目錄
- 1. 總覽數據概況
- 1.1 判斷數據缺失和異常
- 1.1.1 查看nan
- 1.1.2 *異常值檢測(重要!易忽略)
- 1.2 了解預測值的分布
- 1.2.1 數字特征分析
- 1.2.2 類別特征分析(會畫,不會利用結果)
- 2. *用pandas_profiling生成數據報告(新技能)
- 3. 小結
數據探索性分析(EDA)
1. 總覽數據概況
數據庫載入
#coding:utf-8
#導入warnings包,利用過濾器來實現忽略警告語句。
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno
數據載入
## 1) 載入訓練集和測試集;
path = './'
Train_data = pd.read_csv(path+'car_train_0110.csv', sep=' ')
Test_data = pd.read_csv(path+'car_testA_0110.csv', sep=' ')
確定path,如果是在notebook環境,我通常使用 !dir查看當前目錄
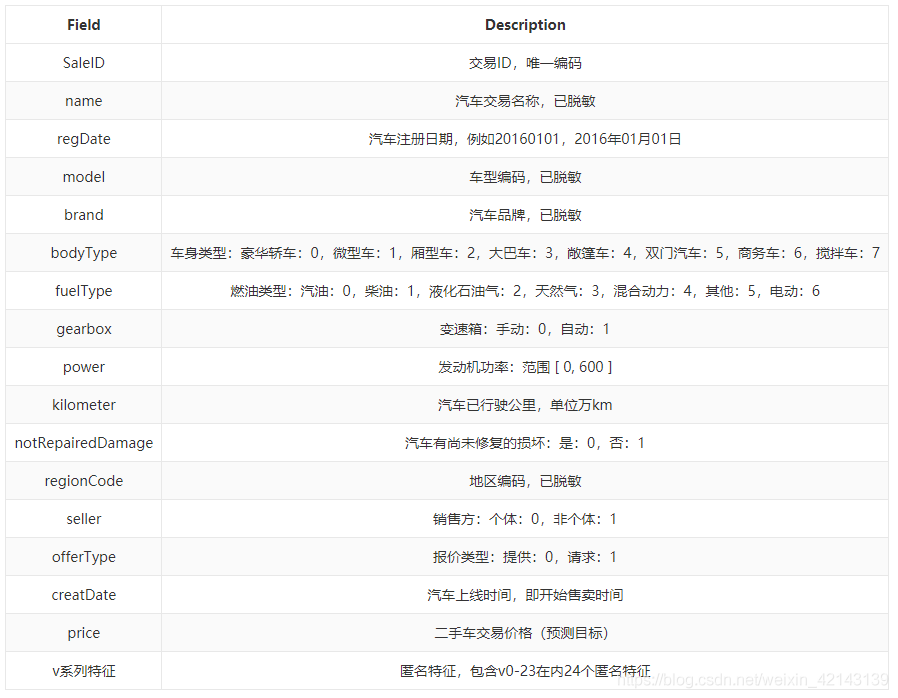
特征說明
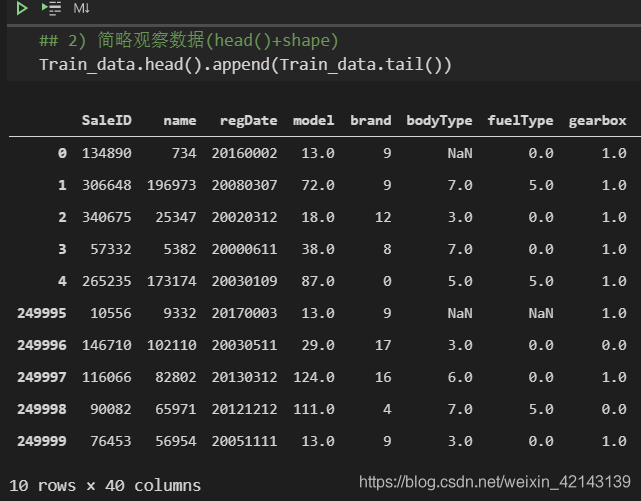
新技能:使用.append()同時觀察前5行與后5行
## 2) 簡略觀察數據(head()+shape)
Train_data.head().append(Train_data.tail())
觀察數據維度
Train_data.shape,Test_data.shape

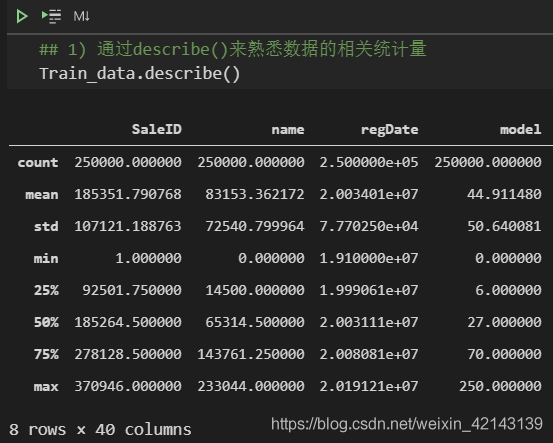
總覽概況: .describe()查看統計量,.info()查看數據類型
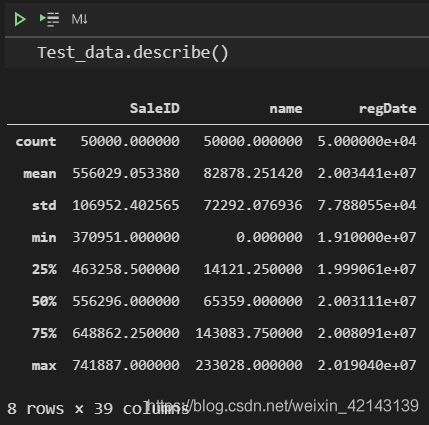
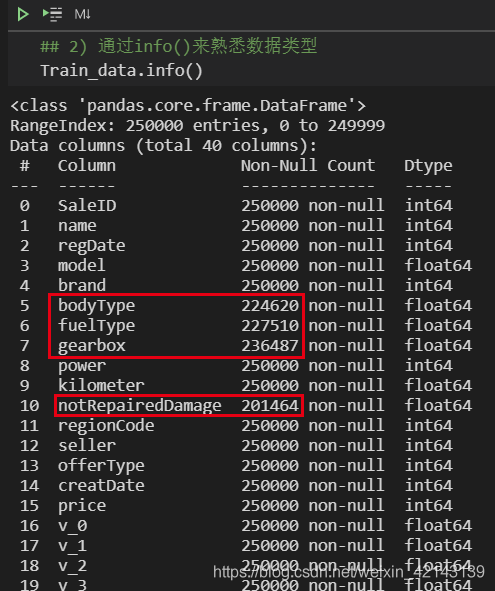
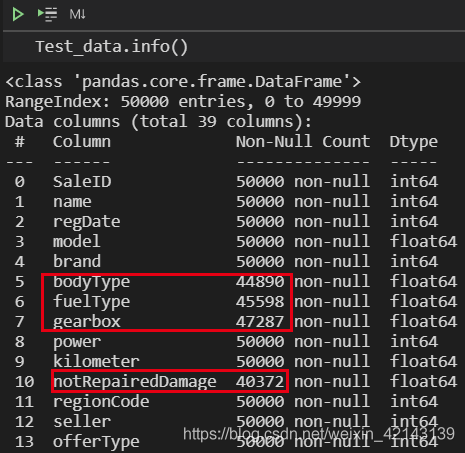
1.1 判斷數據缺失和異常
1.1.1 查看nan
Train_data.shape,Test_data.shape
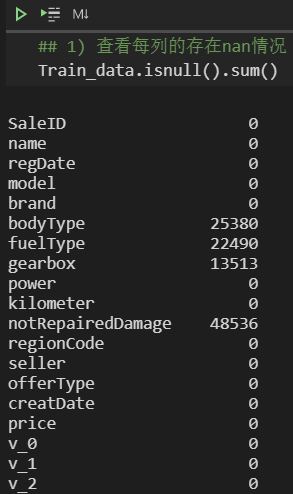
也可直接查看nan,有以下兩種方式 ↓ :
Train_data.isnull().sum()

可視化na更直觀
# find na
tmp = df_train.isnull().any()
tmp[tmp.values==True]
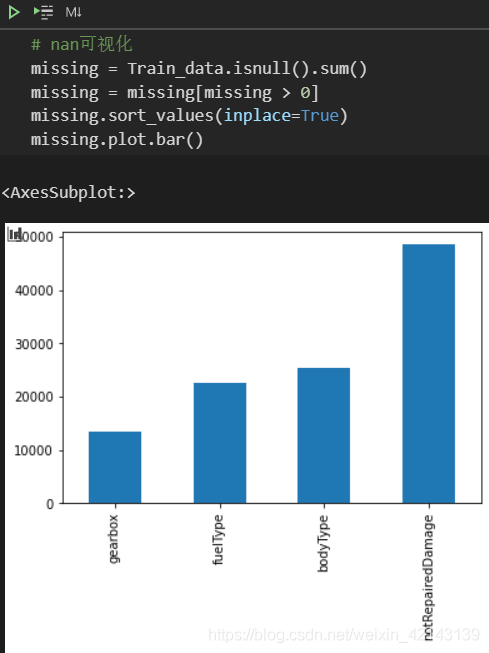
新技能: msno庫(缺失值可視化)的使用
Train_data.isnull().sum().plot( kind= 'bar')
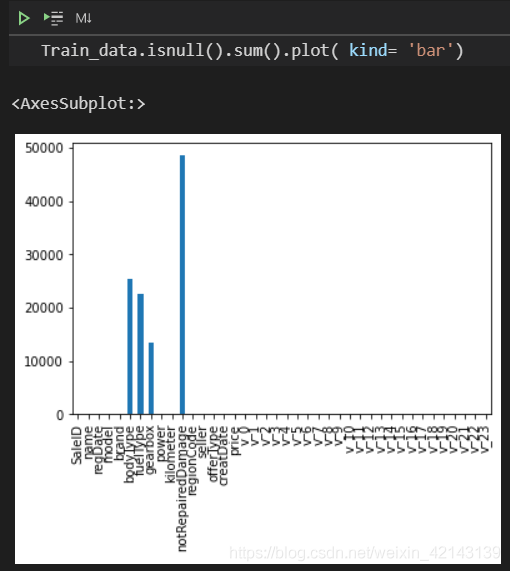
可視化看下缺省值
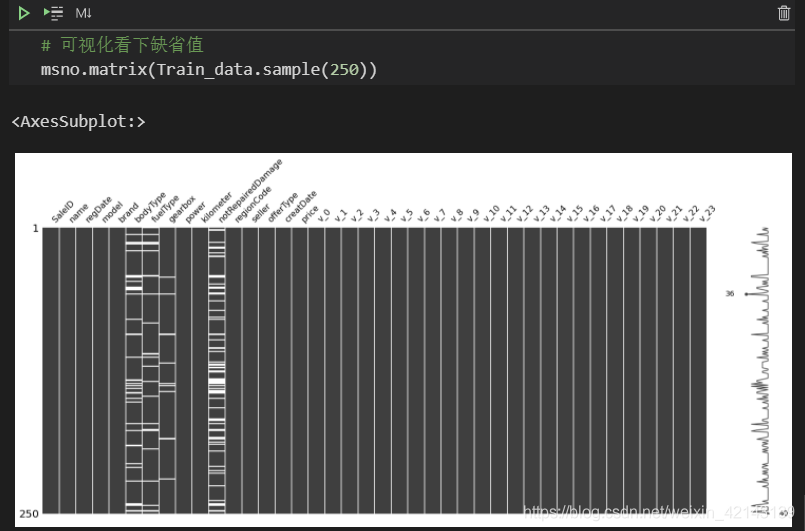
msno.matrix(Train_data.sample(250))
其中,Train_data.sample(250)表示隨機抽樣250行,白色條紋表示缺失
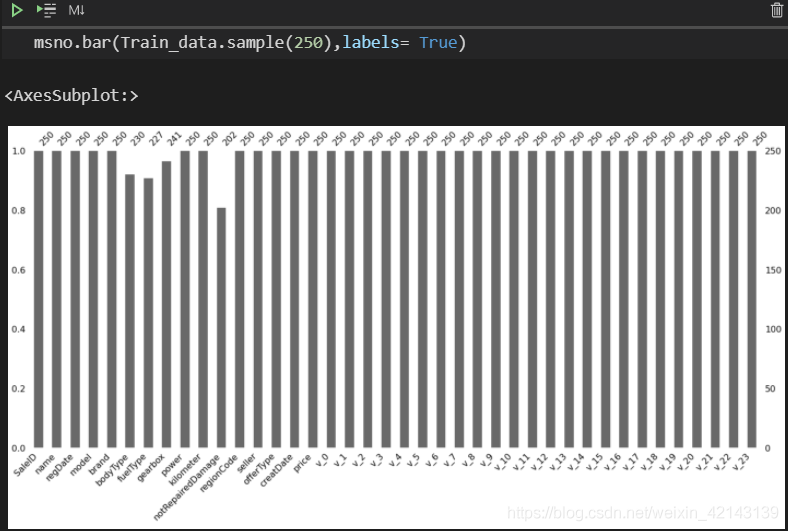
直接顯示未缺失的樣本數量/每特征
msno.bar(Train_data.sample(250),labels= True)
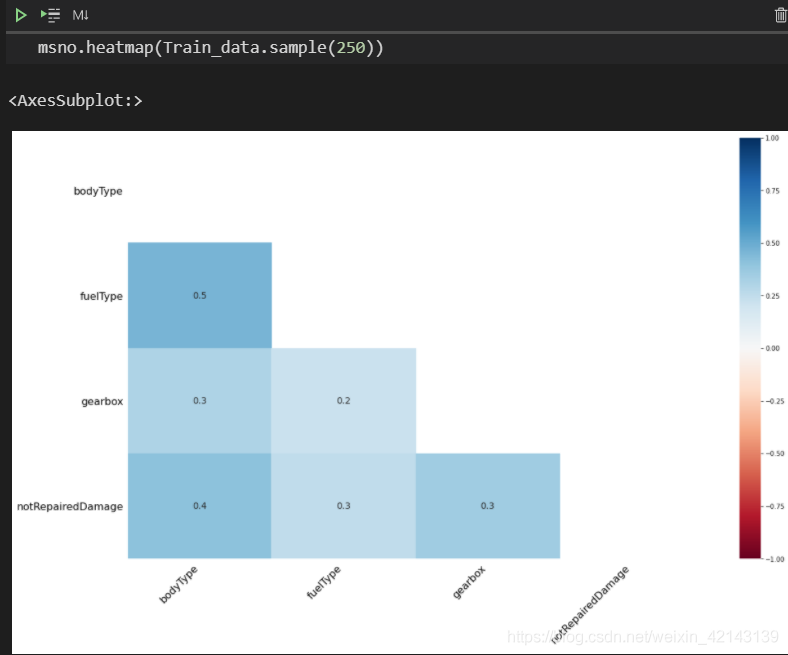
使用msno中的 .heatmap()查看缺失值之間的相關性
msno.heatmap(Train_data.sample(250))
1.1.2 *異常值檢測(重要!易忽略)
通過Train_data.info()了解數據類型
1.2 了解預測值的分布
查看分布的意義在于:
a. 及時將非正態分布數據變化為正態分布數據
b. 異常檢測
1.2.1 數字特征分析
發現都是int
統計分布 ↓
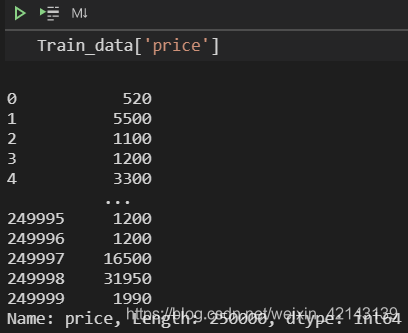
Train_data['price'].value_counts()
## 1) 總體分布概況(無界約翰遜分布等)
import scipy.stats as st
y = Train_data['price']
plt.figure(1); plt.title('Johnson SU')
sns.distplot(y, kde=False, fit=st.johnsonsu)
plt.figure(2); plt.title('Normal')
sns.distplot(y, kde=False, fit=st.norm)
plt.figure(3); plt.title('Log Normal')
sns.distplot(y, kde=False, fit=st.lognorm)
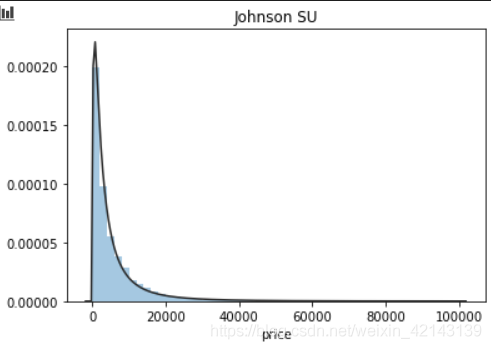
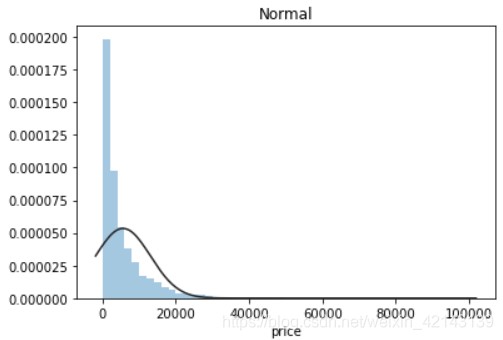
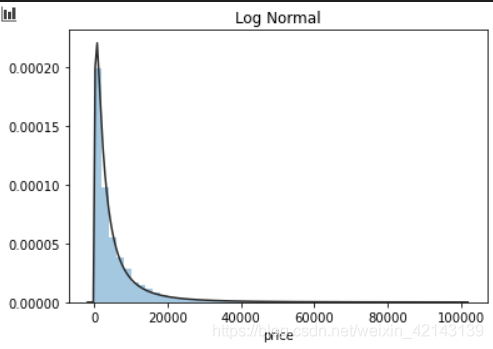
結論:price不服從正態分布,因此在進行回歸之前,它必須進行轉換。無界約翰遜分布擬合效果較好。
1.2.1.1 相關性分析
1.2.1.2 *偏度和峰值
偏度(skewness),統計數據分布偏斜方向和程度,是統計數據分布非對稱程度的數字特征。定義上偏度是樣本的三階標準化矩。
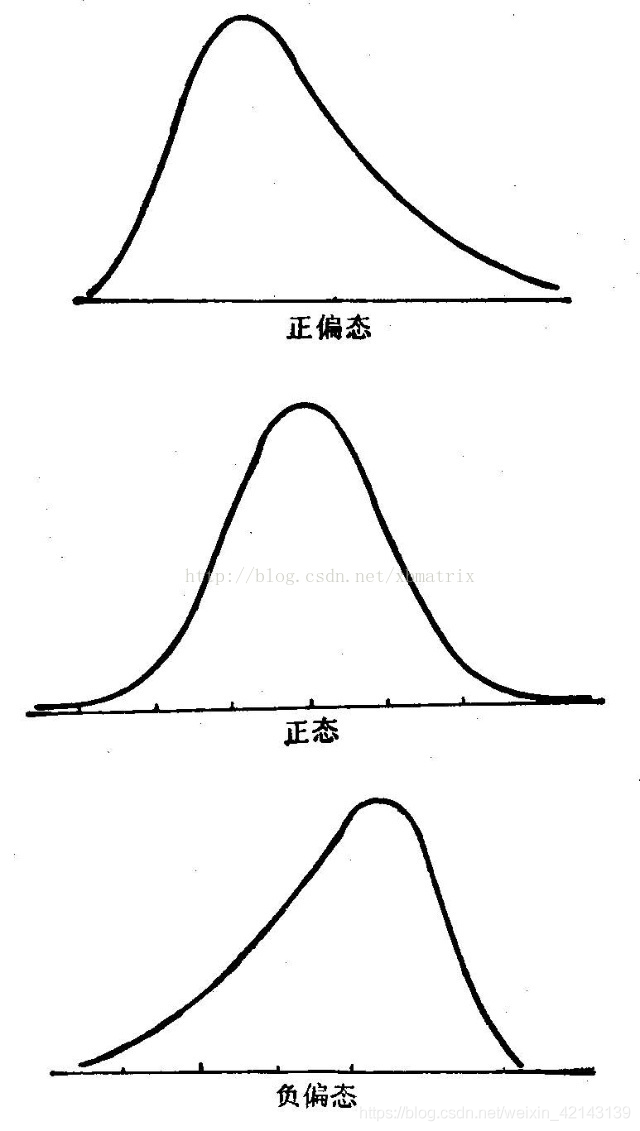
峰度(peakedness;kurtosis)又稱峰態系數。表征概率密度分布曲線在平均值處峰值高低的特征數。直觀看來,峰度反映了峰部的尖度。
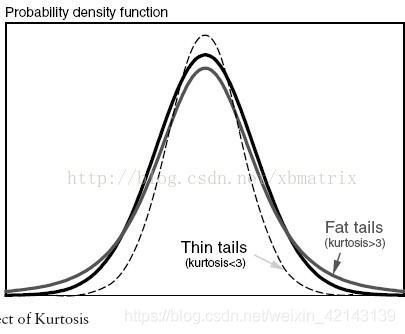
## 2) 查看skewness and kurtosis
sns.distplot(Train_data['price']);
print("Skewness: %f" % Train_data['price'].skew())
print("Kurtosis: %f" % Train_data['price'].kurt())

批量計算skew
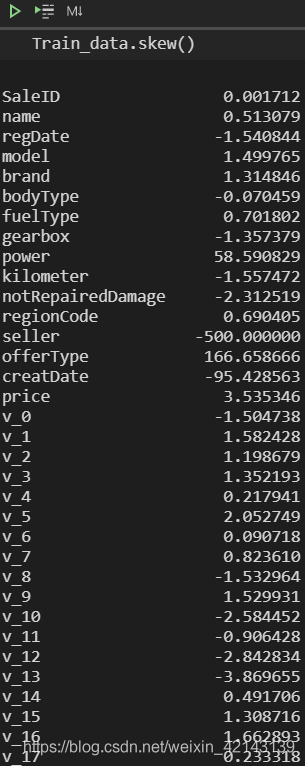
查看skew的分布情況
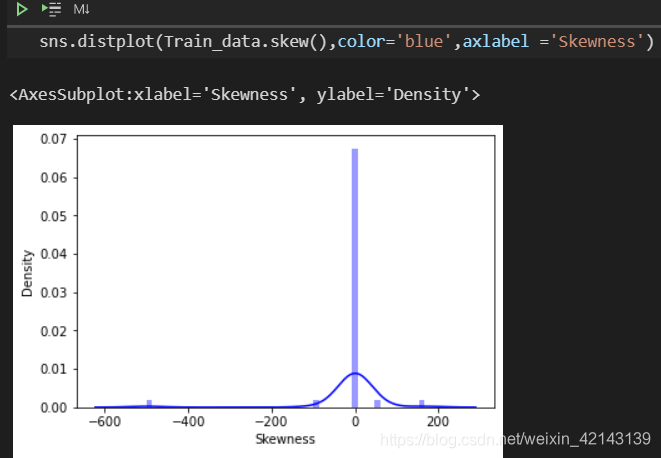
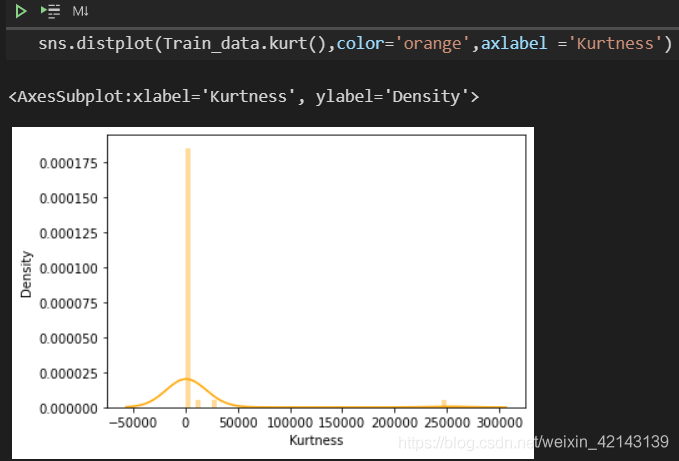
批量計算kurt

查看kurt的分布情況
查看目標變量的分布
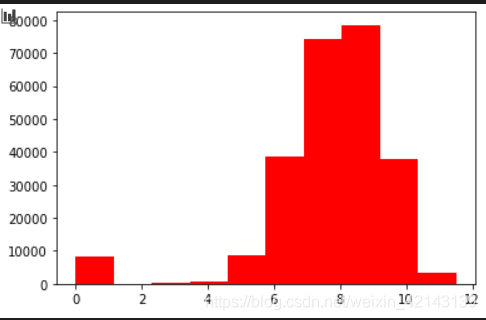
## 3) 查看預測值的具體頻數
plt.hist(Train_data['price'], orientation = 'vertical',histtype = 'bar', color ='red')
plt.show()
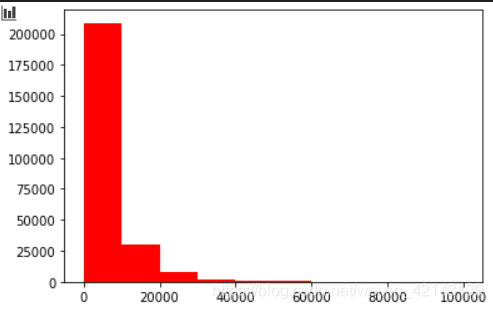
結論:大于20000得值極少,其實這里也可以把這些當作特殊得值(異常值)直接用填充或者刪掉
由于np.log(0)==-inf,無法繪圖,因此改用log(1+x)繪制分布bar,和教程里有出入,教程里用log繪圖如下:(我畫不出來,因為-inf會報錯)
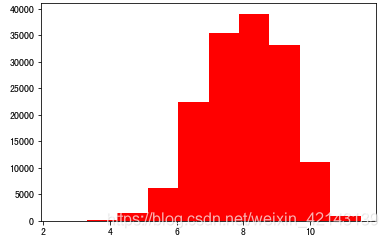
# log變換之后的分布較均勻,可以進行log變換進行預測,這也是預測問題常用的trick
plt.hist(np.log(1+Train_data['price']), orientation = 'vertical',histtype = 'bar', color ='red')
plt.show()
分離label即預測值
Y_train = Train_data['price']
#這個區別方式適用于沒有直接label coding的數據
#這里不適用,需要人為根據實際含義來區分
#數字特征
numeric_features = Train_data.select_dtypes(include=[np.number])
numeric_features.columns
#類型特征
categorical_features = Train_data.select_dtypes(include=[np.object])
categorical_features.columns
numeric_features = ['power', 'kilometer', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13','v_14' ]
categorical_features = ['name', 'model', 'brand', 'bodyType', 'fuelType', 'gearbox', 'notRepairedDamage', 'regionCode',]
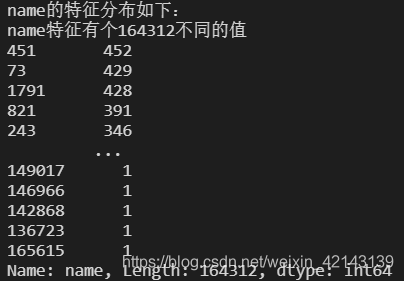
# 特征nunique分布
for cat_fea in categorical_features:
print(cat_fea + "的特征分布如下:")
print("{}特征有個{}不同的值".format(cat_fea, Train_data[cat_fea].nunique()))
print(Train_data[cat_fea].value_counts())
每個特征情況都會逐個如下所示:
test data顯示同理
numeric_features.append('price')
numeric_features
price_numeric = Train_data[numeric_features]
correlation = price_numeric.corr()
correlation
只截了一部分
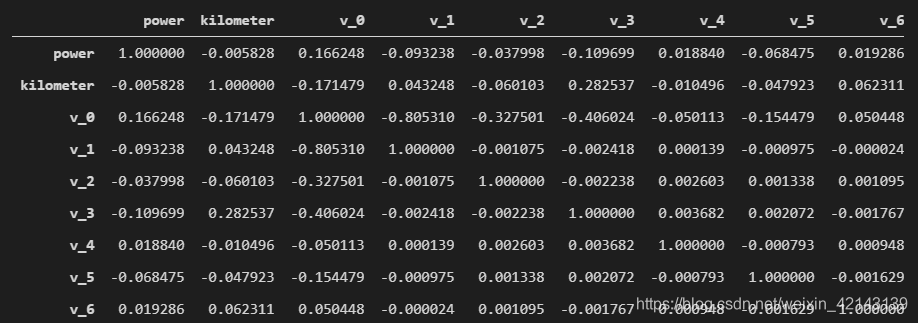
查看相關性(強->弱)
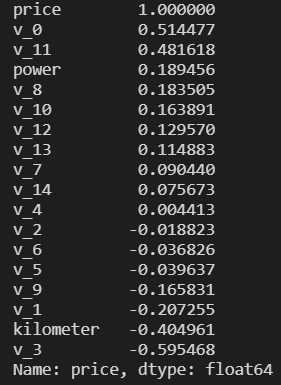
print(correlation['price'].sort_values(ascending = False),'\n')
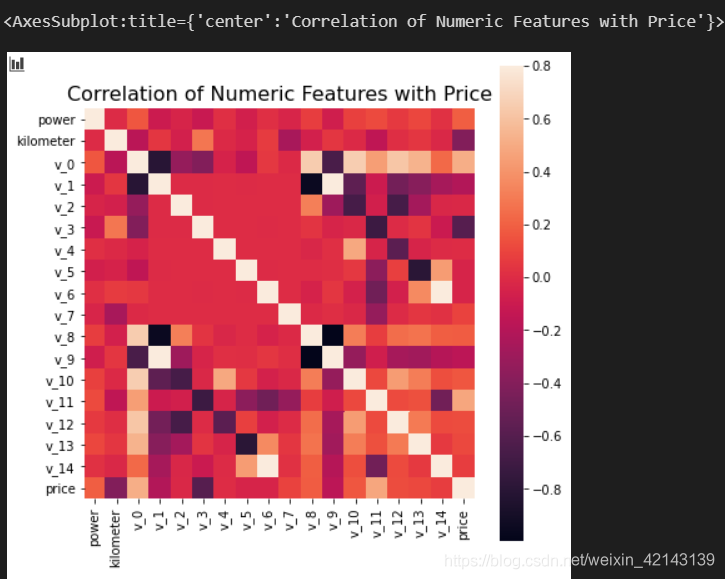
可視化correction
f , ax = plt.subplots(figsize = (7, 7))
plt.title('Correlation of Numeric Features with Price',y=1,size=16)
sns.heatmap(correlation,square = True, vmax=0.8)
price完成歷史使命,刪掉
del price_numeric['price']
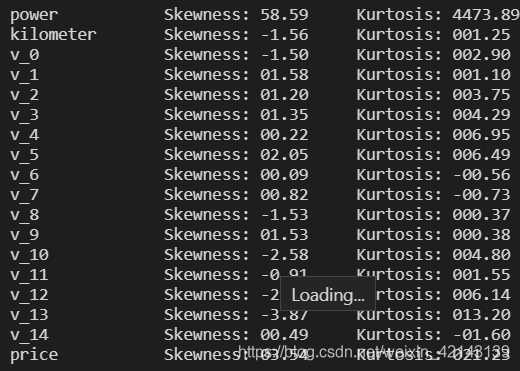
## 2) 查看幾個特征得 偏度和峰值
for col in numeric_features:
print('{:15}'.format(col),
'Skewness: {:05.2f}'.format(Train_data[col].skew()) ,
' ' ,
'Kurtosis: {:06.2f}'.format(Train_data[col].kurt())
)
1.2.1.3 *每個數字特征的分布可視化(易忽略)
## 3) 每個數字特征得分布可視化
f = pd.melt(Train_data, value_vars=numeric_features)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False)
g = g.map(sns.distplot, "value")
只截了部分:
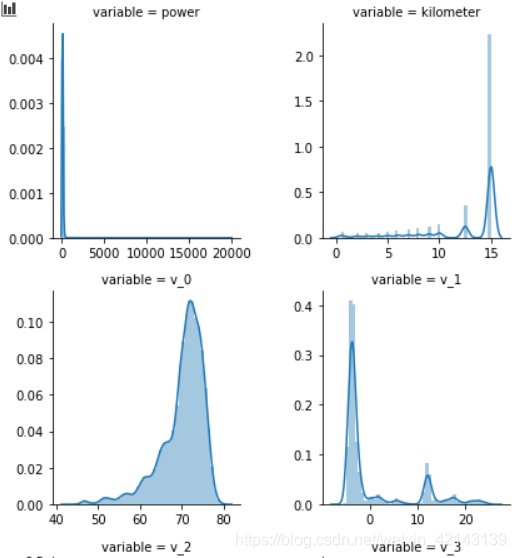
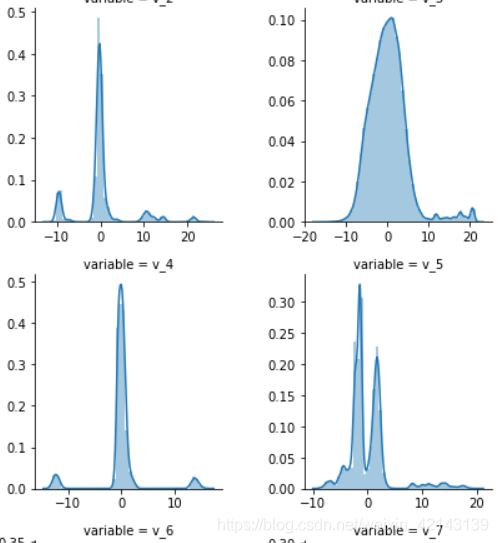
結論:匿名特征(v_*)相對分布均勻
1.2.1.4 *數字特征相互之間的關系可視化(易忽略)
## 4) 數字特征相互之間的關系可視化
sns.set()
columns = ['price', 'v_12', 'v_8' , 'v_0', 'power', 'v_5', 'v_2', 'v_6', 'v_1', 'v_14']
sns.pairplot(Train_data[columns],size = 2 ,kind ='scatter',diag_kind='kde')
plt.show()
1.2.1.5 *多變量互相回歸關系可視化(易忽略)
## 5) 多變量互相回歸關系可視化
fig, ((ax1, ax2), (ax3, ax4), (ax5, ax6), (ax7, ax8), (ax9, ax10)) = plt.subplots(nrows=5, ncols=2, figsize=(24, 20))
# ['v_12', 'v_8' , 'v_0', 'power', 'v_5', 'v_2', 'v_6', 'v_1', 'v_14']
v_12_scatter_plot = pd.concat([Y_train,Train_data['v_12']],axis = 1)
sns.regplot(x='v_12',y = 'price', data = v_12_scatter_plot,scatter= True, fit_reg=True, ax=ax1)
v_8_scatter_plot = pd.concat([Y_train,Train_data['v_8']],axis = 1)
sns.regplot(x='v_8',y = 'price',data = v_8_scatter_plot,scatter= True, fit_reg=True, ax=ax2)
v_0_scatter_plot = pd.concat([Y_train,Train_data['v_0']],axis = 1)
sns.regplot(x='v_0',y = 'price',data = v_0_scatter_plot,scatter= True, fit_reg=True, ax=ax3)
power_scatter_plot = pd.concat([Y_train,Train_data['power']],axis = 1)
sns.regplot(x='power',y = 'price',data = power_scatter_plot,scatter= True, fit_reg=True, ax=ax4)
v_5_scatter_plot = pd.concat([Y_train,Train_data['v_5']],axis = 1)
sns.regplot(x='v_5',y = 'price',data = v_5_scatter_plot,scatter= True, fit_reg=True, ax=ax5)
v_2_scatter_plot = pd.concat([Y_train,Train_data['v_2']],axis = 1)
sns.regplot(x='v_2',y = 'price',data = v_2_scatter_plot,scatter= True, fit_reg=True, ax=ax6)
v_6_scatter_plot = pd.concat([Y_train,Train_data['v_6']],axis = 1)
sns.regplot(x='v_6',y = 'price',data = v_6_scatter_plot,scatter= True, fit_reg=True, ax=ax7)
v_1_scatter_plot = pd.concat([Y_train,Train_data['v_1']],axis = 1)
sns.regplot(x='v_1',y = 'price',data = v_1_scatter_plot,scatter= True, fit_reg=True, ax=ax8)
v_14_scatter_plot = pd.concat([Y_train,Train_data['v_14']],axis = 1)
sns.regplot(x='v_14',y = 'price',data = v_14_scatter_plot,scatter= True, fit_reg=True, ax=ax9)
v_13_scatter_plot = pd.concat([Y_train,Train_data['v_13']],axis = 1)
sns.regplot(x='v_13',y = 'price',data = v_13_scatter_plot,scatter= True, fit_reg=True, ax=ax10)
1.2.2 類別特征分析(會畫,不會利用結果)
對類別特征查看unique分布
## 1) unique分布
for fea in categorical_features:
print(Train_data[fea].nunique())
categorical_features
1.2.2.1 箱形圖可視化
## 2) 類別特征箱形圖可視化
# 因為 name和 regionCode的類別太稀疏了,這里我們把不稀疏的幾類畫一下
categorical_features = ['model',
'brand',
'bodyType',
'fuelType',
'gearbox',
'notRepairedDamage']
for c in categorical_features:
Train_data[c] = Train_data[c].astype('category')
if Train_data[c].isnull().any():
Train_data[c] = Train_data[c].cat.add_categories(['MISSING'])
Train_data[c] = Train_data[c].fillna('MISSING')
def boxplot(x, y, **kwargs):
sns.boxplot(x=x, y=y)
x=plt.xticks(rotation=90)
f = pd.melt(Train_data, id_vars=['price'], value_vars=categorical_features)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False, size=5)
g = g.map(boxplot, "value", "price")
1.2.2.2 小提琴圖可視化
## 3) 類別特征的小提琴圖可視化
catg_list = categorical_features
target = 'price'
for catg in catg_list :
sns.violinplot(x=catg, y=target, data=Train_data)
plt.show()
categorical_features = ['model',
'brand',
'bodyType',
'fuelType',
'gearbox',
'notRepairedDamage']
1.2.2.3 柱形圖可視化類別
## 4) 類別特征的柱形圖可視化
def bar_plot(x, y, **kwargs):
sns.barplot(x=x, y=y)
x=plt.xticks(rotation=90)
f = pd.melt(Train_data, id_vars=['price'], value_vars=categorical_features)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False, size=5)
g = g.map(bar_plot, "value", "price")
1.2.2.4 特征的每個類別頻數可視化(count_plot)
## 5) 類別特征的每個類別頻數可視化(count_plot)
def count_plot(x, **kwargs):
sns.countplot(x=x)
x=plt.xticks(rotation=90)
f = pd.melt(Train_data, value_vars=categorical_features)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False, size=5)
g = g.map(count_plot, "value")
2. *用pandas_profiling生成數據報告(新技能)
pfr = pandas_profiling.ProfileReport(Train_data)
pfr.to_file("./example.html")
3. 小結
本次筆記雖然針對樣本量較少的情況,但仍有一些可貴的思路:
a. 通過檢查nan缺失情況,確定需要進一步處理的特征:
填充(填充方式是什么,均值填充,0填充,眾數填充等);
舍去;
先做樣本分類用不同的特征模型去預測。
b. 通過分布,進行異常檢測
分析特征異常的label是否異常(或者偏離均值較遠或者事特殊符號);
異常值是否應該剔除,還是用正常值填充,等。
c. 通過對laebl作圖,分析標簽的分布情況
d. 通過對特征作圖,特征和label聯合做圖(統計圖,離散圖),直觀了解特征的分布情況,通過這一步也可以發現數據之中的一些異常值等,通過箱型圖分析一些特征值的偏離情況,對于特征和特征聯合作圖,對于特征和label聯合作圖,分析其中的一些關聯性
到此這篇關于Datawhale練習的文章就介紹到這了,更多相關python預測內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章,希望大家以后多多支持腳本之家!
您可能感興趣的文章:- 利用機器學習預測房價
- 如何用Python進行時間序列分解和預測
- 利用keras使用神經網絡預測銷量操作
- 詳解用Python進行時間序列預測的7種方法
- Python實現新型冠狀病毒傳播模型及預測代碼實例
