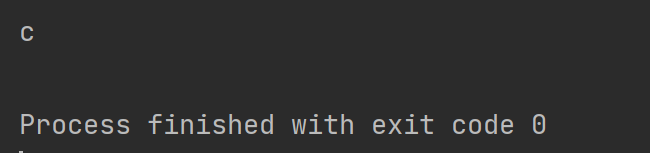
這里使用大寫字母C 忽略大小寫之后也能匹配到c
2.5 使用search 匹配字符串里面的數組
import re
content = "abc123abc"
rex = re.search("\d+", content)
print(rex.group())
打印結果
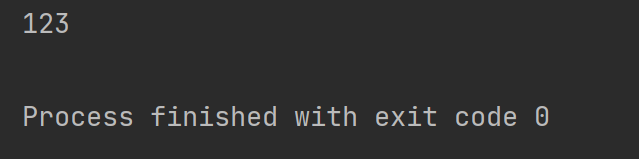
2.6 search 結合compile 使用
import re
content = "abc123abc"
rex_content = re.compile("\d+")
rex = rex_content.search(content)
print(rex.group())
打印結果
2.7 group 的使用
import re
content = "abc123def"
rex_compile = re.compile("([a-z]*)([0-9]*)([a-z]*)")
rex = rex_compile.search(content)
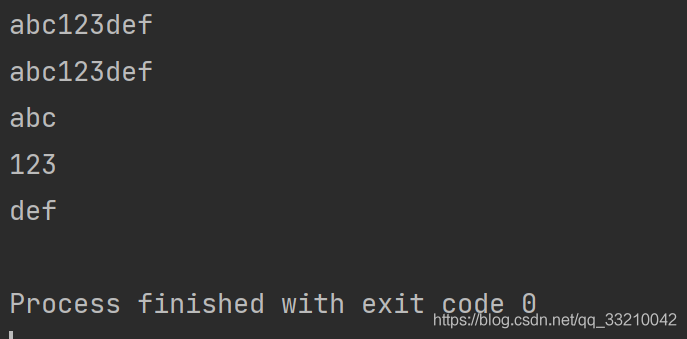
print(rex.group())
print(rex.group(0)) # group()和group(0) 一樣匹配的是整體
print(rex.group(1)) # 匹配第一個小括號的內容
print(rex.group(2)) # 匹配第二個小括號的內容
print(rex.group(3)) # 匹配第三個小括號的內容
打印結果
group() 小括號里面不止有數字,可以是自定的內容如下
content = "zhangsanfeng108le"
rex_compile = re.compile("(?Pname>[a-z]*)(?Page>[0-9]*)")
rex_content = rex_compile.search(content)
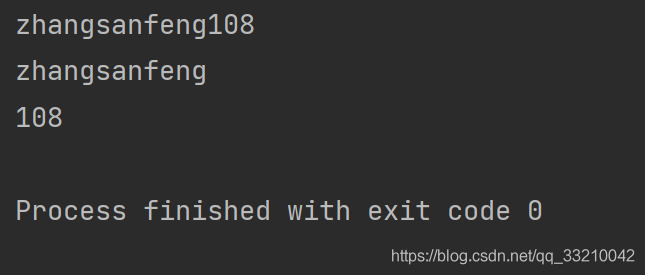
print(rex_content.group())
print(rex_content.group("name")) # 這里效果等同于group(1)
print(rex_content.group("age")) # 這里效果等同于group(2)
打印結果如下
總結
到此這篇關于python正則表達式re.search()基本使用的文章就介紹到這了,更多相關python正則表達式re.search()內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- python演示解答正則為什么是最強文本處理工具
- 一篇文章帶你了解Python和Java的正則表達式對比
- 一篇文章徹底搞懂python正則表達式
- 超詳細講解python正則表達式
- Python正則表達式保姆式教學詳細教程
- 帶你精通Python正則表達式
- Python正則表達式中的量詞符號與組問題小結
- 一篇文章帶你了解python正則表達式的正確用法
- Python正則表達式的應用詳解
- 淺談Python中的正則表達式
- python正則表達式函數match()和search()的區別
