目錄
- 1、 需求說明
- 2、實現思路
- 2.1分區原理
- 2.2 水平分區優點
- 2.3 實現思路
- 3、實現步驟
- 3.1代碼創建分區表
- 3.1.1 創建數據庫
- 3.1.2 添加文件組
- 3.1.3 添加文件
- 3.1.4 定義分區函數
- 3.1.5 定義分區架構
- 3.1.6 定義分區表
- 3.2 界面向導表分區
- 3.2.1 創建數據庫
- 3.2.2 創建文件組
- 3.2.3 添加文件
- 3.2.4 定義分區表
- 3.2.5 添加分區函數和分區架構
- 3.3 動態添加分割點
- 4、測試數據
- 4.1 添加測試數據
- 4.1.1 新建測試表
- 4.1.2 編寫T-SQL添加測試數據
- 5、補充說明
- 5.1 分區分表理解
- 5.2 水平分區分表疑惑
- 5.3 其它說明
1、 需求說明
將數據庫Demo中的表按照日期字段進行水平分區分表。要求數據文件按一年一個文件存儲,且分區的分割點會根據時間的增長自動添加(例如現在是2017年1月1日,將其作為一個分割點,即將2017年1月1日之前的數據存儲到數據文件A中,將2017年1月1日的之后的數據存儲到數據文件B中;當時間到2018年1月1日時,自動將2018年1月1日添加為一個新的分區分割點,并將2017年1月1日至2018年1月1日的數據存儲在數據文件B中,將2018年1月1日之后的數據存儲在一個新的數據文件C中,以此類推)。
2、實現思路
2.1分區原理
要實現這一功能,首先要了解數據庫對水平分區表進行分區存儲的原理。
所謂水平分區分表,就是把邏輯上的一個表,在物理上按照你指定的規則分放到不同的文件里,把一個大的數據文件拆分為多個小文件,還可以把這些小文件放在不同的磁盤下。這樣把一個大的文件拆分成多個小文件,便于我們對數據的管理。
2.2 水平分區優點
l 便于存檔
l 便于管理:備份恢復時可以單一的備份或者恢復某一個分區
l 提高可用性:一個分區故障,不影響其他分區的正常使用
l 提高性能:提升查詢數據的速度
2.3 實現思路
① 創建數據庫
② 在創建的數據庫中添加文件組
③ 在文件組中添加新的文件
④ 定義分區函數
⑤ 定義分區架構
⑥ 定義分區表
⑦ 定義代理作業,自動添加分區分割點
⑧ 測試數據
注意:
² 分區表依賴于分區架構,而分區架構又依賴與分區函數,所以在穿件分區函數、分區架構、分區表是要按照對應的順序創建。
² 分區函數并不屬于具體的分區架構和分區表,它們之間僅僅是使用關系。
² 分區表只能在創建的時候指定為分區表
3、實現步驟
3.1代碼創建分區表
3.1.1 創建數據庫
新建數據庫,并將其命名為Demo
3.1.2 添加文件組
代碼格式:
ALTER DATABASE 數據庫名稱> ADD FILEGROUP文件組名>
代碼示例:
ALTER DATABASE DemoADD FILEGROUP DemoFileGroup
3.1.3 添加文件
代碼格式:
ALTER DATABASE 數據庫名稱> ADD FILE 數據標識> TO FILEGROUP文件組名稱>
注意:數據標識中name為邏輯文件名、filename為物理文件路徑名、size為文件初始大小(單位:kb/mb/gb/tb)、filegrowth為文件自動增量(單位:kb/mb/gb/tb)、maxsize為文件增大的最大大小(單位:kb/mb/gb/tb/unlimited)
代碼示例:
ALTER DATABASEDemo ADD FILE (
NAME='DemoFile1',
FILENAME='D:\ProgramFiles\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\DemoFile1.mdf',
SIZE=5MB,
FILEGROWTH=5MB)
TOFILEGROUP DemoFileGroup
在此我們重復執行示例代碼,在示例文件組下添加三個文件。
3.1.4 定義分區函數
分區函數是用于判定數據行該屬于哪個分區,通過分區函數中設置邊界值來使得根據行中特定列的值來確定其分區。
代碼格式:
CREATE PARTITIONFUNCTION partition_function_name( input_parameter_type )
ASRANGE [ LEFT | RIGHT ]
FORVALUES ( [ boundary_value [ ,...n ] ] )
[ ; ]
其中“LEFT”和“RIGHT”決定了“VALUES”中的邊界值被劃分到哪一個分區中(即,邊界值屬于左側分區還是右側分區)。
代碼示例:
CREATE PARTITIONFUNCTION DemoPartitionFunction( datetime2(0) )
ASRANGE RIGHT
FORVALUES ('2016-01-01 00:00:00','2017-01-01 00:00:00')
查看分區函數是否創建成功:
SELECT * FROM sys.partition_functions
3.1.5 定義分區架構
定義完分區函數僅僅是知道了如何將列的值區分到了不同的分區,而每個分區的存儲方式,則需要分區構架來定義。分區構架僅僅是依賴分區函數.分區構架中負責分配每個區屬于哪個文件組,而分區函數是決定如何在邏輯上分區。
代碼格式:
CREATE PARTITIONSCHEME partition_scheme_name
ASPARTITION partition_function_name
[ ALL ]TO ( { file_group_name | [ PRIMARY ] } [ ,...n ] )
[ ; ]
代碼示例:
CREATE PARTITIONSCHEME DemoPartitionScheme
ASPARTITION DemoPartitionFunction
TO ( DemoFileGroup,[PRIMARY],DemoFileGroup)
查看分區架構是否創建完成:
SELECT * FROM sys.partition_schemes
3.1.6 定義分區表
表在創建的時候就已經決定是否是分區表了。雖然在很多情況下都是你在發現已經表已經足夠大的時候才想到要把表分區,但是分區表只能夠在創建的時候指定為分區表。
代碼格式:
CREATE TABLEtable_name(
...
) ONpartition_scheme_name(column_name)
代碼示例:
CREATE TABLEDemoTable(
demo_id BIGINT,
demo_date datetime2(0),
demo_desc varchar(50)
) ONDemoPartitionScheme(demo_date)
3.2 界面向導表分區
在3.4、3.5、3.6中,我們已經詳細的描述了如何定義分區函數、分區架構以及分區表,但這些都是通過代碼實現的,下面,我們來通過SQL Server 2012 Management Studio的界面向導創建分區表。
3.2.1 創建數據庫
右鍵點擊“數據庫”,選擇第一項“新建數據庫(N)…”,新建數據庫,如圖1所示:
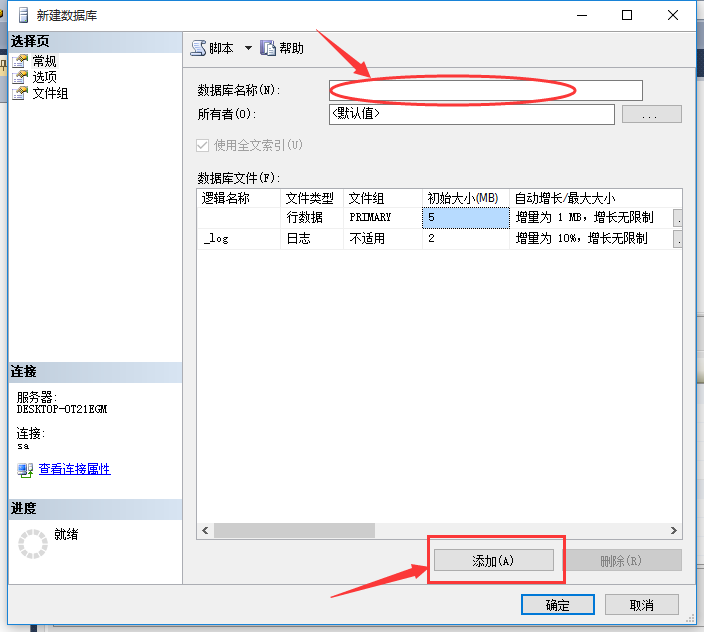
圖1 新建數據庫
3.2.2 創建文件組
右鍵數據庫Demo,選擇“屬性”,如圖2所示:
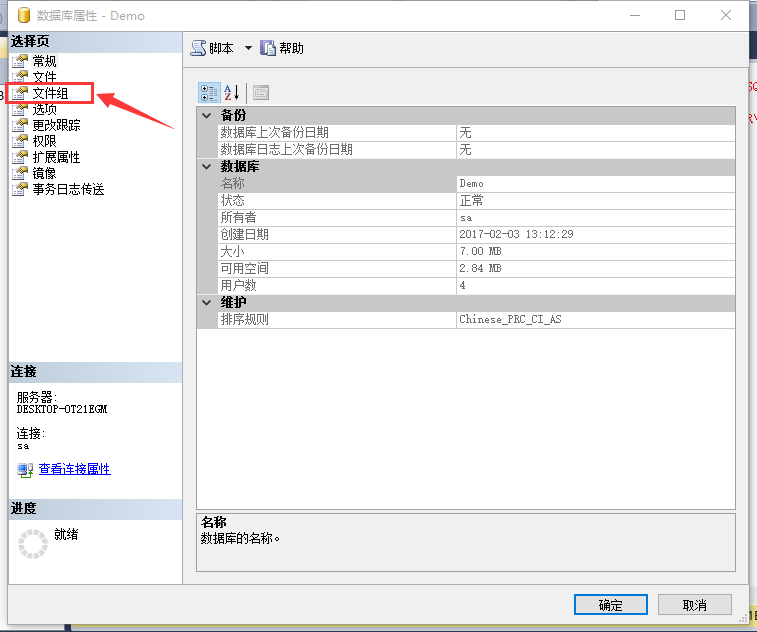
圖2 數據庫屬性界面
在屬性界面中,點擊箭頭所示的“文件組”選項,進入文件組編輯界面,如圖3所示:
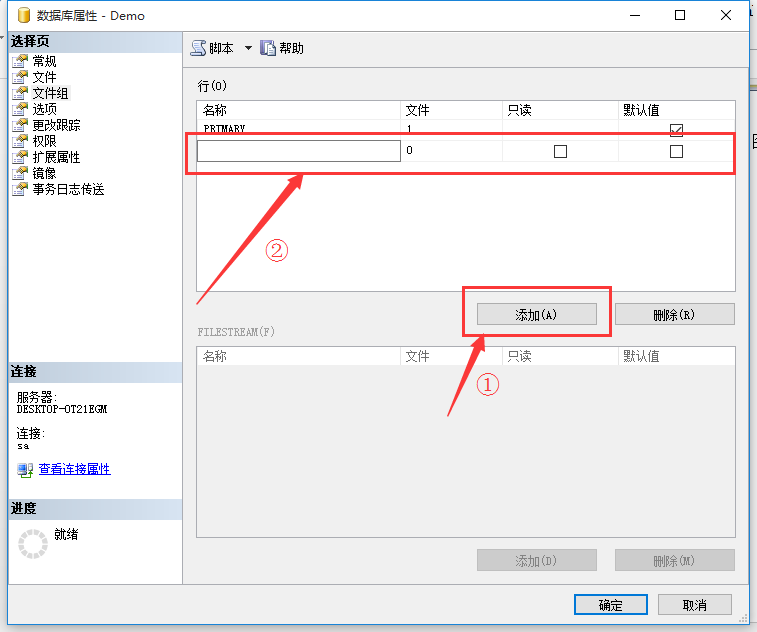
圖3 文件組管理界面
在文件組管理界面中點擊箭頭①所示的“添加”選項,添加新的文件組,界面中會出現箭頭②所示的屬性框,并鍵入對應的屬性值,之后點擊“確定”,完成新建文件組。
3.2.3 添加文件
和添加文件組的方式一樣,右鍵數據庫Demo,選擇“屬性”,打開數據庫屬性界面,這次選擇“文件”,打開文件管理界面,如圖4所示:
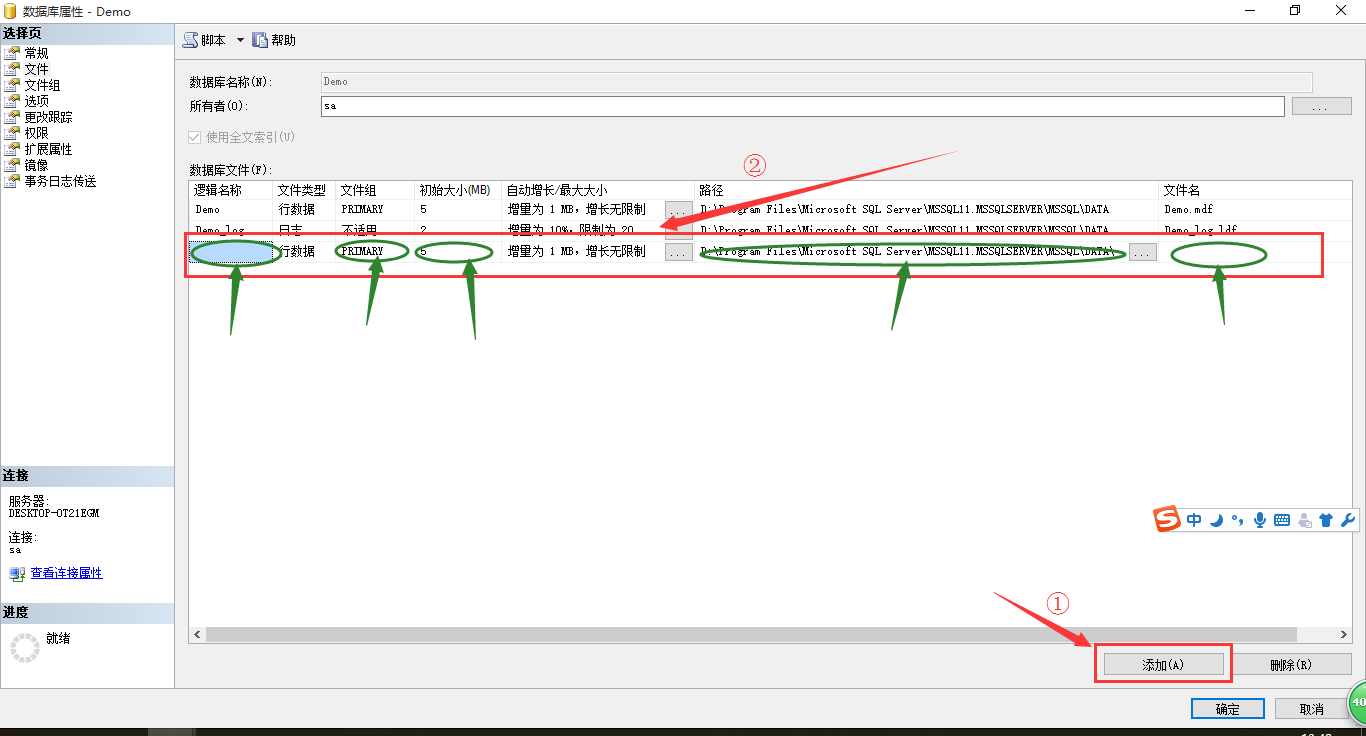
圖4 文件管理界面
在文件管理界面中,點擊箭頭①所示的“添加”選項,添加新的文件,在新添加的箭頭②所示的區域,根據實際需求,填寫對應的文件屬性值,填寫完成后點擊“確定”。其中,一個文件組中可以添加多個文件,即“文件組”屬性的值是可以重復的。
3.2.4 定義分區表
在SQL Server 2012 Management Studio的界面中,找到目標數據庫下的“表”菜單,右鍵點擊,選擇“新建數據庫表”,打開新建數據庫表界面,新建一個分區表。如圖5所示:
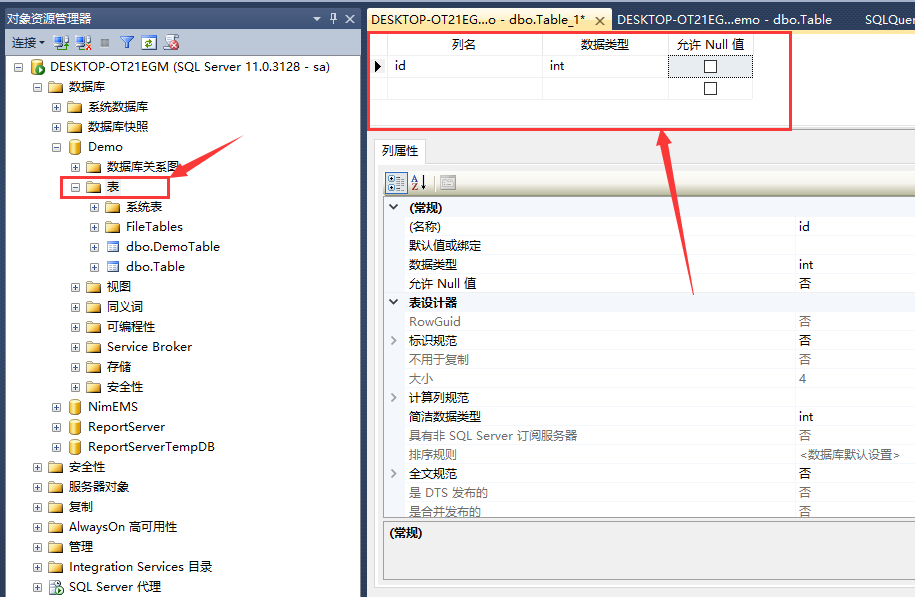
圖5 新建數據庫表
3.2.5 添加分區函數和分區架構
完成新建分區表后,我們就可以在分區表上添加分區函數和分區架構了。右鍵點擊分區表,選擇“存儲”,然后選擇“創建分區”,開始添加分區函數和分區架構,如圖6所示:
圖6 新建分區界面
點擊“下一步”,如圖7所示:
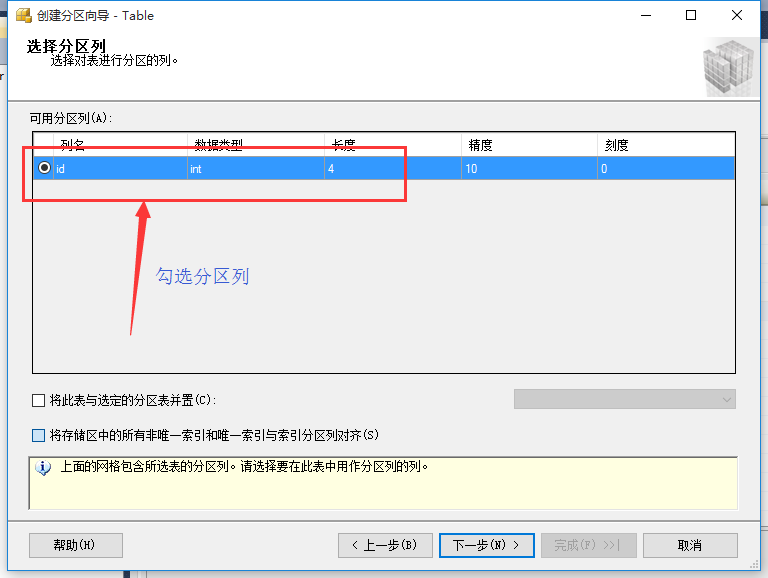
圖7 選擇分區列
在圖7所示的界面中,勾選分區列,勾選完成后,選擇“下一步”,如圖8所示:
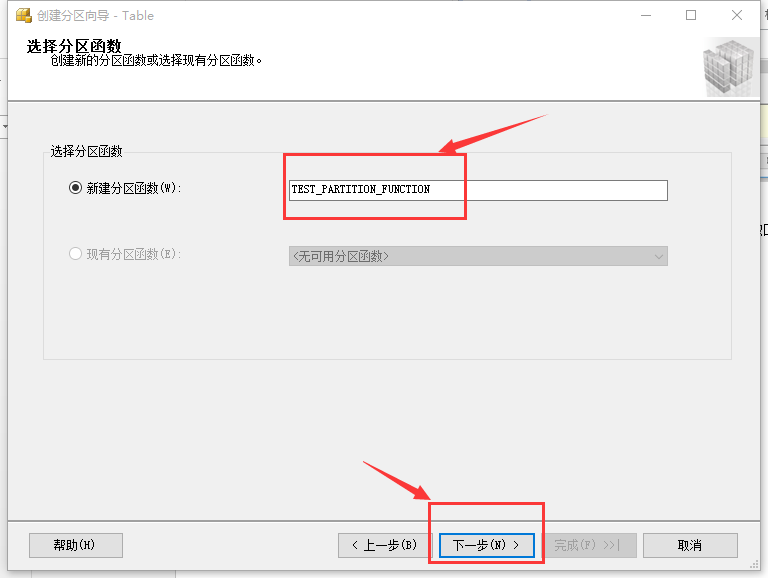
圖8 填寫分區函數
在圖8所示的界面填寫分區函數名稱,填寫完成后點擊“下一步”,如圖9所示:
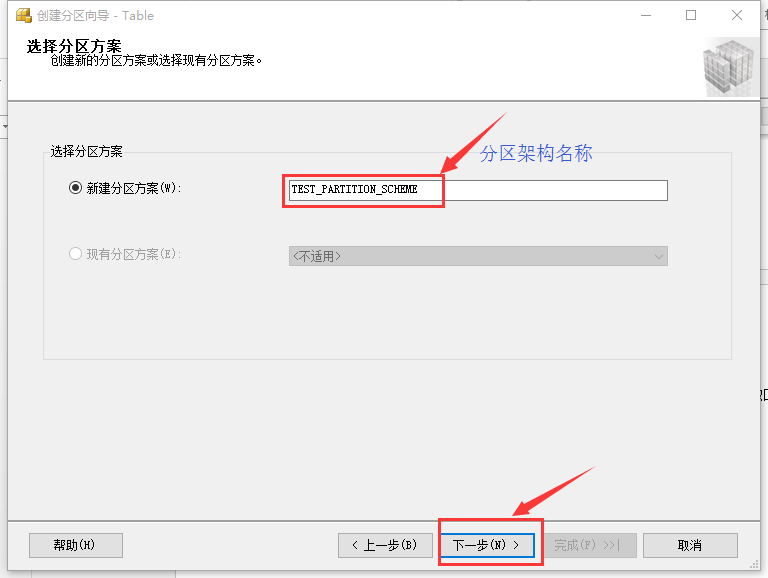
圖9 填寫分區架構
在圖9所示的界面中填寫需要創建的分區架構的名稱,填寫完成后點擊“下一步”,如圖10所示:
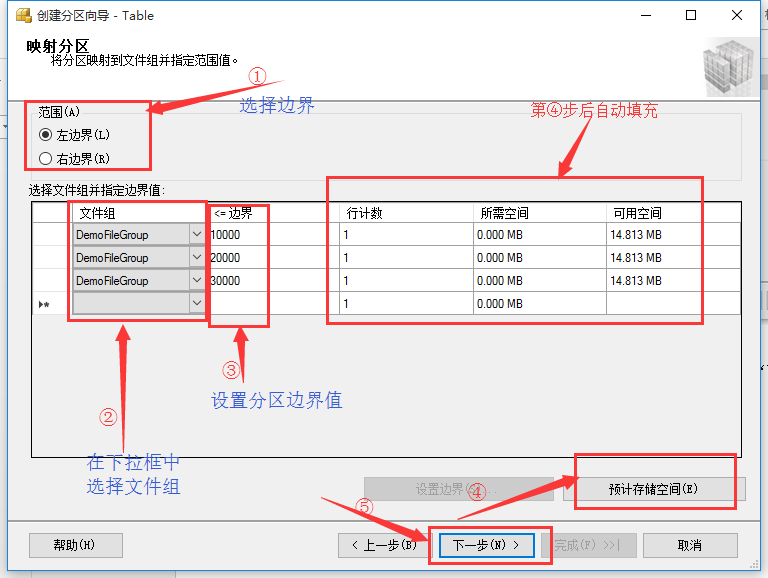
圖10 指定文件組
如圖10所示,按照圖示箭頭步驟,一步步設置文件組參數。首先選擇分區邊界值劃分在左邊界分區還是右邊界分區,然后進行第二步,設置分區所屬文件組,再設置分區邊界值(該值要與分區表的分區字段類型對應),最后點擊“預計存儲空間(E)”對其他參數進行自動填充。設置完成后點擊“下一步”,如圖11所示:
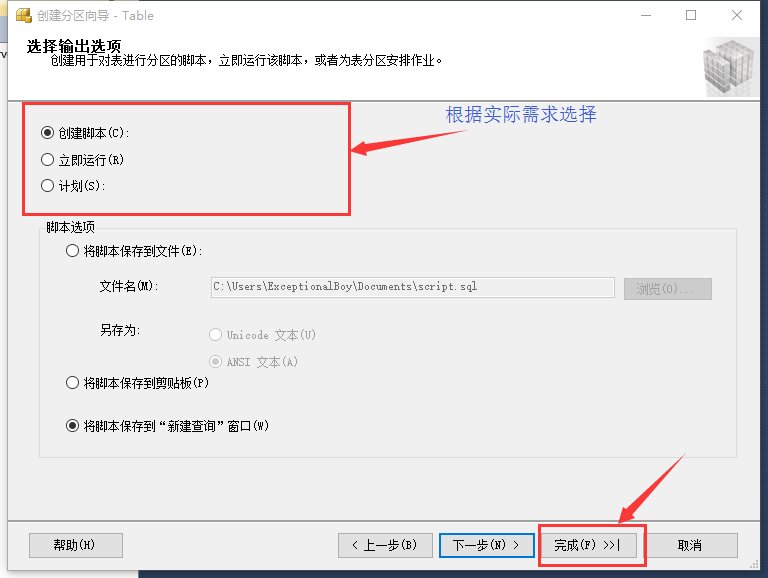
圖11 腳本設置
在圖11所示的界面中,根據實際需求完成最后的設置(一般不做設置),然后點擊“完成”,在下一個界面中再次點擊“完成”,然后等待數據庫執行操作,最后關閉界面。
分區完成后,右鍵點擊分區表,選擇“屬性”,然后選擇“存儲”,打開如圖12所示界面:
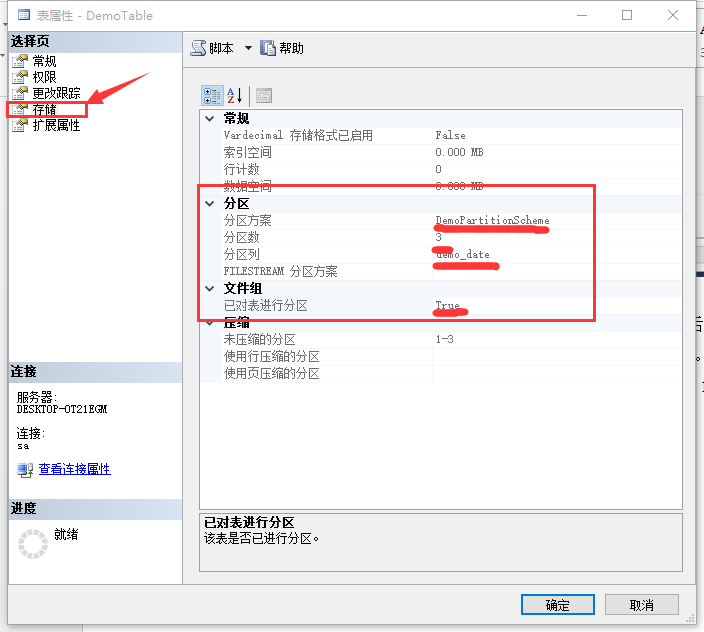
圖12 表分區查看
從圖12中可以看到數據庫表已經完成分區。
3.3 動態添加分割點
要完成動態的向分區函數中添加分割點的功能,首先我們來理一下思路:首先我們要向文件組中添加一個新的文件或者直接添加一個新的文件組,添加完成后,需要修改分區架構,來告知數據庫新分的分區數據存儲到那個文件或者文件組中,最后在分區函數中添加新的分割點,完成動態添加分區分割點的功能。
根據這個思路,我編寫的了一個存儲過程,用于動態的添加分割點:
CREATE proc[dbo].[Demo_FileGroup_Add]
as
declare
@file_name varchar(20),--要添加的文件名稱
@add_sql nvarchar(max)--在文件組下添加新文件的SQL語句
begin
set @file_name='DemoFile'+left((convert(varchar,(DATEADD(yy, DATEDIFF(yy,0,(DATEADD(YY,1,GETDATE()))), 0)),120)),4)--動態拼接文件名
set @add_sql='
ALTER DATABASE Demo ADD FILE (
NAME='+@file_name+',
FILENAME=''D:\ProgramFiles\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\'+@file_name+'.mdf'',
SIZE=5MB,
FILEGROWTH=5MB)
TO FILEGROUP DemoFileGroup'
--select @add_sql
Exec sp_executesql@add_sql--執行向文件組中添加文件的SQL語句
alter partitionscheme DemoPartitionSchemenext used 'DemoFileGroup' --告知數據庫新建立的分區放在哪個文件組(修改分區架構)
alter partitionfunction DemoPartitionFunction() split range (CONVERT(VARCHAR,DATEADD(yy, DATEDIFF(yy,0,(DATEADD(YY,1,GETDATE()))), 0),120))--在分區函數中添加分割點
end
注意:在執行該存儲過程之前,一定要確保文件組中沒有即將添加的文件,并且在分區函數中,沒有要添加的分割點,否則會報錯,存儲過程不能執行。
4、測試數據
4.1 添加測試數據
4.1.1 新建測試表
新建一個未分區的TestTable表,其表結構與分區表DemoTable表結構完全一致,代碼如下:
CREATE TABLE[dbo].[TestTable](
[demo_id][bigint],
[demo_date][datetime2](0),
[demo_desc][varchar](50)
)
4.1.2 編寫T-SQL添加測試數據
T-SQL語句如下:
declare
@num bigint, --id
@test_date datetime2(0),--時間
@test_desc varchar(300),--描述
@count int--計數器
begin
set @num= 0 --設置初始id
set @test_date= '2015-01-01 00:00:00'--設置初始日期
set @test_desc='屈賈誼于長沙,無非明主;竄梁鴻于海曲,豈乏明時?'
while (@test_date'2019-01-01 00:00:00') --設置日期上限
begin
set@count = 0
while(@count10)--每個時間點添加10條數據
begin
insertinto dbo.DemoTable values(@num,@test_date,@test_desc+CAST(@count as varchar)) --添加數據
set@count=@count+1 --計數自增
set@num = @num +1 --id自增
end
set@test_date = DATEADD(MI,1,@test_date) --每一個時間點添加完10條數據后,時間自增1分
end
end
修改T-SQL語句中insert部分的表明,分別向兩張表中添加測試數據,添加21038400行數據,結果如下:
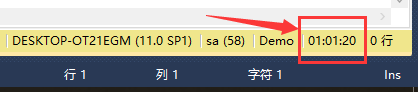
圖13 分區表插入數據耗時統計
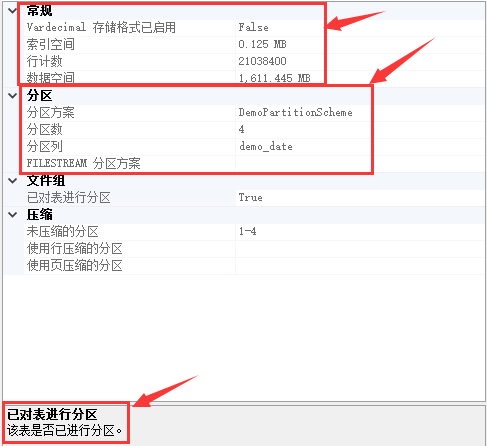
圖14 分區表存儲信息
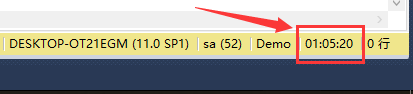
圖15 普通表插入數據耗時統計

圖16 普通表存儲信息
從圖13與圖15中可以看出,同樣插入21038400行數據,分區表耗時3740秒,普通表耗時3920秒,分區表快4.6%。考慮到運行環境對測試數據的影響,在此我們先對此數據不做評價,畢竟4.6%不是很明顯。
而從圖14與圖16的對比中可以看出,分區表的索引空間為0.125MB,而普通表的索引空間為0.008MB。那么為什么分區表的索引空間要比普通表的索引空間大呢?其實這個問題個人理解大致是:創建分區表就是將數據存儲在不同的文件中,然后數據庫會根據分區函數和分區架構,以分區列為索引列,創建分區索引來管理數據存放的位置,所以分區表的索引空間理所當然會比普通標表的索引空間大。
默認情況下,分區表中創建的索引使用與分區表相同分區架構和分區列,這樣,索引將于表對齊。將表與其索引對齊,可以使管理工作更容易進行,對于滑動窗口方案尤其如此。若要啟動分區切換,表的所有索引都必須對齊。
在創建索引時,也可以指定不同的分區方案(Schema)或單獨的文件組(FileGroup)來存儲索引,這樣SQL Server 不會將索引與表對齊。
在已分區的表上創建索引(分區索引)時,應該注意以下事項:
l 唯一索引
建立唯一索引(聚集或者非聚集)時,分區列必須出現在索引列中。此限制將使SQL Server只調查單個分區,并確保表中寵物的新鍵值。如果分區依據列不可能包含在唯一鍵中,則必須使用DML觸發器,而不是強制實現唯一性。
l 非唯一索引
對非唯一的聚集索引進行分區時,如果未在聚集鍵中明確指定分區依據列,默認情況下SQL Server 將在聚集索引列中添加分區依據列。
對非唯一的非聚集索引進行分區時,默認情況下SQL Server 將分區依據列添加為索引的包含性列,以確保索引與基表對齊,若果索引中已經存在分區依據列,SQL Server 將不會像索引中添加分區依據列。
5、補充說明
5.1 分區分表理解
分區分表分為垂直分區分表和水平分區分表,根據我自己查閱資料,總結如下:
垂直分區分表是在SQL Server 2005之前大量使用的,垂直分表相對很少見到和用到,因為這可能是數據庫設計上的問題了。如果數據庫中一張表有部分字段幾乎從不不更改但經常查詢,而部分字段的數據頻繁更改,這種設計放到同一個表中就不合理了,相互影響太大了。在已存在改情況的表的時候,可以考慮按列拆分表,即垂直拆分。拆分完成后,通過分表之間設置外鍵關聯,然后創建視圖和觸發器等對表進行增、刪、改、查操作。
而水平分區分表是SQL Server2005之后被大量使用的。其原理就是將邏輯上的一個表,在物理上拆分,將數據存儲在不同的文件組中,這個我們前邊已經講過了,這里就不在贅述。
5.2 水平分區分表疑惑
在自己學習水平分區分表的過程中發現一個問題,描述如下:
在創建分區表的時候,似乎可以將不同分區的數據存放在同一個文件組下的不同文件中,也可以將不同分區的數據分別存放在不同的文件組,那么這兩種存儲數據的方式對數據查詢的性能有影響嗎?
這個問題我覺得可以做一個小小的測試。
5.3 其它說明
學習是永無止境的,這篇文章只是我個人在學習SQL Server水平分區分表的時候做的一些總結,其中添加了一些個人理解,如果有不對的地方,歡迎與我交流,大家相互學習,共同進步。
