為了得到更好的網(wǎng)絡(luò),學(xué)習(xí)率通常是要調(diào)整的,即剛開(kāi)始用較大的學(xué)習(xí)率來(lái)加快網(wǎng)絡(luò)的訓(xùn)練,之后為了提高精確度,需要將學(xué)習(xí)率調(diào)低一點(diǎn)。
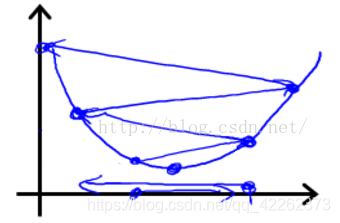
如圖所示,步長(zhǎng)(學(xué)習(xí)率)太大容易跨過(guò)最優(yōu)解。
代碼如下:
表示每20個(gè)epoch學(xué)習(xí)率調(diào)整為之前的10%
optimizer = optim.SGD(gan.parameters(),
lr=0.1,
momentum=0.9,
weight_decay=0.0005)
lr = optimizer.param_groups[0]['lr'] * (0.1 ** (epoch // 20))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
print(optimizer.param_groups[0]['lr'])
補(bǔ)充:Pytorch 在訓(xùn)練過(guò)程中實(shí)現(xiàn)學(xué)習(xí)率衰減
在網(wǎng)絡(luò)的訓(xùn)練過(guò)程中,學(xué)習(xí)率是一個(gè)非常重要的超參數(shù),它直接影響了網(wǎng)絡(luò)的訓(xùn)練效果。
但過(guò)大的學(xué)習(xí)率將會(huì)導(dǎo)致網(wǎng)絡(luò)無(wú)法達(dá)到局部最小點(diǎn),使得訓(xùn)練結(jié)果震蕩,準(zhǔn)確率無(wú)法提升,而過(guò)小的學(xué)習(xí)率將會(huì)導(dǎo)致擬合速度過(guò)慢,浪費(fèi)大量的時(shí)間和算力。
因此我們希望在訓(xùn)練之初能夠有較大的學(xué)習(xí)率加快擬合的速率,之后降低學(xué)習(xí)率,使得網(wǎng)絡(luò)能夠更好的達(dá)到局部最小,提高網(wǎng)絡(luò)的效率。
torch.optim.lr_scheduler.LambdaLR()
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)
其中optimizer就是包裝好的優(yōu)化器, lr_lambda即為操作學(xué)習(xí)率的函數(shù)。
將每個(gè)參數(shù)組的學(xué)習(xí)速率設(shè)置為初始的lr乘以一個(gè)給定的函數(shù)。
當(dāng)last_epoch=-1時(shí),將初始lr設(shè)置為lr。
torch.optim.lr_scheduler.StepLR()
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
其中optimizer就是包裝好的優(yōu)化器,step_size (int) 為學(xué)習(xí)率衰減期,指幾個(gè)epoch衰減一次。gamma為學(xué)習(xí)率衰減的乘積因子。 默認(rèn)為0.1 。當(dāng)last_epoch=-1時(shí),將初始lr設(shè)置為lr。
以上為個(gè)人經(jīng)驗(yàn),希望能給大家一個(gè)參考,也希望大家多多支持腳本之家。
您可能感興趣的文章:- pytorch 優(yōu)化器(optim)不同參數(shù)組,不同學(xué)習(xí)率設(shè)置的操作
- pytorch實(shí)現(xiàn)查看當(dāng)前學(xué)習(xí)率
- 在pytorch中動(dòng)態(tài)調(diào)整優(yōu)化器的學(xué)習(xí)率方式
- pytorch 實(shí)現(xiàn)模型不同層設(shè)置不同的學(xué)習(xí)率方式
