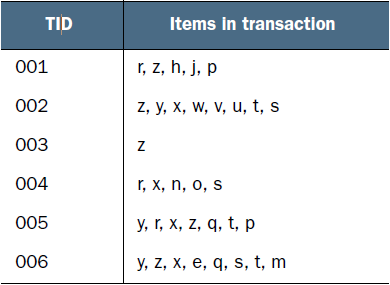
FP樹通過逐個讀入事務,并把事務映射到FP樹中的一條路徑來構造。由于不同的事務可能會有若干個相同的項,因此它們的路徑可能部分重疊。路徑相互重疊越多,使用FP樹結構獲得的壓縮效果越好;如果FP樹足夠小,能夠存放在內存中,就可以直接從這個內存中的結構提取頻繁項集,而不必重復地掃描存放在硬盤上的數據。
通常,FP樹的大小比未壓縮的數據小,因為數據的事務常常共享一些共同項,在最好的情況下,所有的事務都具有相同的項集,FP樹只包含一條節點路徑;當每個事務都具有唯一項集時,導致最壞情況發生,由于事務不包含任何共同項,FP樹的大小實際上與原數據的大小一樣。
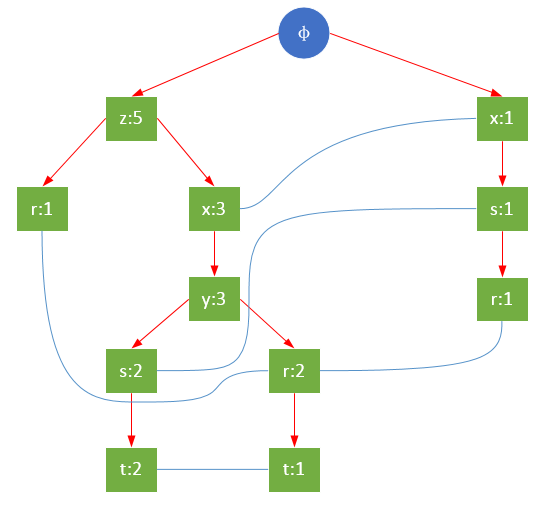
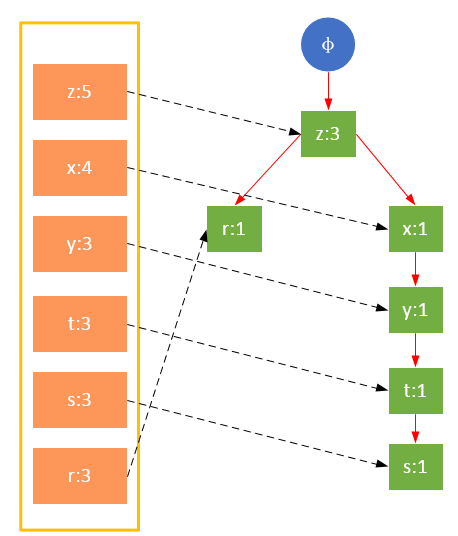
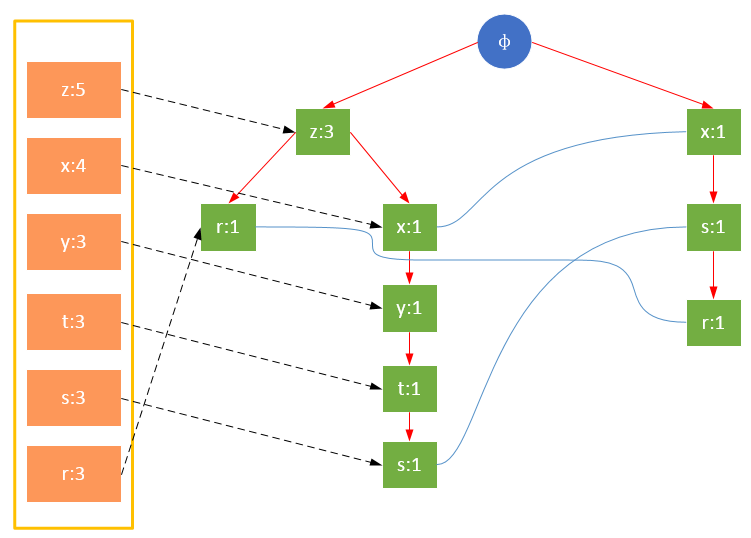
FP樹的根節點用φ表示,其余節點包括一個數據項和該數據項在本路徑上的支持度;每條路徑都是一條訓練數據中滿足最小支持度的數據項集;FP樹還將所有相同項連接成鏈表,上圖中用藍色連線表示。
為了快速訪問樹中的相同項,還需要維護一個連接具有相同項的節點的指針列表(headTable),每個列表元素包括:數據項、該項的全局最小支持度、指向FP樹中該項鏈表的表頭的指針。
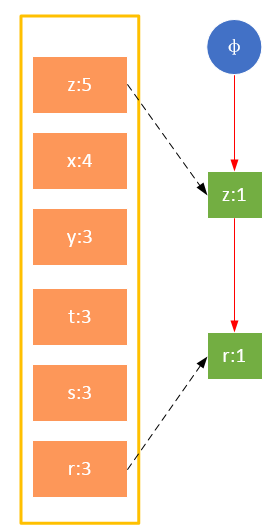
參與掃描的是過濾后的數據,如果某個數據項是第一次遇到,則創建該節點,并在headTable中添加一個指向該節點的指針;否則按路徑找到該項對應的節點,修改節點信息。具體過程如下所示:
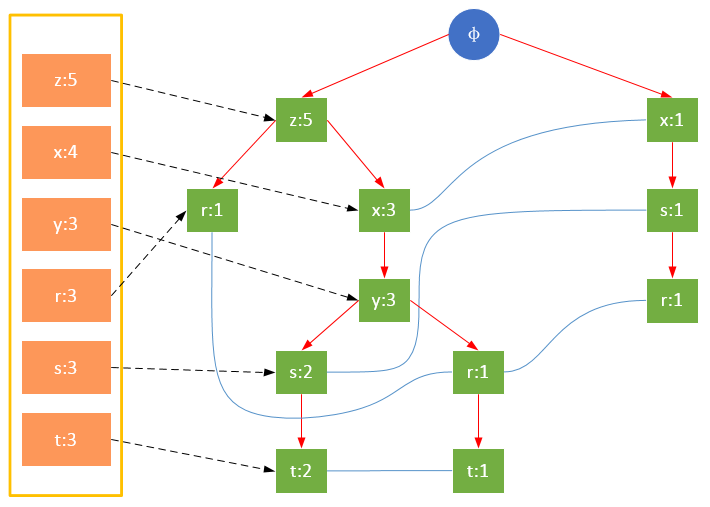
從上面可以看出,headTable并不是隨著FPTree一起創建,而是在第一次掃描時就已經創建完畢,在創建FPTree時只需要將指針指向相應節點即可。從事務004開始,需要創建節點間的連接,使不同路徑上的相同項連接成鏈表。
def loadSimpDat():
simpDat = [['r', 'z', 'h', 'j', 'p'],
['z', 'y', 'x', 'w', 'v', 'u', 't', 's'],
['z'],
['r', 'x', 'n', 'o', 's'],
['y', 'r', 'x', 'z', 'q', 't', 'p'],
['y', 'z', 'x', 'e', 'q', 's', 't', 'm']]
return simpDat
def createInitSet(dataSet):
retDict = {}
for trans in dataSet:
fset = frozenset(trans)
retDict.setdefault(fset, 0)
retDict[fset] += 1
return retDict
class treeNode:
def __init__(self, nameValue, numOccur, parentNode):
self.name = nameValue
self.count = numOccur
self.nodeLink = None
self.parent = parentNode
self.children = {}
def inc(self, numOccur):
self.count += numOccur
def disp(self, ind=1):
print(' ' * ind, self.name, ' ', self.count)
for child in self.children.values():
child.disp(ind + 1)
def createTree(dataSet, minSup=1):
headerTable = {}
#此一次遍歷數據集, 記錄每個數據項的支持度
for trans in dataSet:
for item in trans:
headerTable[item] = headerTable.get(item, 0) + 1
#根據最小支持度過濾
lessThanMinsup = list(filter(lambda k:headerTable[k] minSup, headerTable.keys()))
for k in lessThanMinsup: del(headerTable[k])
freqItemSet = set(headerTable.keys())
#如果所有數據都不滿足最小支持度,返回None, None
if len(freqItemSet) == 0:
return None, None
for k in headerTable:
headerTable[k] = [headerTable[k], None]
retTree = treeNode('φ', 1, None)
#第二次遍歷數據集,構建fp-tree
for tranSet, count in dataSet.items():
#根據最小支持度處理一條訓練樣本,key:樣本中的一個樣例,value:該樣例的的全局支持度
localD = {}
for item in tranSet:
if item in freqItemSet:
localD[item] = headerTable[item][0]
if len(localD) > 0:
#根據全局頻繁項對每個事務中的數據進行排序,等價于 order by p[1] desc, p[0] desc
orderedItems = [v[0] for v in sorted(localD.items(), key=lambda p: (p[1],p[0]), reverse=True)]
updateTree(orderedItems, retTree, headerTable, count)
return retTree, headerTable
def updateTree(items, inTree, headerTable, count):
if items[0] in inTree.children: # check if orderedItems[0] in retTree.children
inTree.children[items[0]].inc(count) # incrament count
else: # add items[0] to inTree.children
inTree.children[items[0]] = treeNode(items[0], count, inTree)
if headerTable[items[0]][1] == None: # update header table
headerTable[items[0]][1] = inTree.children[items[0]]
else:
updateHeader(headerTable[items[0]][1], inTree.children[items[0]])
if len(items) > 1: # call updateTree() with remaining ordered items
updateTree(items[1:], inTree.children[items[0]], headerTable, count)
def updateHeader(nodeToTest, targetNode): # this version does not use recursion
while (nodeToTest.nodeLink != None): # Do not use recursion to traverse a linked list!
nodeToTest = nodeToTest.nodeLink
nodeToTest.nodeLink = targetNode
simpDat = loadSimpDat()
dictDat = createInitSet(simpDat)
myFPTree,myheader = createTree(dictDat, 3)
myFPTree.disp()
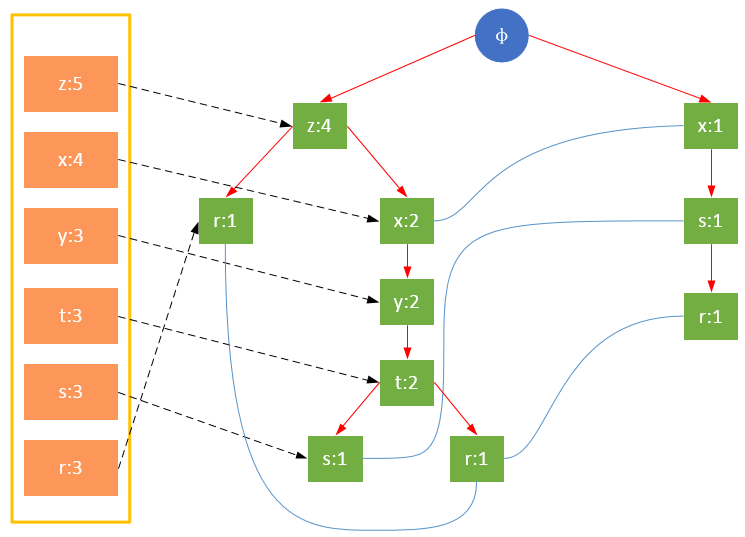
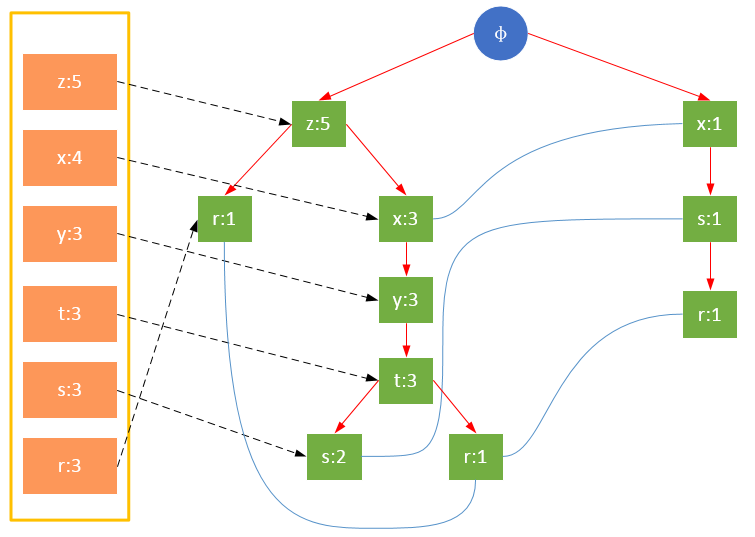
值得注意的是,對項的關鍵字排序將會影響FP樹的結構。下面兩圖是相同訓練集生成的FP樹,圖1除了按照最小支持度排序外,未對項做任何處理;圖2則將項按照關鍵字進行了降序排序。樹的結構也將影響后續發現頻繁項的結果。