目錄
- 引言
- 數(shù)據(jù)獲取與指標(biāo)構(gòu)建
- 數(shù)據(jù)獲取
- 構(gòu)建目標(biāo)變量(target variable)
- 技術(shù)指標(biāo)特征構(gòu)建
- 計算技術(shù)指標(biāo)
- 模型預(yù)測與評估
- 加入技術(shù)指標(biāo)特征
- 特征的優(yōu)化
- 結(jié)語
引言
近年來,隨著技術(shù)的發(fā)展,機(jī)器學(xué)習(xí)和深度學(xué)習(xí)在金融資產(chǎn)量化研究上的應(yīng)用越來越廣泛和深入。目前,大量數(shù)據(jù)科學(xué)家在Kaggle網(wǎng)站上發(fā)布了使用機(jī)器學(xué)習(xí)/深度學(xué)習(xí)模型對股票、期貨、比特幣等金融資產(chǎn)做預(yù)測和分析的文章。從金融投資的角度看,這些文章可能缺乏一定的理論基礎(chǔ)支撐(或交易思維),大都是基于數(shù)據(jù)挖掘。但從量化的角度看,有很多值得我們學(xué)習(xí)參考的地方,尤其是Pyhton的深入應(yīng)用、數(shù)據(jù)可視化和機(jī)器學(xué)習(xí)模型的評估與優(yōu)化等。下面借鑒Kaggle上的一篇文章《Building an Asset Trading Strategy》,以上證指數(shù)為例,構(gòu)建雙均線交易策略,以交易信號為目標(biāo)變量,以技術(shù)分析指標(biāo)作為預(yù)測特征變量,使用多種機(jī)器學(xué)習(xí)模型進(jìn)行對比評估和優(yōu)化。文中的特征變量構(gòu)建和提取,機(jī)器學(xué)習(xí)模型的對比評估和結(jié)果可視化都是很好的參考模板。
數(shù)據(jù)獲取與指標(biāo)構(gòu)建
先引入需要用到的libraries,這是Python語言的突出特點(diǎn)之一。這些涉及到的包比較多,包括常用的numpy、pandas、matplotlib,技術(shù)分析talib,機(jī)器學(xué)習(xí)sklearn和數(shù)據(jù)包tushare等。
#先引入后面可能用到的libraries
import numpy as np
import pandas as pd
import tushare as ts
#技術(shù)指標(biāo)
import talib as ta
#機(jī)器學(xué)習(xí)模塊
from sklearn.linear_model import LogisticRegression
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier,XGBRegressor
from catboost import CatBoostClassifier,CatBoostRegressor
from sklearn.ensemble import RandomForestClassifier,RandomForestRegressor
from sklearn.model_selection import train_test_split,KFold,cross_val_score
from sklearn.metrics import accuracy_score
import shap
from sklearn.feature_selection import SelectKBest,f_regression
from sklearn import preprocessing
#畫圖
import seaborn as sns
import matplotlib.pyplot as plt
import plotly.graph_objects as go
import plotly.express as px
%matplotlib inline
#正常顯示畫圖時出現(xiàn)的中文和負(fù)號
from pylab import mpl
mpl.rcParams['font.sans-serif']=['SimHei']
mpl.rcParams['axes.unicode_minus']=False
數(shù)據(jù)獲取
用tushare獲取上證行情數(shù)據(jù)作為分析樣本。
#默認(rèn)以上證指數(shù)交易數(shù)據(jù)為例
def get_data(code='sh',start='2000-01-01',end='2021-03-02'):
df=ts.get_k_data('sh',start='2005')
df.index=pd.to_datetime(df.date)
df=df[['open','high','low','close','volume']]
return df
df=get_data()
df_train,df_test=df.loc[:'2017'],df.loc['2018':]
構(gòu)建目標(biāo)變量(target variable)
以交易信號作為目標(biāo)變量,使用價格信息和技術(shù)指標(biāo)作為特征變量進(jìn)行預(yù)測分析。以雙均線交易策略為例,當(dāng)短期均線向上突破長期均線時形成買入信號(設(shè)定為1),當(dāng)短期均線向下跌破長期均線時發(fā)出賣出信號(設(shè)定為0),然后再使用機(jī)器學(xué)習(xí)模型進(jìn)行預(yù)測和評估。這里將短期移動平均值(SMA1)和長期移動平均值(SMA2)的參數(shù)分別設(shè)置為10和60,二者的設(shè)定具有一定的任意性,參數(shù)的選擇會影響后續(xù)結(jié)果,所以理想情況下需要進(jìn)行參數(shù)優(yōu)化來找到最優(yōu)值。
def trade_signal(data,short=10,long=60,tr_id=False):
data['SMA1'] = data.close.rolling(short).mean()
data['SMA2'] = data.close.rolling(long).mean()
data['signal'] = np.where(data['SMA1'] >data['SMA2'], 1.0, 0.0)
if(tr_id is not True):
display(data['signal'].value_counts())
df_tr1 = df_train.copy(deep=True)
df_te1 = df_test.copy(deep=True)
trade_signal(df_tr1) #
trade_signal(df_te1,tr_id=True)
plt.figure(figsize=(14,12), dpi=80)
ax1 = plt.subplot(211)
plt.plot(df_tr1.close,color='b')
plt.title('上證指數(shù)走勢',size=15)
plt.xlabel('')
ax2 = plt.subplot(212)
plt.plot(df_tr1.signal,color='r')
plt.title('交易信號',size=15)
plt.xlabel('')
plt.show()

df_tr1[['SMA1','SMA2','signal']].iloc[-250:].plot(figsize=(14,6),secondary_y=['signal'])
plt.show()

#刪除均線變量
df_tr1=df_tr1.drop(['SMA1','SMA2'], axis=1)
df_te1=df_te1.drop(['SMA1','SMA2'], axis=1)
#畫目標(biāo)變量與其他變量之間的相關(guān)系數(shù)圖
cmap = sns.diverging_palette(220, 10, as_cmap=True)
def corrMat(df,target='demand',figsize=(9,0.5),ret_id=False):
corr_mat = df.corr().round(2);shape = corr_mat.shape[0]
corr_mat = corr_mat.transpose()
corr = corr_mat.loc[:, df.columns == target].transpose().copy()
if(ret_id is False):
f, ax = plt.subplots(figsize=figsize)
sns.heatmap(corr,vmin=-0.3,vmax=0.3,center=0,
cmap=cmap,square=False,lw=2,annot=True,cbar=False)
plt.title(f'Feature Correlation to {target}')
if(ret_id):
return corr
corrMat(df_tr1,'signal',figsize=(7,0.5))

當(dāng)前的特征open、high、low、close、volumes與目標(biāo)變量的線性相關(guān)值非常小,這可能意味著存在高非線性,相對平穩(wěn)值的穩(wěn)定振蕩(圓形散射),或者也許它們不是理想的預(yù)測特征變量,所以下面需要進(jìn)行特征構(gòu)建和選取。
技術(shù)指標(biāo)特征構(gòu)建
為方便分析,下面以常見的幾個技術(shù)指標(biāo)作為特征引入特征矩陣,具體指標(biāo)有:
移動平均線:移動平均線通過減少噪音來指示價格的運(yùn)動趨勢。
隨機(jī)振蕩器%K和%D:隨機(jī)振蕩器是一個動量指示器,比較特定的證券收盤價和一定時期內(nèi)的價格范圍。%K、%D分別為慢、快指標(biāo)。
相對強(qiáng)弱指數(shù)(RSI):動量指標(biāo),衡量最近價格變化的幅度,以評估股票或其他資產(chǎn)的價格超買或超賣情況。
變化率(ROC):動量振蕩器,測量當(dāng)前價格和n期過去價格之間的百分比變化。ROC值越高越有可能超買,越低可能超賣。
動量(MOM):證券價格或成交量加速的速度;價格變化的速度。
#復(fù)制之前的數(shù)據(jù)
df_tr2=df_tr1.copy(deep=True)
df_te2=df_te1.copy(deep=True)
計算技術(shù)指標(biāo)
#使用talib模塊直接計算相關(guān)技術(shù)指標(biāo)
#下面參數(shù)的選取具有主觀性
def indicators(data):
data['MA13']=ta.MA(data.close,timeperiod=13)
data['MA34']=ta.MA(data.close,timeperiod=34)
data['MA89']=ta.MA(data.close,timeperiod=89)
data['EMA10']=ta.EMA(data.close,timeperiod=10)
data['EMA30']=ta.EMA(data.close,timeperiod=30)
data['EMA200']=ta.EMA(data.close,timeperiod=200)
data['MOM10']=ta.MOM(data.close,timeperiod=10)
data['MOM30']=ta.MOM(data.close,timeperiod=30)
data['RSI10']=ta.RSI(data.close,timeperiod=10)
data['RSI30']=ta.RSI(data.close,timeperiod=30)
data['RS200']=ta.RSI(data.close,timeperiod=200)
data['K10'],data['D10']=ta.STOCH(data.high,data.low,data.close, fastk_period=10)
data['K30'],data['D30']=ta.STOCH(data.high,data.low,data.close, fastk_period=30)
data['K20'],data['D200']=ta.STOCH(data.high,data.low,data.close, fastk_period=200)
indicators(df_tr2)
indicators(df_te2)
corrMat(df_tr2,'signal',figsize=(15,0.5))

上圖可以看到明顯線性相關(guān)的一組特征是作為特征工程的結(jié)果創(chuàng)建的。如果在特征矩陣中使用基本數(shù)據(jù)集特征,很可能對目標(biāo)變量的變化影響很小或沒有影響。另一方面,新創(chuàng)建的特征具有相當(dāng)寬的相關(guān)值范圍,這是相當(dāng)重要的;與目標(biāo)變量(交易信號)的相關(guān)性不算特別高。
#刪除缺失值
df_tr2 = df_tr2.dropna()
df_te2 = df_te2.dropna()
模型預(yù)測與評估
下面使用常用的機(jī)器學(xué)習(xí)算法分別對數(shù)據(jù)進(jìn)行擬合和交叉驗證評估
models.append(('RF', RandomForestClassifier(n_estimators=25)))
models = []
#輕量級模型
#線性監(jiān)督模型
models.append(('LR', LogisticRegression(n_jobs=-1)))
models.append(('TREE', DecisionTreeClassifier()))
#非監(jiān)督模型
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('NB', GaussianNB()))
#高級模型
models.append(('GBM', GradientBoostingClassifier(n_estimators=25)))
models.append(('XGB',XGBClassifier(n_estimators=25,use_label_encoder=False)))
models.append(('CAT',CatBoostClassifier(silent=True,n_estimators=25)))
構(gòu)建模型評估函數(shù)
def modelEval(ldf,feature='signal',split_id=[None,None],eval_id=[True,True,True,True],
n_fold=5,scoring='accuracy',cv_yrange=None,hm_vvals=[0.5,1.0,0.75]):
''' Split Train/Evaluation DataFrame> Set Split '''
# split_id : Train/Test split [%,timestamp], whichever is not None
# test_id : Evaluate trained model on test set only
if(split_id[0] is not None):
train_df,eval_df = train_test_split(ldf,test_size=split_id[0],shuffle=False)
elif(split_id[1] is not None):
train_df = df.loc[:split_id[1]]; eval_df = df.loc[split_id[1]:]
else:
print('Choose One Splitting Method Only')
''' Train/Test Feature Matrices + Target Variables Split'''
y_train = train_df[feature]
X_train = train_df.loc[:, train_df.columns != feature]
y_eval = eval_df[feature]
X_eval = eval_df.loc[:, eval_df.columns != feature]
X_one = pd.concat([X_train,X_eval],axis=0)
y_one = pd.concat([y_train,y_eval],axis=0)
''' Cross Validation, Training/Evaluation, one evaluation'''
lst_res = []; names = []; lst_train = []; lst_eval = []; lst_one = []; lst_res_mean = []
if(any(eval_id)):
for name, model in models:
names.append(name)
# Cross Validation Model on Training Se
if(eval_id[0]):
kfold = KFold(n_splits=n_fold, shuffle=True)
cv_res = cross_val_score(model,X_train,y_train, cv=kfold, scoring=scoring)
lst_res.append(cv_res)
# Evaluate Fit Model on Training Data
if(eval_id[1]):
res = model.fit(X_train,y_train)
train_res = accuracy_score(res.predict(X_train),y_train); lst_train.append(train_res)
if(eval_id[2]):
if(eval_id[1] is False): # If training hasn't been called yet
res = model.fit(X_train,y_train)
eval_res = accuracy_score(res.predict(X_eval),y_eval); lst_eval.append(eval_res)
# Evaluate model on entire dataset
if(eval_id[3]):
res = model.fit(X_one,y_one)
one_res = accuracy_score(res.predict(X_one),y_one); lst_one.append(one_res)
''' [out] Verbal Outputs '''
lst_res_mean.append(cv_res.mean())
fn1 = cv_res.mean()
fn2 = cv_res.std();
fn3 = train_res
fn4 = eval_res
fn5 = one_res
s0 = pd.Series(np.array(lst_res_mean),index=names)
s1 = pd.Series(np.array(lst_train),index=names)
s2 = pd.Series(np.array(lst_eval),index=names)
s3 = pd.Series(np.array(lst_one),index=names)
pdf = pd.concat([s0,s1,s2,s3],axis=1)
pdf.columns = ['cv_average','train','test','all']
''' Visual Ouputs '''
sns.set(style="whitegrid")
fig,ax = plt.subplots(1,2,figsize=(15,4))
ax[0].set_title(f'{n_fold} Cross Validation Results')
sns.boxplot(data=lst_res, ax=ax[0], orient="v",width=0.3)
ax[0].set_xticklabels(names)
sns.stripplot(data=lst_res,ax=ax[0], orient='v',color=".3",linewidth=1)
ax[0].set_xticklabels(names)
ax[0].xaxis.grid(True)
ax[0].set(xlabel="")
if(cv_yrange is not None):
ax[0].set_ylim(cv_yrange)
sns.despine(trim=True, left=True)
sns.heatmap(pdf,vmin=hm_vvals[0],vmax=hm_vvals[1],center=hm_vvals[2],
ax=ax[1],square=False,lw=2,annot=True,fmt='.3f',cmap='Blues')
ax[1].set_title('Accuracy Scores')
plt.show()
基準(zhǔn)模型:使用原始行情數(shù)據(jù)作為特征
modelEval(df_tr1,split_id=[0.2,None])
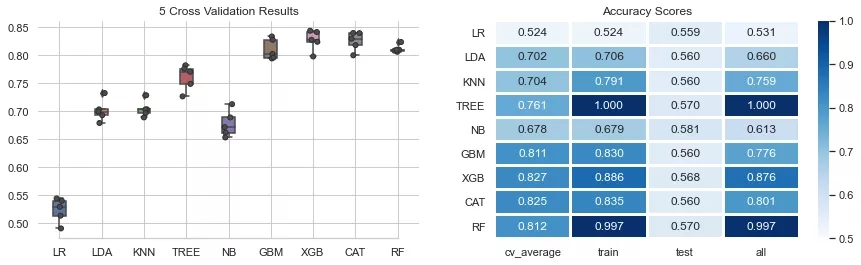
結(jié)果顯示,cross_val_score徘徊在準(zhǔn)確度= 0.5的區(qū)域,這表明僅使用指數(shù)/股票的價格數(shù)據(jù)(開盤、最高、最低、成交量、收盤)很難準(zhǔn)確預(yù)測價格變動的方向性。大多數(shù)模型的訓(xùn)練得分往往高于交叉驗證得分。有意思的是,DecisionTreeClassifier RandomForest即使很少估計可以達(dá)到非常高的分?jǐn)?shù),但交叉驗證的得分卻很低,表明對訓(xùn)練數(shù)據(jù)可能存在過度擬合了。
加入技術(shù)指標(biāo)特征
modelEval(df_tr2,split_id=[0.2,None],cv_yrange=(0.8,1.0),hm_vvals=[0.8,1.0,0.9])
結(jié)果表明,與基準(zhǔn)模型相比,準(zhǔn)確率得分有了非常顯著的提高。線性判別分析(LDA)的表現(xiàn)非常出色,不僅在訓(xùn)練集上,而且在交叉驗證中,得分顯著提高。毫無疑問,更復(fù)雜的模型GBM,XGB,CAT,RF在全樣本中評估得分較高。與有監(jiān)督學(xué)習(xí)模型相比,kNN和GaussianNB的無監(jiān)督模型表現(xiàn)較差。
特征的優(yōu)化
def feature_importance(ldf,feature='signal',n_est=100):
# Input dataframe containing feature target variable
X = ldf.copy()
y = ldf[feature].copy()
del X[feature]
# CORRELATION
imp = corrMat(ldf,feature,figsize=(15,0.5),ret_id=True)
del imp[feature]
s1 = imp.squeeze(axis=0);s1 = abs(s1)
s1.name = 'Correlation'
# SHAP
model = CatBoostRegressor(silent=True,n_estimators=n_est).fit(X,y)
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)
shap_sum = np.abs(shap_values).mean(axis=0)
s2 = pd.Series(shap_sum,index=X.columns,name='Cat_SHAP').T
# RANDOMFOREST
model = RandomForestRegressor(n_est,random_state=0, n_jobs=-1)
fit = model.fit(X,y)
rf_fi = pd.DataFrame(model.feature_importances_,index=X.columns,
columns=['RandForest']).sort_values('RandForest',ascending=False)
s3 = rf_fi.T.squeeze(axis=0)
# XGB
model=XGBRegressor(n_estimators=n_est,learning_rate=0.5,verbosity = 0)
model.fit(X,y)
data = model.feature_importances_
s4 = pd.Series(data,index=X.columns,name='XGB').T
# KBEST
model = SelectKBest(k=5, score_func=f_regression)
fit = model.fit(X,y)
data = fit.scores_
s5 = pd.Series(data,index=X.columns,name='K_best')
# Combine Scores
df0 = pd.concat([s1,s2,s3,s4,s5],axis=1)
df0.rename(columns={'target':'lin corr'})
x = df0.values
min_max_scaler = preprocessing.MinMaxScaler()
x_scaled = min_max_scaler.fit_transform(x)
df = pd.DataFrame(x_scaled,index=df0.index,columns=df0.columns)
df = df.rename_axis('Feature Importance via', axis=1)
df = df.rename_axis('Feature', axis=0)
pd.options.plotting.backend = "plotly"
fig = df.plot(kind='bar',title='Scaled Feature Importance')
fig.show()
feature_importance(df_tr2)
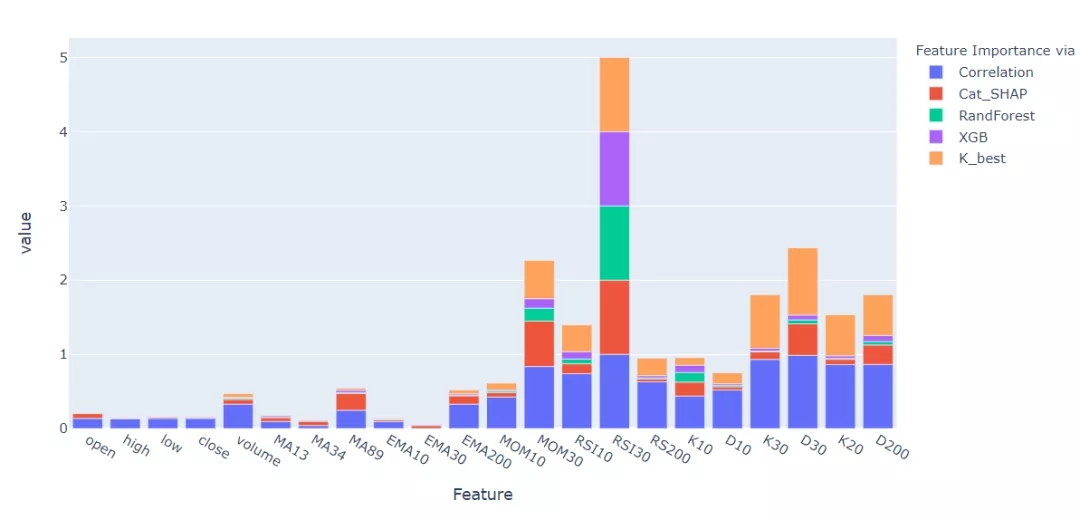
注意到,對于很多特征,相關(guān)性(Pearson's value)小的在其他方法中也會給出小的得分值。同樣,高相關(guān)的特征在其他特征重要性方法中得分也很高。當(dāng)談到特征的重要性時,有一些特征顯示出一些輕微的不一致,總的來說,大多數(shù)方法都可以觀察到特征評分的相似性。在機(jī)器學(xué)習(xí)中,某些特征對于大多數(shù)方法來說都有一個非常低的相對分?jǐn)?shù)值,因此可能沒有什么影響,即使把它們刪除,也不會降低模型的準(zhǔn)確性。刪除可能不受影響的特性將使整個方法更加有效,同時可以專注于更長和更深入的超參數(shù)網(wǎng)格搜索,可能得到比原來模型更準(zhǔn)確的結(jié)果。
df_tr2_FI = df_tr2.drop(columns=['open','high','low','close','EMA10'])
modelEval(df_tr2_FI,split_id=[0.2,None],cv_yrange=(0.8,1.0),hm_vvals=[0.8,1.0,0.9])
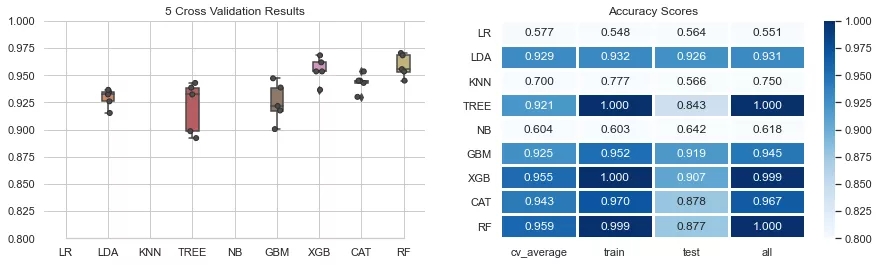
結(jié)語
本文只是以上證指數(shù)為例,以技術(shù)指標(biāo)作為特征,使用機(jī)器學(xué)習(xí)算法對股票交易信號(注意這里不是股價或收益率)進(jìn)行預(yù)測評估,目的在于向讀者展示Python機(jī)器學(xué)習(xí)在金融量化研究上的應(yīng)用。從金融維度來看,分析的深度較淺,實(shí)際上對股價預(yù)測有用的特征有很多,包括(1)外在因素, 如股票相關(guān)公司的競爭對手、客戶、全球經(jīng)濟(jì)、地緣政治形勢、財政和貨幣政策、資本獲取等。因此,公司股價可能不僅與其他公司的股價相關(guān),還與大宗商品、外匯、廣義指數(shù)、甚至固定收益證券等其他資產(chǎn)相關(guān);(2)股價市場因素,如很多投資者關(guān)注技術(shù)指標(biāo)。(3)公司基本面因素,如公司的年度和季度報告可以用來提取或確定關(guān)鍵指標(biāo),如凈資產(chǎn)收益率(ROE)和市盈率(price -to - earnings)。此外,新聞可以預(yù)示即將發(fā)生的事件,這些事件可能會推動股價向某個方向發(fā)展。當(dāng)關(guān)注股票價格預(yù)測時,我們可以使用類似的方法來構(gòu)建影響預(yù)測變量的因素,希望本文能起到拋磚引玉的作用。
以上就是python基于機(jī)器學(xué)習(xí)預(yù)測股票交易信號的詳細(xì)內(nèi)容,更多關(guān)于python 預(yù)測股票交易信號的資料請關(guān)注腳本之家其它相關(guān)文章!
您可能感興趣的文章:- Python實(shí)現(xiàn)對照片中的人臉進(jìn)行顏值預(yù)測
- python數(shù)據(jù)分析之用sklearn預(yù)測糖尿病
- Python預(yù)測2020高考分?jǐn)?shù)和錄取情況
- 詳解用Python進(jìn)行時間序列預(yù)測的7種方法
- 利用Python第三方庫實(shí)現(xiàn)預(yù)測NBA比賽結(jié)果
