前言
基本職場上的程序員用來統計數據庫表的行數都會使用count(*)�����,count(1)或者count(主鍵)����,那么它們之間的區別和性能你又是否了解呢�����?
其實程序員在開發的過程中�����,在一張大表上統計總行數是非常耗時的一個操作�,那么我們應該用哪個方法統計會更快呢�?
接下來我們就來聊一聊MySQL中統計總行數的方法和性能。
count(*)����,count(1)�,count(主鍵)哪個更快���?
1、建表并且插入1000萬條數據進行實驗測試:
# 創建測試表
CREATE TABLE `t6` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL,
`status` tinyint(4) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_status` (`status`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
# 創建存儲過程插入1000w數據
CREATE PROCEDURE insert_1000w()
BEGIN
DECLARE i INT;
SET i=1;
WHILE i=10000000 DO
INSERT INTO t6(name,status) VALUES('god-jiang-666',1);
SET i=i+1;
END WHILE;
END;
#調用存儲過程,插入1000萬行數據
call insert_1000w();
2���、分析實驗結果
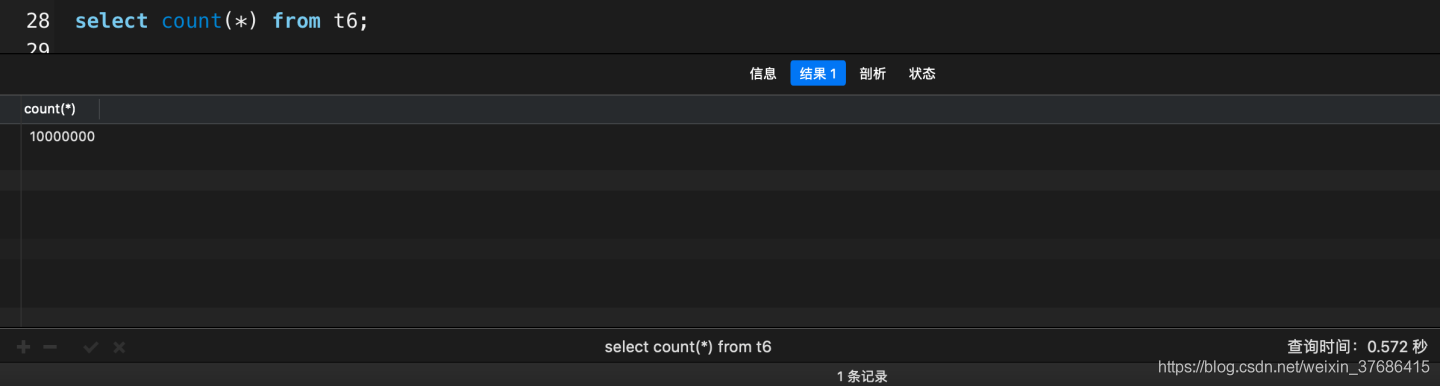
# 花了0.572秒
select count(*) from t6;
# 花了0.572秒
select count(1) from t6;
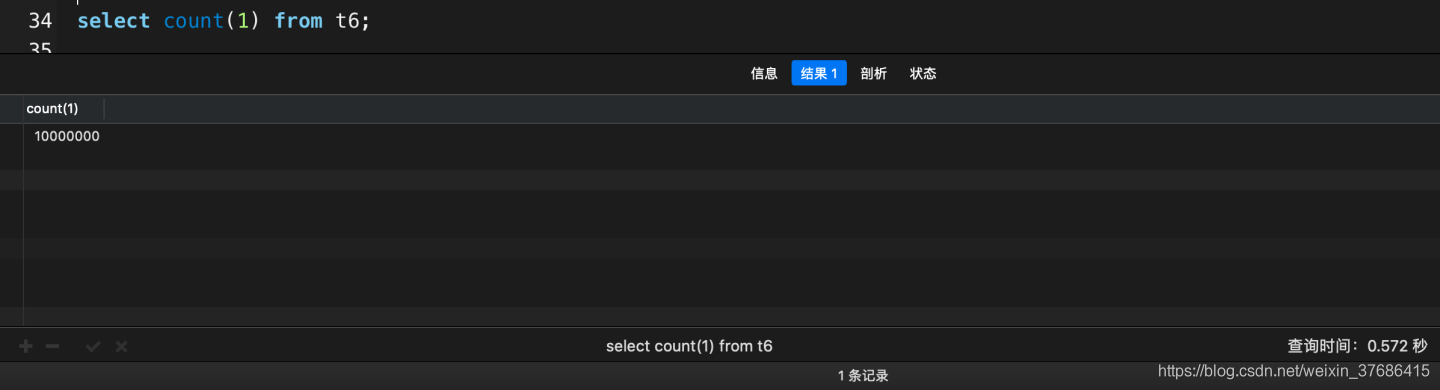
# 花了0.580秒
select count(id) from t6;

# 花了0.620秒
select count(*) from t6 force index (primary);
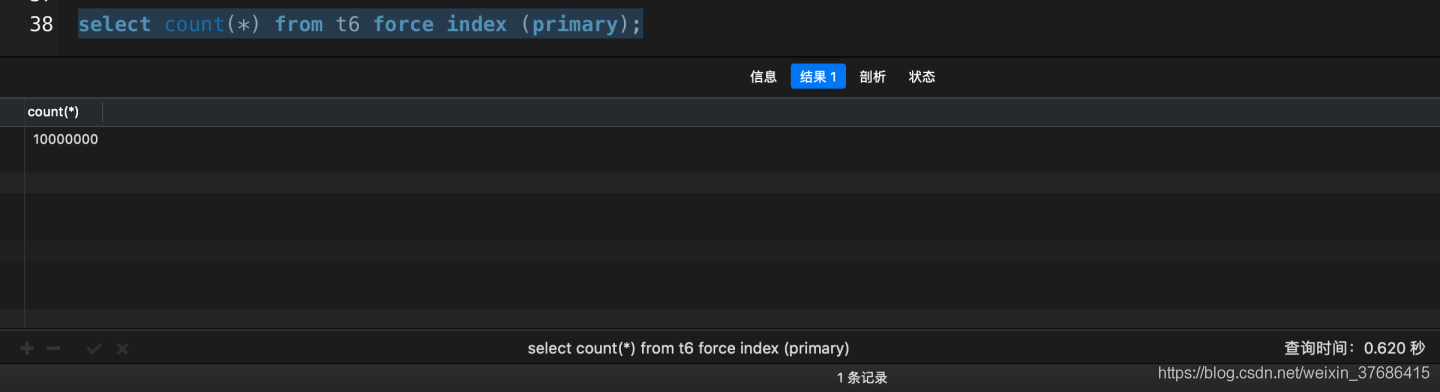
從上面的實驗我們可以得出,count(*)和count(1)是最快的,其次是count(id)���,最慢的是count使用了強制主鍵的情況��。
下面我們繼續測試一下它們各自的執行計劃:
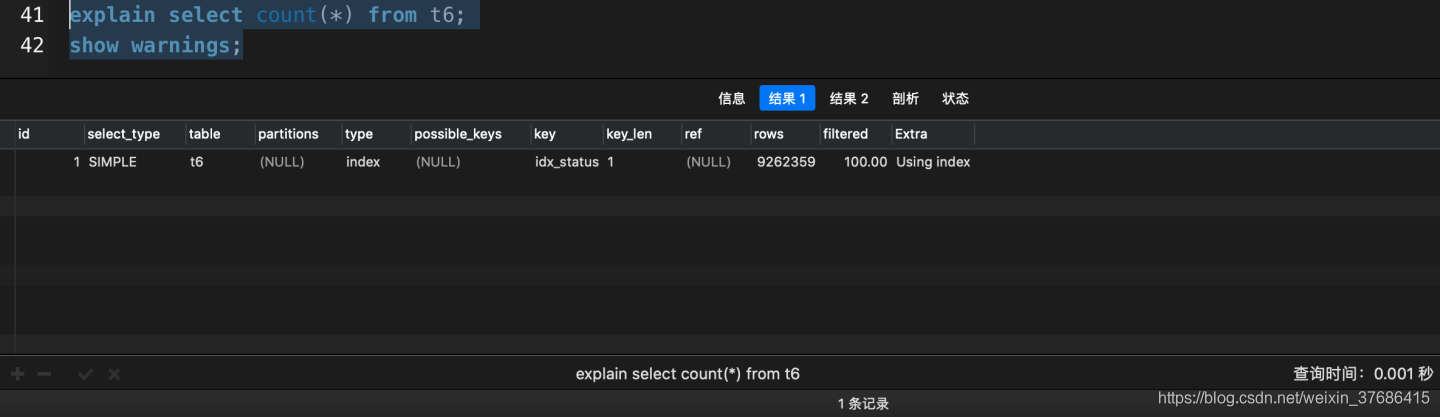
explain select count(*) from t6;
show warnings;
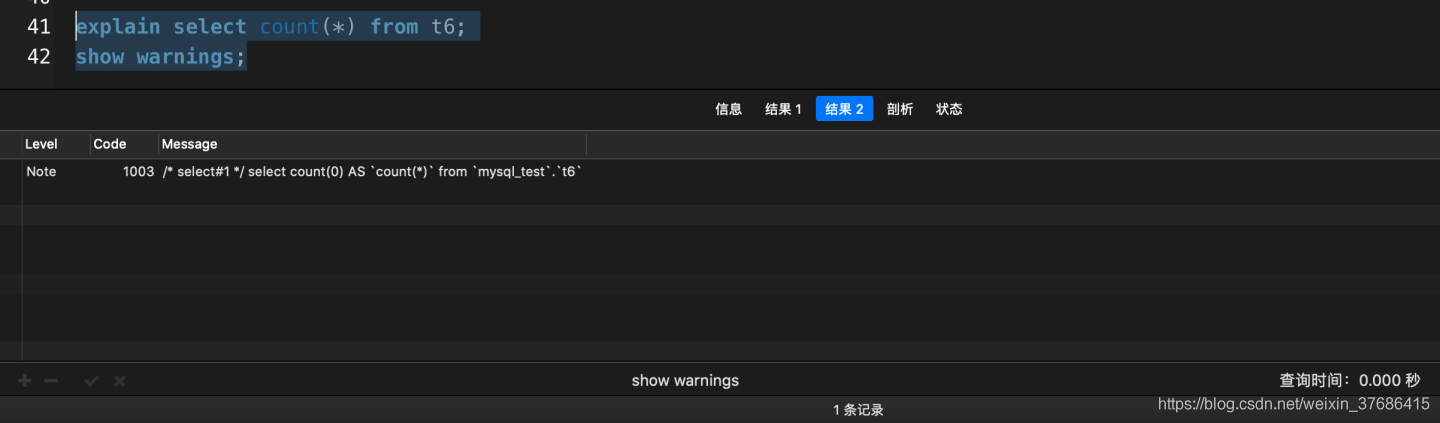
explain select count(1) from t6;
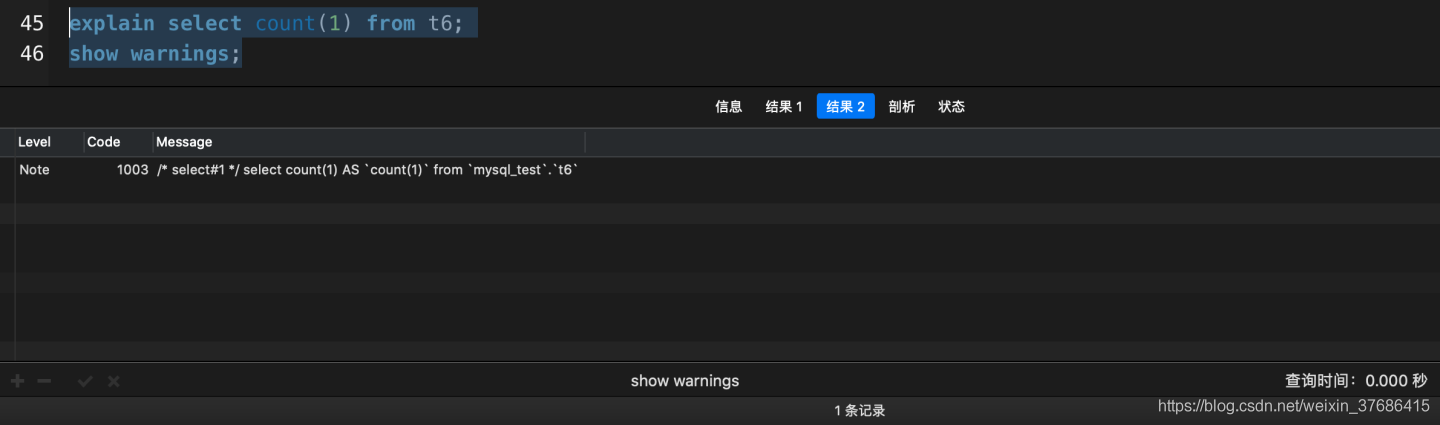
show warnings;

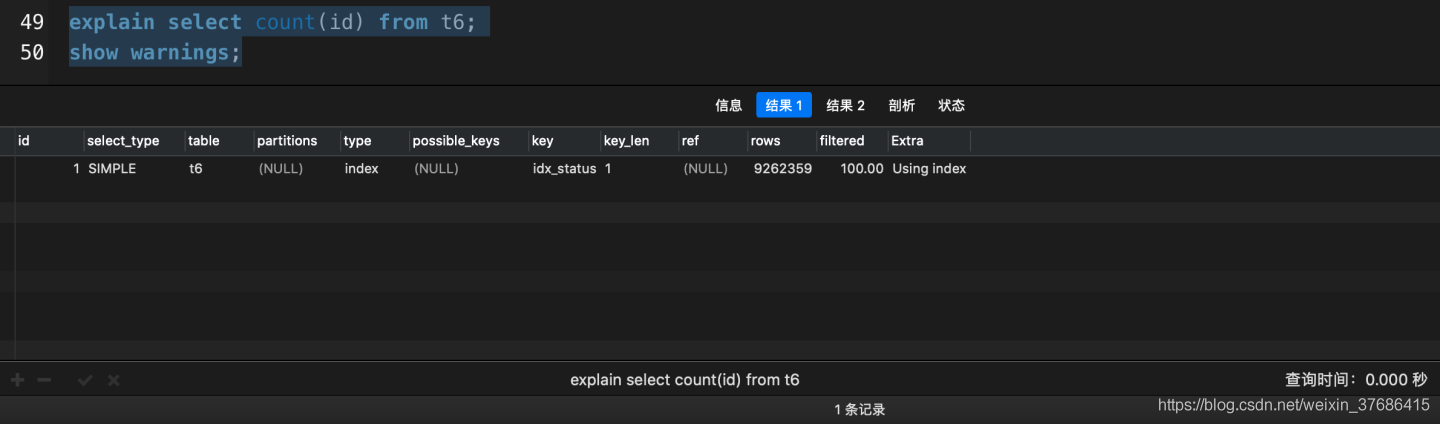
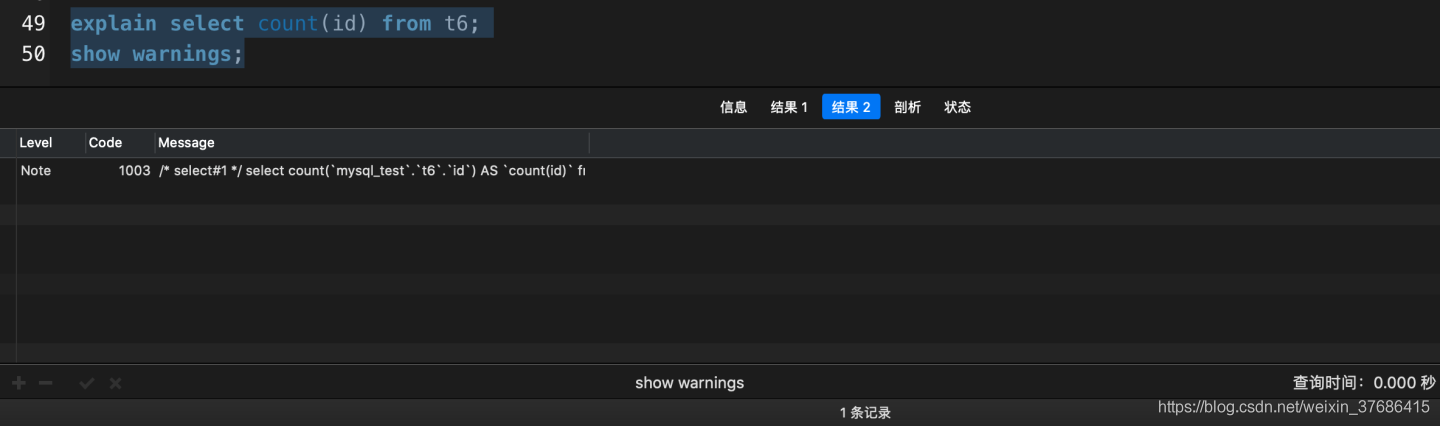
explain select count(id) from t6;
show warnings;
explain select count(*) from t6 force index (primary);
show warnings;
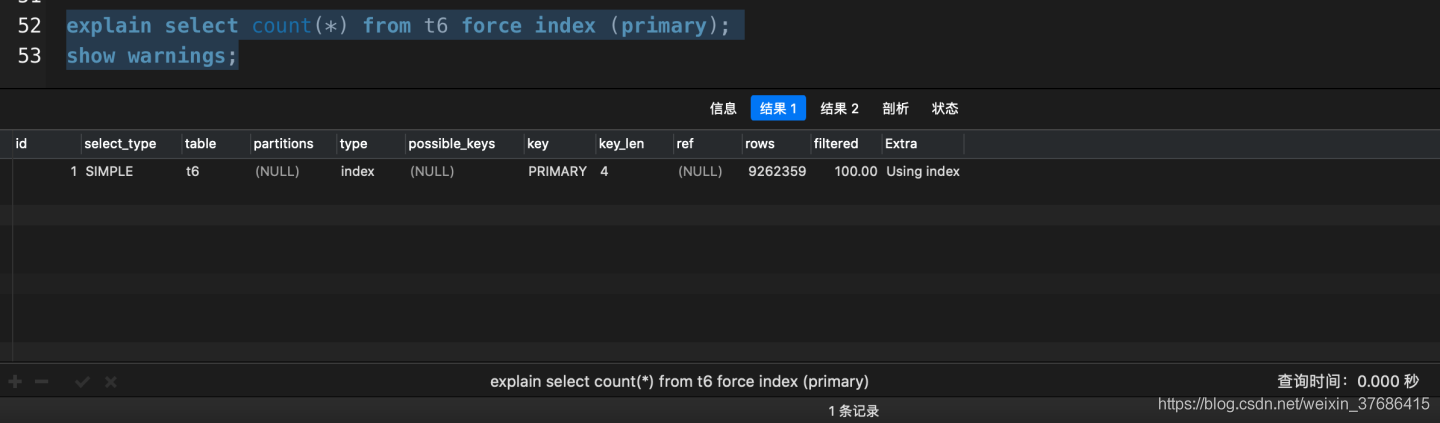
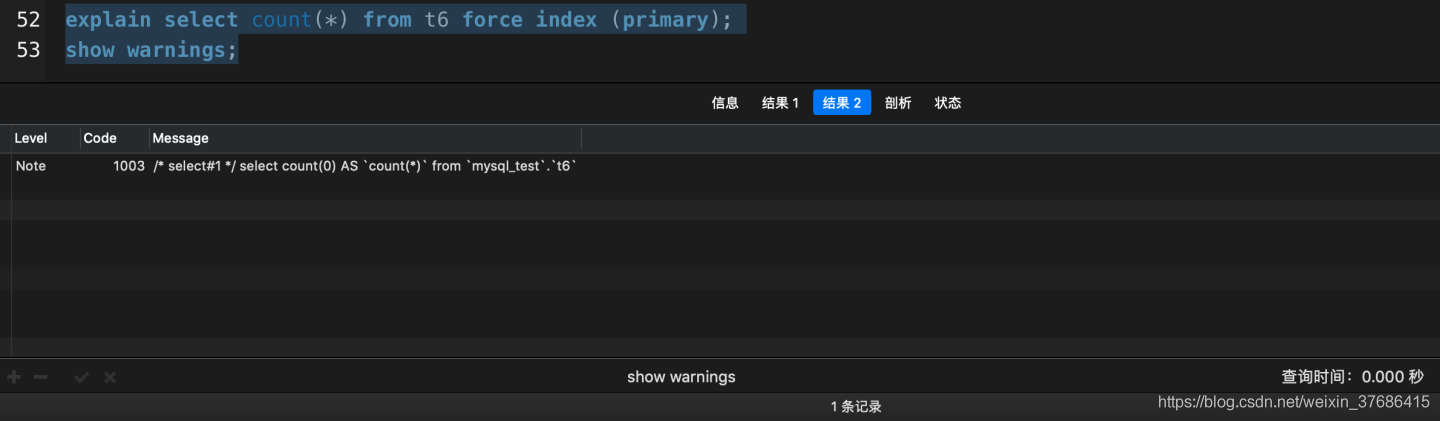
從上面的實驗可以得出這三點:
- count(*)被MySQL查詢優化器改寫成了count(0)�����,并選擇了idx_status索引
- count(1)和count(id)都選擇了idx_statux索引
- 加了force index(primary)之后����,走了強制索引
這個idx_status就是相當于是二級輔助索引樹���,目的就是為了說明: InnoDB在處理count(*)的時候�,有輔助索引樹的情況下,會優先選擇輔助索引樹來統計總行數�。
為了驗證count(*)會優先選擇輔助索引樹這個結論����,我們繼續來看看下面的實驗:
# 刪除idx_status索引����,繼續執行count(*)
alter table t6 drop index idx_status;
explain select count(*) from t6;
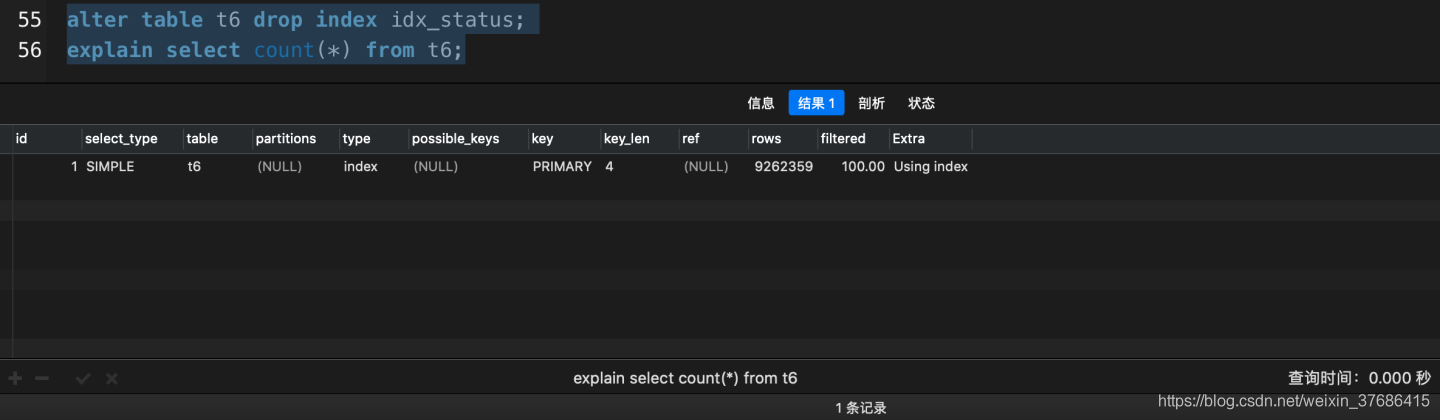
從以上實驗可以得出��,刪除了idx_status這個輔助索引樹,count(*)就會選擇走主鍵索引��。所以結論:count(*)會優先選擇輔助索引���,假如沒有輔助索引的存在�,就會走主鍵索引���。
為什么count(*)會優先選擇輔助索引����?
在MySQL5.7.18之前,InnoDB通過掃描聚集索引來處理count(*)語句。
從MySQL5.7.18開始���,InnoDB通過遍歷最小的可用二級索引來處理count(*)語句�。如果不存在二級索引,則掃描聚集索引。
新版本為何會使用二級索引來處理count(*)呢��?
因為InnoDB二級索引樹的葉子節點上存放的是主鍵����,而主鍵索引樹的葉子節點存放的是整行數據,所以二級索引樹比主鍵索引樹小���。因此查詢優化器基于成本考慮,優先選擇的是二級索引����。所以索引count(*)快于count(主鍵)�。
總結
這篇文章的結論就是count(*)=count(1)>count(id)����。
為什么count(id)走了主鍵索引還會更慢呢?因為count(id)需要取出主鍵��,然后判斷不為空���,再累加�,代價更高。
count(*)是會總計出所有NOT NULL和NULL的字段����,而count(id)是不會統計NULL字段的��,所以我們在建表的盡量使用NOT NULL并且給它一個默認是空即可。
最后����,在以后總計數據庫表的總行數的時候,可以大膽的使用count(*)或者count(1)�。
參考資料
- 《高性能MySQL》(第三版)第六章優化COUNT()查詢
- 《MySQL實戰45講》林曉斌
到此這篇關于聊聊MySQL的COUNT(*)的性能的文章就介紹到這了,更多相關MySQL COUNT(*)內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家��!
您可能感興趣的文章:- MySQL 大表的count()優化實現
- MySQL中聚合函數count的使用和性能優化技巧
- 關于mysql中innodb的count優化問題分享
- 詳解 MySQL中count函數的正確使用方法
- 淺談MySQL 統計行數的 count
- mysql count提高方法總結
- MySQL中無過濾條件的count詳解
- MySQL中count(*)、count(1)和count(col)的區別匯總
- mySQL count多個表的數據實例詳解
- MySQL COUNT函數的使用與優化
