聯(lián)網(wǎng)的出現(xiàn)和迅速發(fā)展使信息檢索的環(huán)境發(fā)生了重大變化。而基于互聯(lián)網(wǎng)的搜索引擎的排名算法直接關(guān)系到用戶在新的環(huán)境里進(jìn)行信息檢索的使用體驗(yàn)。 現(xiàn)有的搜索引擎排名算法,以基于網(wǎng)頁(yè)鏈接結(jié)構(gòu)的算法為主,主要的兩種代表性算法是PageRank算法和Hits算法,基于這兩種算法國(guó)內(nèi)外許多學(xué)者和研究機(jī)構(gòu)又進(jìn)行了新的探索和改進(jìn)。
在此基礎(chǔ)上形成了一些適于搜索引擎使用的成熟的綜合排名模型。 本文研究分析了國(guó)內(nèi)外搜索引擎的發(fā)展背景,以及對(duì)搜索引擎排序有重要影響的SEO技術(shù)。在此基礎(chǔ)之上,對(duì)PageRank算法和Hits算法進(jìn)行了深入的分析。
一、PageRank
算法PageRank是最著名的搜索引擎Google采用的一種算法策略,是根據(jù)每個(gè)網(wǎng)頁(yè)的超級(jí)鏈接信息計(jì)算網(wǎng)頁(yè)的一個(gè)權(quán)值,用于優(yōu)化搜索引擎的結(jié)果。由拉里-佩奇提出。
簡(jiǎn)單說(shuō),PageRank算法是計(jì)算每個(gè)網(wǎng)頁(yè)的綜合得分?jǐn)?shù),即假如網(wǎng)頁(yè)A鏈向網(wǎng)頁(yè)B,則網(wǎng)頁(yè)B加一分,當(dāng)然。不同鏈接網(wǎng)頁(yè)對(duì)于指向網(wǎng)頁(yè)的加分也是不同的,一個(gè)頁(yè)面的得分情況是由所有鏈向它的頁(yè)面的重要性經(jīng)過(guò)遞歸算法得到的。
PageRank算法的基本原理推導(dǎo)如下:
PR(A) = (1-d) + d*(PR(T1)/C(T1) + ... + PR(Tn)/C(Tn))
其中,PR(A)是指網(wǎng)頁(yè)A的PR值。
T1,T2,...,Tn是指網(wǎng)頁(yè)A的鏈入網(wǎng)頁(yè)。
PR(Ti)是指網(wǎng)頁(yè)Ti的PR值(i=1,2,...,n)。
C(Ti)是指網(wǎng)頁(yè)Ti的鏈出數(shù)量(i=1,2,...,n)。
D是一個(gè)衰減因子,0d1,通常取值為0.85。
從以上公式可以看出,影響一個(gè)網(wǎng)頁(yè)P(yáng)R值的主要因素如下:
(1)該網(wǎng)頁(yè)的鏈入數(shù)量。
(2)該網(wǎng)頁(yè)的鏈入網(wǎng)頁(yè)本身的PR值。
(3)該網(wǎng)頁(yè)的鏈入網(wǎng)頁(yè)本身的鏈出數(shù)量。
根據(jù)上面分析可以判斷:一個(gè)網(wǎng)頁(yè)的鏈入數(shù)量越多,這些鏈入網(wǎng)頁(yè)的PR值越高,這些網(wǎng)頁(yè)本身的鏈出數(shù)量越少,則該網(wǎng)頁(yè)的PR值越高。
Google給每一個(gè)網(wǎng)頁(yè)都賦予一個(gè)初始PR值(1-d),然后利用PageRank算法收斂計(jì)算其PR值。
網(wǎng)頁(yè)的鏈入鏈出關(guān)系,時(shí)刻都在變化,那么PR值也需要更新,可以用定時(shí)任務(wù)重復(fù)計(jì)算后更新,使得網(wǎng)頁(yè)的最終PR值達(dá)到一個(gè)均衡穩(wěn)定的狀態(tài)。
Google的查詢過(guò)程是這樣的:首先根據(jù)用戶輸入的查詢關(guān)鍵詞對(duì)于網(wǎng)頁(yè)數(shù)據(jù)庫(kù)中的網(wǎng)頁(yè)盡情匹配,然后對(duì)于匹配到的網(wǎng)頁(yè)按照其本身的PR排序呈獻(xiàn)給用戶。
此外,一個(gè)網(wǎng)頁(yè)在檢索結(jié)果列表中的位置還與其它很多因素相關(guān),比如檢索詞在網(wǎng)頁(yè)中的位置等。
PageRank的缺陷在于不考慮鏈接的價(jià)值,這對(duì)通用搜索引擎比較合適,但對(duì)主題相關(guān)的垂直搜索引擎而言并不是很好的策略。
二、HITS
PageRank算法對(duì)于向外鏈接的權(quán)值貢獻(xiàn)是平均的,即不考慮不同鏈接的重要性,但是頁(yè)面鏈接中可能某些是廣告、導(dǎo)航或者注釋鏈接,平均權(quán)值顯然不太符合實(shí)際情況。
HITS(Hyperlink Induced Topic Search)算法則是一種經(jīng)典的專題信息提取策略,能夠提高垂直查準(zhǔn)率。
1、原理
HITS算法由Jon Kleinberg提出,其對(duì)每個(gè)網(wǎng)頁(yè)都要計(jì)算兩個(gè)值:權(quán)威值(authority)和中心值(hub)。
(1)權(quán)威網(wǎng)頁(yè)
一個(gè)網(wǎng)頁(yè)被多次引用,則它可能是很重要的;一個(gè)網(wǎng)頁(yè)雖然沒(méi)有被多次引用,但是被重要的網(wǎng)頁(yè)引用,則它也可能是很重要的;一個(gè)網(wǎng)頁(yè)的重要性被平均的傳遞到它所引用的網(wǎng)頁(yè)。這種網(wǎng)頁(yè)稱為權(quán)威網(wǎng)頁(yè)。
(2)Hub網(wǎng)頁(yè)
提供指向權(quán)威網(wǎng)頁(yè)的鏈接集合的Web網(wǎng)頁(yè),它本身可能并不重要,或者說(shuō)沒(méi)幾個(gè)網(wǎng)頁(yè)指向它,但是它提供了指向就某個(gè)主題而言最為重要的站點(diǎn)的鏈接集合,這種網(wǎng)頁(yè)叫做Hub網(wǎng)頁(yè)。
(3)算法思想
首先利用通用搜索引擎得到一個(gè)網(wǎng)頁(yè)的初始子集I,當(dāng)然I內(nèi)的頁(yè)面都是和用戶查詢條件有很大相關(guān)性。然后把I指向的網(wǎng)頁(yè)和指向I的網(wǎng)頁(yè)都包含進(jìn)來(lái),形成基礎(chǔ)集合E,E中的每個(gè)頁(yè)面都具有一個(gè)authority權(quán)值和hub權(quán)值,分別記作a和h,a值表示網(wǎng)頁(yè)與查詢條件相關(guān)度的高低,h反應(yīng)的是該頁(yè)面鏈出相關(guān)度頁(yè)面的多少情況。a=(a1, a2, ..., an)和h=(h1, h2, ..., hn)代表E中所有網(wǎng)頁(yè)的authority和hub向量,初始時(shí)把所有的ai和hi都設(shè)置為1,然后利用下面的公式進(jìn)行計(jì)算:
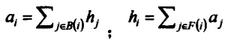
其中,B(i)和F(i)分別表示指向該網(wǎng)頁(yè)的網(wǎng)頁(yè)鏈接集合和該網(wǎng)頁(yè)指向的網(wǎng)頁(yè)鏈接集合。用n*n的矩陣A表示集合E的網(wǎng)頁(yè)節(jié)點(diǎn)間的連接,如果節(jié)點(diǎn)i和節(jié)點(diǎn)j之間有連接,則A[i,j]=1,則A[i,j]=0,因此,上面公式可以表示為:
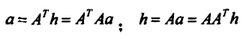
迭代計(jì)算a和h,直至收斂。這樣我們集中求ATA和AAT。最后按照authority和hub值排序,將a和h值大于閾值M的網(wǎng)頁(yè)挑出來(lái)。
若一個(gè)網(wǎng)頁(yè)由很多好的hub指向,則其權(quán)威值會(huì)相應(yīng)增加;若一個(gè)網(wǎng)頁(yè)指向很多好的權(quán)威頁(yè),則hub值也會(huì)相應(yīng)增加。HITS算法最后輸出的一組具有較大hub值的網(wǎng)頁(yè)和具有較大權(quán)威值的網(wǎng)頁(yè)。
2、缺陷
HITS算法在提高一定的垂直查準(zhǔn)率的同時(shí),也存在如下缺陷:
(1)HITS算法忽略了網(wǎng)頁(yè)內(nèi)容的差異,對(duì)于每個(gè)鏈接網(wǎng)頁(yè)賦予相同的加權(quán)常數(shù),因?yàn)槊總€(gè)網(wǎng)頁(yè)中都會(huì)有一些廣告鏈接等非相關(guān)的鏈接網(wǎng)頁(yè),這些非相關(guān)網(wǎng)頁(yè)和相關(guān)網(wǎng)頁(yè)同等對(duì)待,會(huì)容易產(chǎn)生主題漂移現(xiàn)象。
(2)在開始形成url集合E中,對(duì)于初始集合I中網(wǎng)頁(yè)的一些非相關(guān)鏈接也加入到E中,增加了無(wú)謂的下載量,也致使后邊更多的無(wú)關(guān)網(wǎng)頁(yè)參與到了計(jì)算,對(duì)準(zhǔn)確率存在一定的影響。
3、改進(jìn)
改進(jìn)方向如下:
(1)主題漂移
(2)下載過(guò)濾
以上就是搜索引擎技術(shù)之排序算法,雖然公式有點(diǎn)麻煩,但是仔細(xì)鉆研的話就會(huì)有所收獲的哦,謝謝大家閱讀。
