目錄
- 一、解析網(wǎng)站
- 1.1 獲取音頻地址
- 1.2 解析專欄網(wǎng)頁(yè)
- 1.3 整理億下思路
- 二、編寫爬取代碼
一、解析網(wǎng)站
1.1 獲取音頻地址
在喜馬拉雅網(wǎng)站上,隨便點(diǎn)開(kāi)一個(gè)音頻,打開(kāi)“開(kāi)發(fā)者工具”,再點(diǎn)擊播放按鈕,可以看到出現(xiàn)了多個(gè)請(qǐng)求:
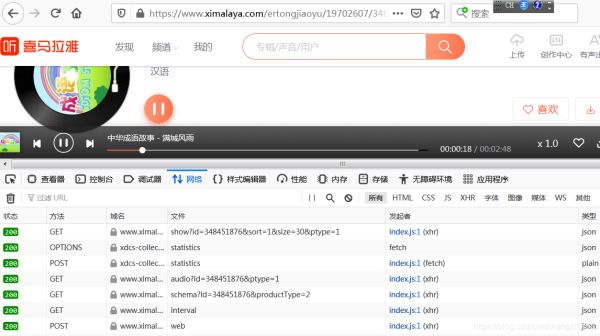
經(jīng)過(guò)排查,發(fā)現(xiàn)可疑url:

查看它的響應(yīng)信息,發(fā)現(xiàn)音頻地址就在里面:
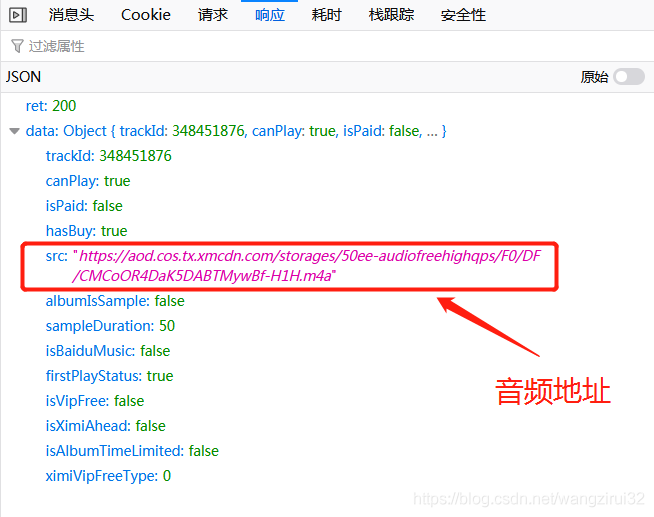
接下來(lái),解析這個(gè)返回音頻地址的url:
https://www.ximalaya.com/revision/play/v1/audio?id=348451879ptype=1
發(fā)現(xiàn)url中的id參數(shù)就決定了返回的音頻地址,而id參數(shù)是音頻的id號(hào)。
1.2 解析專欄網(wǎng)頁(yè)
我們已經(jīng)知道了獲取音頻url的網(wǎng)址,接下來(lái)要獲取一個(gè)專欄內(nèi)的音頻id和名稱,打開(kāi)一個(gè)專欄,發(fā)現(xiàn):
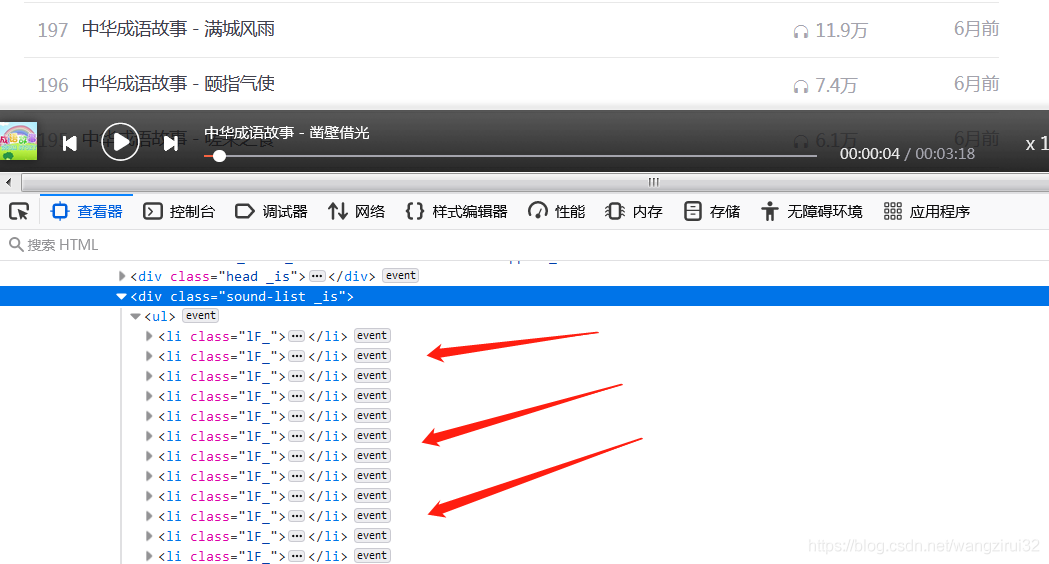
所有的音頻存放在class為1F_的li標(biāo)簽中,再來(lái)解析li標(biāo)簽:
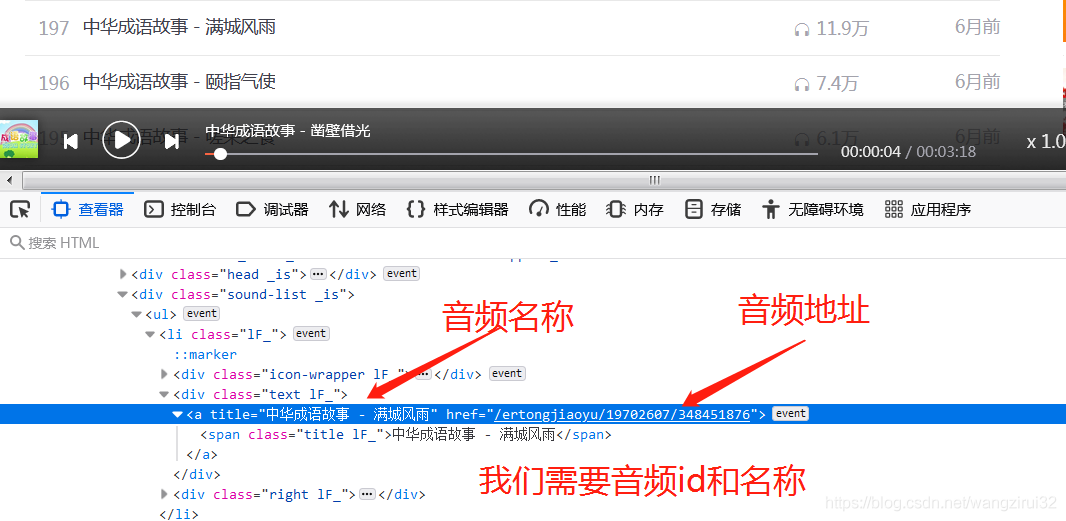
在li標(biāo)簽中的第一個(gè)a標(biāo)簽存儲(chǔ)著我們所有需要的數(shù)據(jù),妙~啊!
1.3 整理億下思路
思路:
1.獲取專欄內(nèi)的li標(biāo)簽
2.獲取li標(biāo)簽里的第一個(gè)a標(biāo)簽
3.讀取a標(biāo)簽的title和href屬性
4.將href解析成音頻id
5.將id帶入url請(qǐng)求音頻源地址
6.提取音頻源地址
7.請(qǐng)求音頻源地址
8.保存音頻(文件名為a的title屬性)
思路整理完了,開(kāi)始編寫代碼。
二、編寫爬取代碼
代碼奉上——
import requests
from fake_useragent import UserAgent as ua
from bs4 import BeautifulSoup as bs
# 專欄地址
music_list_url = 'https://www.ximalaya.com/ertongjiaoyu/19702607/'
# 獲取音頻地址的url
get_link_url = "https://www.ximalaya.com/revision/play/v1/audio"
# UA偽裝
headers = {
"User-Agent": ua().random
}
# 參數(shù)
params = {
"id": None, # id先設(shè)為None
"ptype": "1",
}
# 獲取專欄HTML源碼
music_list_r = requests.get(music_list_url, headers=headers)
# 解析 獲取所有l(wèi)i標(biāo)簽
soup = bs(music_list_r.text, "lxml")
li = soup.find_all("li", {"class": "lF_"})
# for循序遍歷處理
for i in li:
a = i.find("a") # 找到a標(biāo)簽
# 獲取href屬性
# split("/")將字符串以"/"作為分隔符 從右往左數(shù)第一項(xiàng)是id號(hào)
music_id = a.get("href").split("/")[-1]
# 獲取title屬性 和“.m4a”拼接成文件名
music_name = a.get("title") + ".m4a"
# 修改請(qǐng)求參數(shù)id
params['id'] = music_id
# 獲得音頻源地址
r = requests.get(get_link_url, headers=headers, params=params)
link = r.json()['data']['src']
# 獲取音頻文件并保存
music_file = requests.get(link).content
with open(music_name, "wb") as f:
f.write(music_file)
print("下載完畢!")
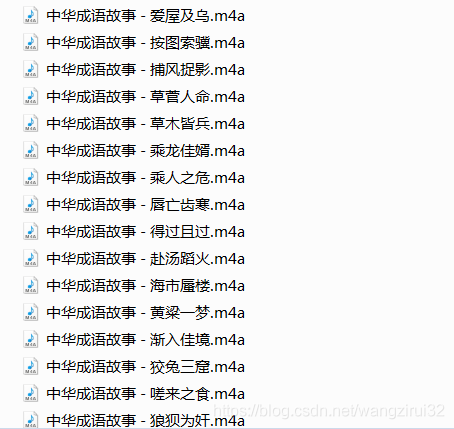
運(yùn)行代碼,等待億會(huì)(真的要等億會(huì)),可以看到當(dāng)前目錄下已經(jīng)出現(xiàn)了音頻文件,如圖:
到此這篇關(guān)于Python爬蟲(chóng)之批量下載喜馬拉雅音頻的文章就介紹到這了,更多相關(guān)Python下載喜馬拉雅音頻內(nèi)容請(qǐng)搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Python 批量下載陰陽(yáng)師網(wǎng)站壁紙
- python爬蟲(chóng)智能翻頁(yè)批量下載文件的實(shí)例詳解
- 用python批量下載apk
- 用python爬蟲(chóng)批量下載pdf的實(shí)現(xiàn)
- python 批量下載bilibili視頻的gui程序
- Python爬蟲(chóng)實(shí)戰(zhàn)之批量下載快手平臺(tái)視頻數(shù)據(jù)
