前言
本文目的:根據本人的習慣與理解,用最簡潔的表述,介紹爬蟲的定義、組成部分、爬取流程,并講解示例代碼。
基礎
爬蟲的定義:定向抓取互聯網內容(大部分為網頁)、并進行自動化數據處理的程序。主要用于對松散的海量信息進行收集和結構化處理,為數據分析和挖掘提供原材料。
今日t條就是一只巨大的“爬蟲”。
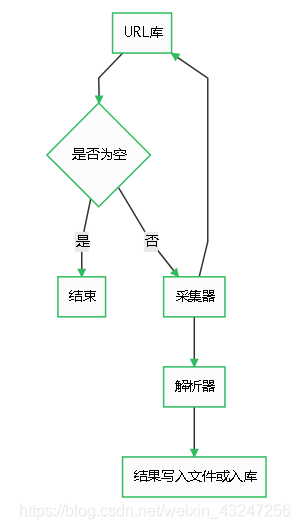
爬蟲由URL庫、采集器、解析器組成。
流程
如果待爬取的url庫不為空,采集器會自動爬取相關內容,并將結果給到解析器,解析器提取目標內容后進行寫入文件或入庫等操作。
代碼
第一步:寫一個采集器
如下是一個比較簡單的采集器函數。需要用到requests庫。
首先,構造一個http的header,里面有瀏覽器和操作系統等信息。如果沒有這個偽造的header,可能會被目標網站的WAF等防護設備識別為機器代碼并干掉。
然后,用requests庫的get方法獲取url內容。如果http響應代碼是200 ok,說明頁面訪問正常,將該函數返回值設置為文本形式的html代碼內容。
如果響應代碼不是200 ok,說明頁面不能正常訪問,將函數返回值設置為特殊字符串或代碼。
import requests
def get_page(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'}
response = requests.get(url, headers= headers)
if response.status_code == 200:
return response.text
else:
return 'GET HTML ERROR !'
第二步:解析器
解析器的作用是對采集器返回的html代碼進行過濾篩選,提取需要的內容。
作為一個14年忠實用戶,當然要用豆瓣舉個栗子 _
我們計劃爬取豆瓣排名TOP250電影的8個參數:排名、電影url鏈接、電影名稱、導演、上映年份、國家、影片類型、評分。整理成字典并寫入文本文件。
待爬取的頁面如下,每個頁面包括25部電影,共計10個頁面。
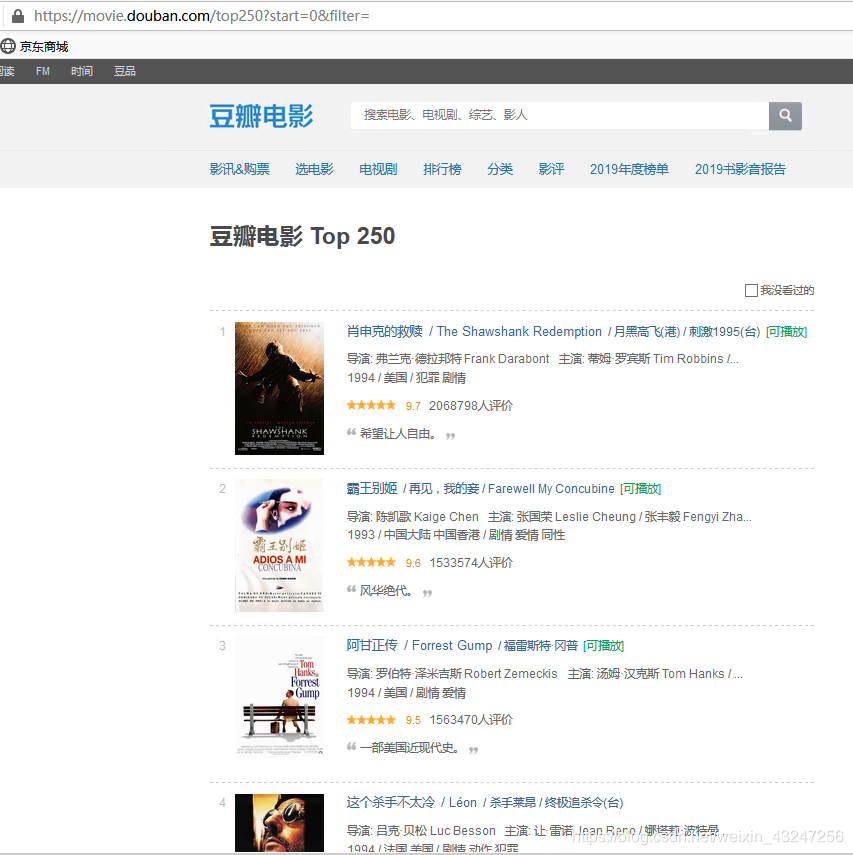
在這里,必須要表揚豆瓣的前端工程師們,html標簽排版非常工整具有層次,非常便于信息提取。
下面是“肖申克的救贖”所對應的html代碼:(需要提取的8個參數用紅線標注)
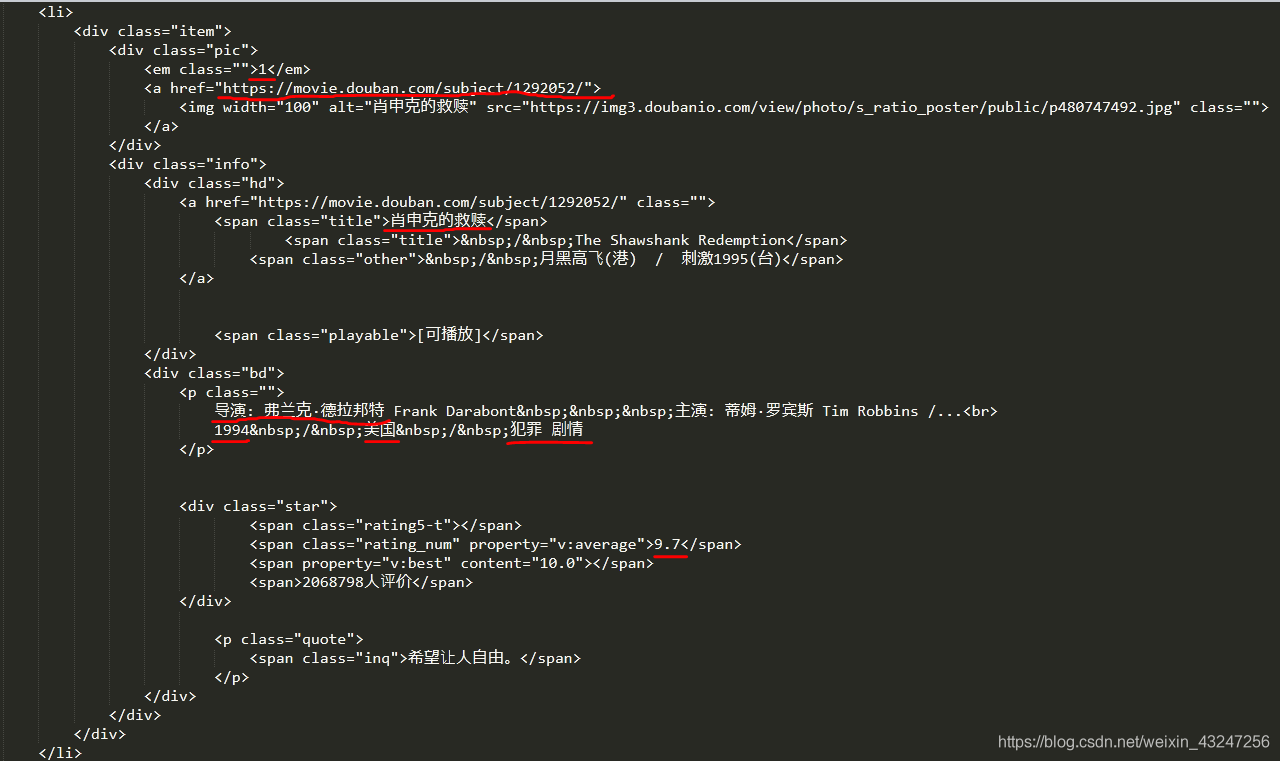
根據上面的html編寫解析器函數,提取8個字段。該函數返回值是一個可迭代的序列。
我個人喜歡用re(正則表達式)提取內容。8個(.*?)分別對應需要提取的字段。
import re
def parse_page(html):
pattern = re.compile('em class="">(.*?)/em>.*?a href="(.*?)" rel="external nofollow" rel="external nofollow" >.*?span class="title">(.*?)/span>.*?div class="bd">.*?p class="">(.*?)nbsp.*?br>(.*?)nbsp;/nbsp;(.*?)nbsp;/nbsp;(.*?)/p>.*?span class="rating_num".*?"v:average">(.*?)/span>' , re.S)
items = re.findall(pattern , html)
for item in items:
yield {
'rank': item[0],
'href': item[1],
'name': item[2],
'director': item[3].strip()[4:],
'year': item[4].strip(),
'country': item[5].strip(),
'style': item[6].strip(),
'score': item[7].strip()
}
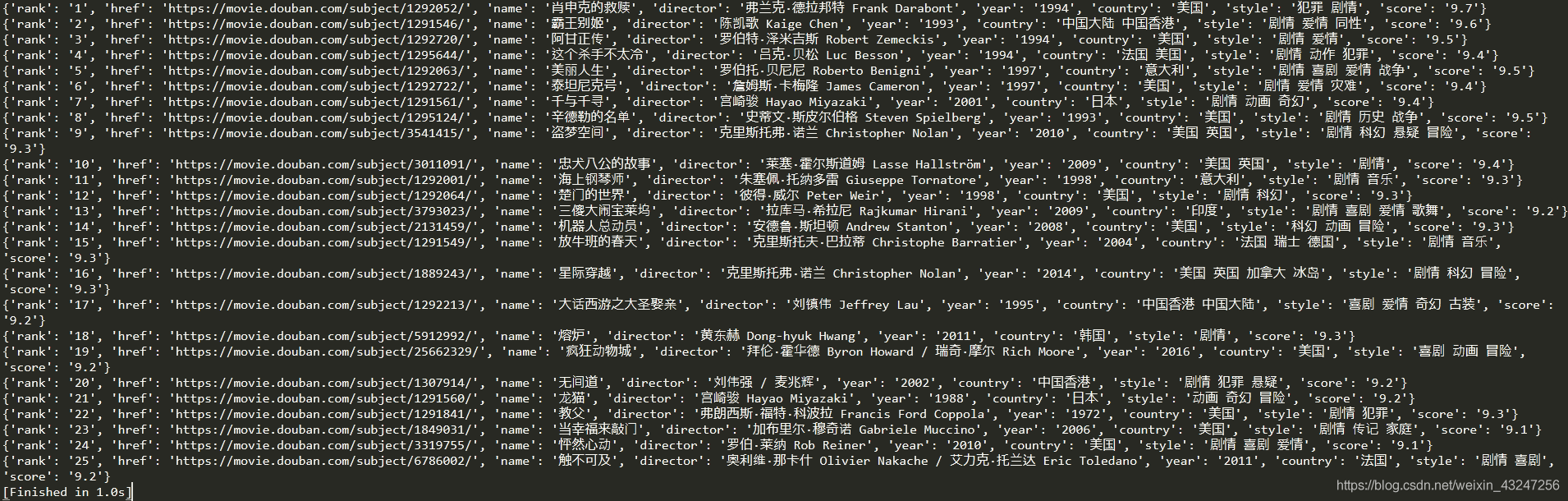
提取后的內容如下:
整理成完整的代碼:(暫不考慮容錯)
import requests
import re
import json
def get_page(url):
#采集器函數
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'}
response = requests.get(url, headers= headers)
if response.status_code == 200:
return response.text
else:
return 'GET HTML ERROR ! '
def parse_page(html):
#解析器函數
pattern = re.compile('em class="">(.*?)/em>.*?a href="(.*?)" rel="external nofollow" rel="external nofollow" >.*?span class="title">(.*?)/span>.*?div class="bd">.*?p class="">(.*?)nbsp.*?br>(.*?)nbsp;/nbsp;(.*?)nbsp;/nbsp;(.*?)/p>.*?span class="rating_num".*?"v:average">(.*?)/span>' , re.S)
items = re.findall(pattern , html)
for item in items:
yield {
'rank': item[0],
'href': item[1],
'name': item[2],
'director': item[3].strip()[4:],
'year': item[4].strip(),
'country': item[5].strip(),
'style': item[6].strip(),
'score': item[7].strip()
}
def write_to_file(content):
#寫入文件函數
with open('result.txt' , 'a' , encoding = 'utf-8') as file:
file.write(json.dumps(content , ensure_ascii = False) + '\n')
if __name__== "__main__":
# 主程序
for i in range(10):
url= 'https://movie.douban.com/top250?start='+ str(i*25)+ 'filter'
for res in parse_page(get_page(url)):
write_to_file(res)
非常簡潔,非常符合python簡單、高效的特點。
說明:
需要掌握待爬取url的規律,才能利用for循環等操作自動化處理。
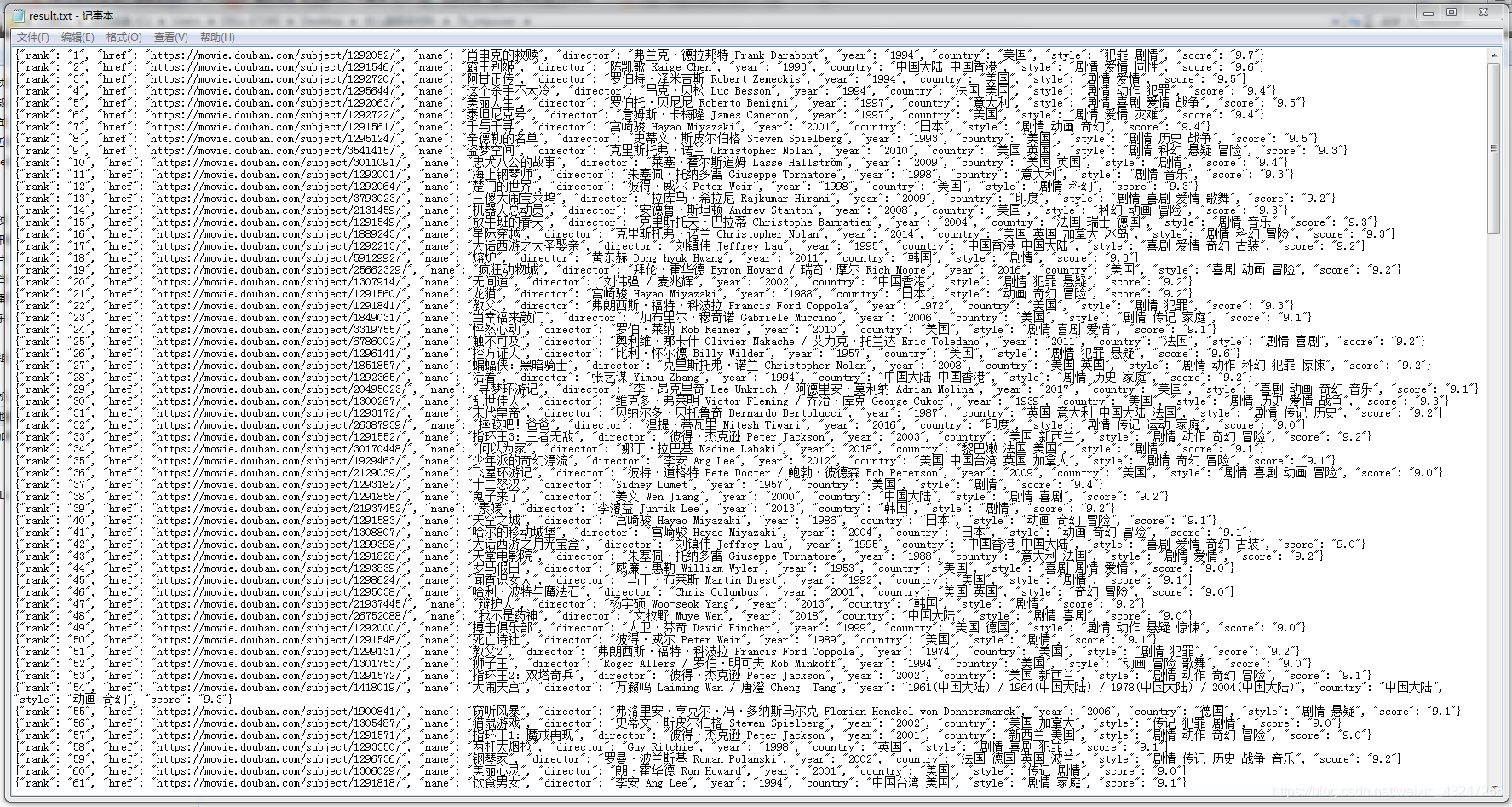
前25部影片的url是https://movie.douban.com/top250?start=0filter,第26-50部影片url是https://movie.douban.com/top250?start=25filter。規律就在start參數,將start依次設置為0、25、50、75。。。225,就能獲取所有頁面的鏈接。parse_page函數的返回值是一個可迭代序列,可以理解為字典的集合。運行完成后,會在程序同目錄生成result.txt文件。內容如下:
到此這篇關于一個入門級python爬蟲教程詳解的文章就介紹到這了,更多相關python爬蟲入門教程內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- python從入門到精通 windows安裝python圖文教程
- Python面向對象思想與應用入門教程【類與對象】
- 一小時快速入門Python教程
