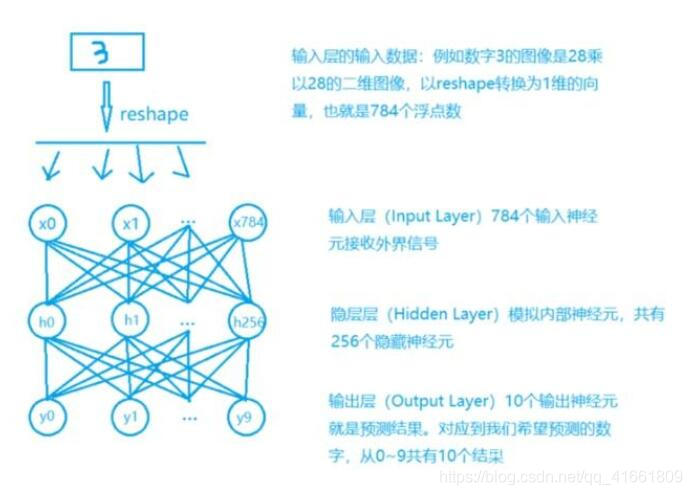
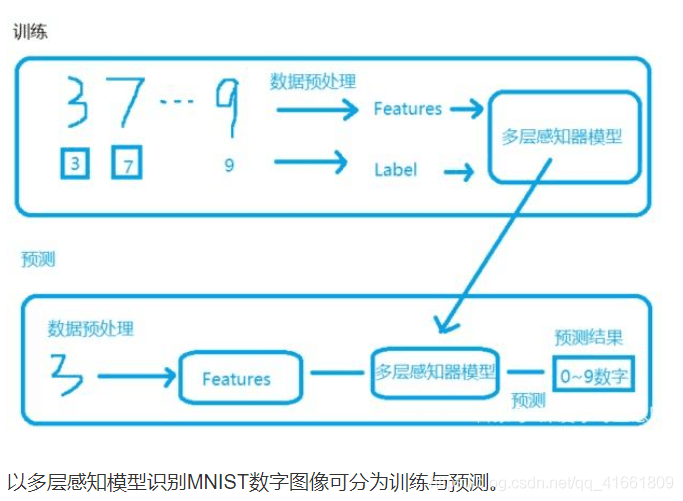
| 參數(shù) | 說明 |
| units =256 | 定義"隱藏層"神經(jīng)元的個數(shù)為256 |
| input_dim | 設置輸入層神經(jīng)元個數(shù)為 784 |
| kernel_initialize='normal' | 使用正態(tài)分布的隨機數(shù)初始化weight和bias |
| activation | 激勵函數(shù)為 relu |
4 建立輸出層
model.add(Dense(
units=10,
kernel_initializer='normal',
activation='softmax'
))
| 參數(shù) | 說明 |
| units | 定義"輸出層"神經(jīng)元個數(shù)為10 |
| kernel_initializer='normal' | 同上 |
| activation='softmax | 激活函數(shù) softmax |
5 查看模型的摘要
print(model.summary())

param 的計算是 上一次的神經(jīng)元個數(shù) * 本層神經(jīng)元個數(shù) + 本層神經(jīng)元個數(shù) .
1 定義訓練方式
model.compile(loss='categorical_crossentropy' ,optimizer='adam',metrics=['accuracy'])
loss (損失函數(shù)) : 設置損失函數(shù), 這里使用的是交叉熵 .
optimizer : 優(yōu)化器的選擇,可以讓訓練更快的收斂
metrics : 設置評估模型的方式是準確率
開始訓練 2
train_history = model.fit(x=x_Train_normalize,y=y_TrainOneHot,validation_split=0.2 ,
epoch=10,batch_size=200,verbose=2)
使用 model.fit() 進行訓練 , 訓練過程會存儲在 train_history 變量中 .
(1)輸入訓練數(shù)據(jù)參數(shù)
x = x_Train_normalize
y = y_TrainOneHot
(2)設置訓練集和驗證集的數(shù)據(jù)比例
validation_split=0.2 8 :2 = 訓練集 : 驗證集
(3) 設置訓練周期 和 每一批次項數(shù)
epoch=10,batch_size=200
(4) 顯示訓練過程
verbose = 2
3 建立show_train_history 顯示訓練過程
def show_train_history(train_history,train,validation) :
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title("Train_history")
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train','validation'],loc='upper left')
plt.show()
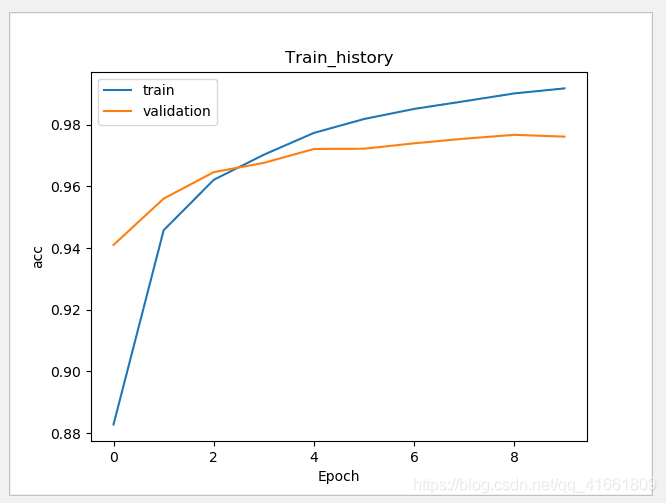
測試數(shù)據(jù)評估模型準確率
scores = model.evaluate(x_Test_normalize,y_TestOneHot)
print()
print('accuracy=',scores[1] )
accuracy= 0.9769
通過之前的步驟, 我們建立了模型, 并且完成了模型訓練 ,準確率達到可以接受的 0.97 . 接下來我們將使用此模型進行預測.
1 執(zhí)行預測
prediction = model.predict_classes(x_Test) print(prediction)
result : [7 2 1 ... 4 5 6]
2 顯示 10 項預測結果
plot_images_labels_prediction(x_test_image,y_test_label,prediction,idx=340)

我們可以看到 第一個數(shù)字 label 是 5 結果預測成 3 了.
上面我們在預測到第340 個測試集中的數(shù)字5 時 ,卻被錯誤的預測成了 3 .如果想要更進一步的知道我們所建立的模型中哪些 數(shù)字的預測準確率更高 , 哪些數(shù)字會容忍混淆 .
混淆矩陣 也稱為 誤差矩陣.
1 使用Pandas 建立混淆矩陣 .
showMetrix = pd.crosstab(y_test_label,prediction,colnames=['label',],rownames=['predict']) print(showMetrix)
label 0 1 2 3 4 5 6 7 8 9 predict 0 971 0 1 1 1 0 2 1 3 0 1 0 1124 4 0 0 1 2 0 4 0 2 5 0 1009 2 1 0 3 4 8 0 3 0 0 5 993 0 1 0 3 4 4 4 1 0 5 1 961 0 3 0 3 8 5 3 0 0 16 1 852 7 2 8 3 6 5 3 3 1 3 3 939 0 1 0 7 0 5 13 7 1 0 0 988 5 9 8 4 0 3 7 1 1 1 2 954 1 9 3 6 0 11 7 2 1 4 4 971
2 使用DataFrame
df = pd.DataFrame({'label ':y_test_label, 'predict':prediction})
print(df)
label predict
0 7 7
1 2 2
2 1 1
3 0 0
4 4 4
5 1 1
6 4 4
7 9 9
8 5 5
9 9 9
10 0 0
11 6 6
12 9 9
13 0 0
14 1 1
15 5 5
16 9 9
17 7 7
18 3 3
19 4 4
20 9 9
21 6 6
22 6 6
23 5 5
24 4 4
25 0 0
26 7 7
27 4 4
28 0 0
29 1 1
... ... ...
9970 5 5
9971 2 2
9972 4 4
9973 9 9
9974 4 4
9975 3 3
9976 6 6
9977 4 4
9978 1 1
9979 7 7
9980 2 2
9981 6 6
9982 5 6
9983 0 0
9984 1 1
9985 2 2
9986 3 3
9987 4 4
9988 5 5
9989 6 6
9990 7 7
9991 8 8
9992 9 9
9993 0 0
9994 1 1
9995 2 2
9996 3 3
9997 4 4
9998 5 5
9999 6 6
model.add(Dense(units=1000,
input_dim=784,
kernel_initializer='normal',
activation='relu'))
hidden layer 神經(jīng)元的增大,參數(shù)也增多了, 所以訓練model的時間也變慢了.
加入 Dropout 功能避免過度擬合
# 建立Sequential 模型
model = Sequential()
model.add(Dense(units=1000,
input_dim=784,
kernel_initializer='normal',
activation='relu'))
model.add(Dropout(0.5)) # 加入Dropout
model.add(Dense(units=10,
kernel_initializer='normal',
activation='softmax'))
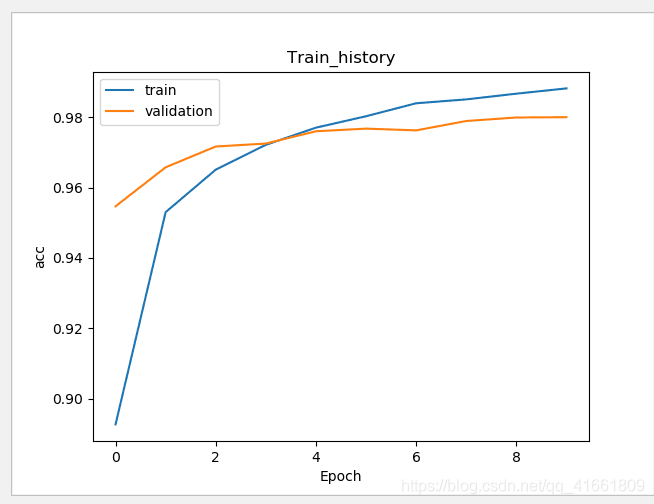
訓練的準確率 和 驗證的準確率 差距變小了 .
建立多層感知器模型包含兩層隱藏層
# 建立Sequential 模型
model = Sequential()
# 輸入層 +" 隱藏層"1
model.add(Dense(units=1000,
input_dim=784,
kernel_initializer='normal',
activation='relu'))
model.add(Dropout(0.5)) # 加入Dropout
# " 隱藏層"2
model.add(Dense(units=1000,
kernel_initializer='normal',
activation='relu'))
model.add(Dropout(0.5)) # 加入Dropout
# " 輸出層"
model.add(Dense(units=10,
kernel_initializer='normal',
activation='softmax'))
print(model.summary())

代碼:
import tensorflow as tf
import keras
import matplotlib.pyplot as plt
import numpy as np
from keras.utils import np_utils
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
import pandas as pd
import os
np.random.seed(10)
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
(x_train_image ,y_train_label),(x_test_image,y_test_label) = mnist.load_data()
#
# print('train data = ' ,len(X_train_image)) #
# print('test data = ',len(X_test_image))
def plot_image(image):
fig = plt.gcf()
fig.set_size_inches(2,2) # 設置圖形的大小
plt.imshow(image,cmap='binary') # 傳入圖像image ,cmap 參數(shù)設置為 binary ,以黑白灰度顯示
plt.show()
def plot_images_labels_prediction(images, labels,
prediction, idx, num=10):
fig = plt.gcf()
fig.set_size_inches(12, 14)
if num > 25: num = 25
for i in range(0, num):
ax = plt.subplot(5, 5, 1 + i)# 分成 5 X 5 個子圖顯示, 第三個參數(shù)表示第幾個子圖
ax.imshow(images[idx], cmap='binary')
title = "label=" + str(labels[idx])
if len(prediction) > 0:
title += ",predict=" + str(prediction[idx])
ax.set_title(title, fontsize=10)
ax.set_xticks([])
ax.set_yticks([])
idx += 1
plt.show()
def show_train_history(train_history,train,validation) :
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title("Train_history")
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train','validation'],loc='upper left')
plt.show()
# plot_images_labels_prediction(x_train_image,y_train_image,[],0,10)
#
# plot_images_labels_prediction(x_test_image,y_test_image,[],0,10)
print("x_train_image : " ,len(x_train_image) , x_train_image.shape )
print("y_train_label : ", len(y_train_label) , y_train_label.shape)
# 將 image 以 reshape 轉(zhuǎn)化
x_Train = x_train_image.reshape(60000,784).astype('float32')
x_Test = x_test_image.reshape(10000,784).astype('float32')
# print('x_Train : ' ,x_Train.shape)
# print('x_Test' ,x_Test.shape)
# 標準化
x_Test_normalize = x_Test/255
x_Train_normalize = x_Train/255
# print(x_Train_normalize[0]) # 訓練集中的第一個數(shù)字的標準化
# 將訓練集和測試集標簽都進行獨熱碼轉(zhuǎn)化
y_TrainOneHot = np_utils.to_categorical(y_train_label)
y_TestOneHot = np_utils.to_categorical(y_test_label)
print(y_TrainOneHot[:5]) # 查看前5項的標簽
# 建立Sequential 模型
model = Sequential()
model.add(Dense(units=1000,
input_dim=784,
kernel_initializer='normal',
activation='relu'))
model.add(Dropout(0.5)) # 加入Dropout
# " 隱藏層"2
model.add(Dense(units=1000,
kernel_initializer='normal',
activation='relu'))
model.add(Dropout(0.5)) # 加入Dropout
model.add(Dense(units=10,
kernel_initializer='normal',
activation='softmax'))
print(model.summary())
# 訓練方式
model.compile(loss='categorical_crossentropy' ,optimizer='adam',metrics=['accuracy'])
# 開始訓練
train_history =model.fit(x=x_Train_normalize,
y=y_TrainOneHot,validation_split=0.2,
epochs=10, batch_size=200,verbose=2)
show_train_history(train_history,'acc','val_acc')
scores = model.evaluate(x_Test_normalize,y_TestOneHot)
print()
print('accuracy=',scores[1] )
prediction = model.predict_classes(x_Test)
print(prediction)
plot_images_labels_prediction(x_test_image,y_test_label,prediction,idx=340)
showMetrix = pd.crosstab(y_test_label,prediction,colnames=['label',],rownames=['predict'])
print(showMetrix)
df = pd.DataFrame({'label ':y_test_label, 'predict':prediction})
print(df)
#
#
# plot_image(x_train_image[0])
#
# print(y_train_image[0])
代碼2:
import numpy as np
from keras.models import Sequential
from keras.layers import Dense , Dropout ,Deconv2D
from keras.utils import np_utils
from keras.datasets import mnist
from keras.optimizers import SGD
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
def load_data():
(x_train,y_train),(x_test,y_test) = mnist.load_data()
number = 10000
x_train = x_train[0:number]
y_train = y_train[0:number]
x_train =x_train.reshape(number,28*28)
x_test = x_test.reshape(x_test.shape[0],28*28)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
y_train = np_utils.to_categorical(y_train,10)
y_test = np_utils.to_categorical(y_test,10)
x_train = x_train/255
x_test = x_test /255
return (x_train,y_train),(x_test,y_test)
(x_train,y_train),(x_test,y_test) = load_data()
model = Sequential()
model.add(Dense(input_dim=28*28,units=689,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(units=689,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(units=689,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(output_dim=10,activation='softmax'))
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
model.fit(x_train,y_train,batch_size=10000,epochs=20)
res1 = model.evaluate(x_train,y_train,batch_size=10000)
print("\n Train Acc :",res1[1])
res2 = model.evaluate(x_test,y_test,batch_size=10000)
print("\n Test Acc :",res2[1])
以上為個人經(jīng)驗,希望能給大家一個參考,也希望大家多多支持腳本之家。