物聯(lián)網(wǎng)領(lǐng)域近期如火如荼,互聯(lián)網(wǎng)和傳統(tǒng)公司爭相布局物聯(lián)網(wǎng)。作為物聯(lián)網(wǎng)領(lǐng)域數(shù)據(jù)存儲的首選,時序數(shù)據(jù)庫也越來越多進(jìn)入人們的視野,而早在 2016 年 7 月,百度云在其天工物聯(lián)網(wǎng)平臺上發(fā)布了國內(nèi)首個多租戶的分布式時序數(shù)據(jù)庫產(chǎn)品TSDB,成為支持其發(fā)展制造,交通,能源,智慧城市等產(chǎn)業(yè)領(lǐng)域的核心產(chǎn)品,同時也成為百度戰(zhàn)略發(fā)展產(chǎn)業(yè)物聯(lián)網(wǎng)的標(biāo)識表記標(biāo)幟性事件。
前文提到低成本的存儲是時序數(shù)據(jù)庫需要解決的一個主要問題,而上一篇文章介紹了通過針對時序數(shù)據(jù)的壓縮方法,從利用數(shù)據(jù)自己特征的方面,降低時序數(shù)據(jù)的存儲成本。
本文將介紹通過對數(shù)據(jù)進(jìn)行分級存儲,從使用差別存儲介質(zhì),以及減少數(shù)據(jù)的副本數(shù)的方面,介紹如安在保證時序數(shù)據(jù)的查詢性能的前提下,降低時序數(shù)據(jù)的存儲成本。
1.分級存儲
分級存儲,就是按某一特征,將數(shù)據(jù)劃分為差別的級別,每個級另外數(shù)據(jù)存儲在差別成本的存儲介質(zhì)上。為什么需要對數(shù)據(jù)進(jìn)行分級存儲?為什么不把所有的數(shù)據(jù)都存儲在最自制的存儲介質(zhì)上?這是因為在降低存儲成本的同時,還需要保證數(shù)據(jù)拜候的性能(我們知道,存儲介質(zhì)的讀寫性能與成本一般成正比),分級存儲是對兩者比較好的平衡方法。分級存儲的這一思想也表現(xiàn)在計算機的體系結(jié)構(gòu)里(寄存器、L1/L2
Cache、內(nèi)存、硬盤)。
2.時序數(shù)據(jù)的分級存儲
時序數(shù)據(jù)應(yīng)該按什么特征進(jìn)行分級呢?時序數(shù)據(jù)的時間戳是一種非常合適的分級依據(jù),越近期的數(shù)據(jù)查詢得越多,是熱數(shù)據(jù);越久以前的數(shù)據(jù)查詢得越少,是冷數(shù)據(jù)。例如,用戶會經(jīng)常查詢一個設(shè)備的最新溫度,或者查看這個設(shè)備比來 1 小時或者比來 1 天的溫度曲線;很難想象用戶會經(jīng)常查詢一個設(shè)備 1 年前的溫度,這些 1 年前的數(shù)據(jù)一般會用于大數(shù)據(jù)分析或者機器學(xué)習(xí)中,而這些批處理的場景一般對查詢的延時不會像交互式場景那么敏感。
如圖 1 所示,一般可以將時序數(shù)據(jù)分為 3 級,第一級是比來 1 天的數(shù)據(jù)生存在內(nèi)存緩存Cache中,第二級是比來 1 年的數(shù)據(jù)存儲在固態(tài)硬盤SSD中,第三級是 1 年以上的數(shù)據(jù)存儲在機械硬盤HDD中。Cache中的數(shù)據(jù)可以使用寫回(write
back)或者寫通(write
through)的策略寫入SSD,而SSD中的數(shù)據(jù)可以通過后臺程序按期批量的遷移到HDD。為了保證數(shù)據(jù)持久性,一般會為數(shù)據(jù)生存 2 個或者 3 個副本,通過EC編碼可以將副本數(shù)降低到1. 5 甚至更低,但卻不影響數(shù)據(jù)的持久性。不過EC編碼會消耗更多的CPU和網(wǎng)絡(luò)帶寬,進(jìn)而影響查詢性能,因此一般只應(yīng)用在存儲冷數(shù)據(jù)的HDD上。
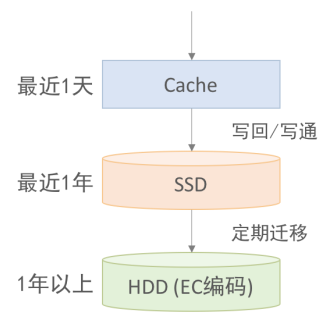
圖1 時序數(shù)據(jù)的分級存儲
3.內(nèi)存緩存
時序數(shù)據(jù)庫大部分請求的數(shù)據(jù)都集中在比來 1 天,將這些數(shù)據(jù)生存在內(nèi)存中,可以保證這些數(shù)據(jù)能被快速的讀取。雖然內(nèi)存的拜候速度快,但是成本很高(價格大約比SSD高一個數(shù)量級),而且容量有限。因此需要對數(shù)據(jù)進(jìn)行壓縮,以減少每個數(shù)據(jù)的內(nèi)存占用,壓縮相關(guān)的內(nèi)容已經(jīng)在上一篇文章中進(jìn)行了介紹,在這里不再贅述。另一方面,由于內(nèi)存中的數(shù)據(jù)是易失的、非持久化的,一旦重啟進(jìn)程或者重啟機器后就會丟失,如果不恢復(fù)數(shù)據(jù),所有請求將落到下一級的存儲上,對下一級存儲造成巨大的壓力。因此一般會在寫入內(nèi)存的同時寫入當(dāng)?shù)赜脖P,在重啟后重新加載到內(nèi)存中。
Beringei(注1)是Facebook開源的一款內(nèi)存時序數(shù)據(jù)庫,是Facebook頒發(fā)的Gorilla論文(注2)的開源實現(xiàn)。Beringei使用一種三級的內(nèi)存數(shù)據(jù)結(jié)構(gòu),如圖 2 所示,其中第一級為分片索引,第二級為時間序列索引,第三級為時序數(shù)據(jù),通過該數(shù)據(jù)結(jié)構(gòu)可以支持快速的數(shù)據(jù)讀寫;Beringei實現(xiàn)了一種高效的流式的壓縮算法,從而使內(nèi)存占用最小化;Beringei支持寫入內(nèi)存的同時寫入硬盤,并在重啟后恢復(fù)數(shù)據(jù)。然而Beringei也有一些限制,譬如只支持浮點型數(shù)值、時間精度只到秒、只能定時間戳挨次的寫入數(shù)據(jù)。

圖2 Beringei的內(nèi)存數(shù)據(jù)結(jié)構(gòu)(注2)
4.SSD與HDD
用戶有時會關(guān)注時序數(shù)據(jù)在過去 1 周、過去 1 個月、過去 1 年的趨勢,把比來 1 年的數(shù)據(jù)存儲在固態(tài)硬盤SSD上,可以實現(xiàn)在秒級甚至亞秒級讀取過去 1 年的數(shù)據(jù)。而 1 年以上的時序數(shù)據(jù)則很少用于交互式查詢,這些數(shù)據(jù)往往會用于大數(shù)據(jù)分析或者機器學(xué)習(xí),這些批處理場景對查詢的延時不會像交互式場景那么敏感,因此可以把這些 1 年以上的數(shù)據(jù)存儲在機械硬盤HDD上。
