目錄
- 一、引言
- 二、關于相關訪問請求及應答報文
- 2.1、百度搜索請求
- 2.2、百度返回搜索結果
- 2.3、小說網站關于最新更新的展現及html報文格式
- 三、實現思路及代碼
- 3.1、根據url獲取網站名
- 3.2、根據百度返回搜索結果地址打開網站獲取小說信息
- 3.3、獲取小說網頁絕對url地址
- 3.4、計算排序權重
- 3.5、進行百度搜索并解析搜索結果訪問小說網站最新更新
- 四、搜索案例
- 五、小結
一、引言
這個五一假期自駕回老家鄉下,家里沒裝寬帶,用手機熱點方式訪問網絡。這次回去感覺4G信號沒有以前好,通過百度查找小說最新更新并打開小說網站很慢,有時要打開好多個網頁才能找到可以正常打開的最新更新。為了躲懶,老猿決定利用Python爬蟲知識,寫個簡單應用自己查找小說最新更新并訪問最快的網站,花了點時間研究了一下相關報文,經過近一天時間研究和編寫,終于搞定,下面就來介紹一下整個過程。
二、關于相關訪問請求及應答報文
2.1、百度搜索請求
我們通過百度網頁的搜索框進行搜索時,提交的url請求是這樣的:
https://www.baidu.com/s?wd=搜索詞pn=10rn=50
請求的url為https://www.baidu.com/s,帶三個參數:
- wd:搜索的關鍵詞
- pn:當前需要顯示搜索結果記錄在總搜索結果的序號,如總搜索有300條記錄滿足要求,現在要求顯示第130條記錄,則pn參數值設為130即可
- rn:每頁顯示記錄數,缺省為10條,可以自行設定,但如果設定超過50,則會強制顯示為每頁10條。
2.2、百度返回搜索結果
百度返回的搜索結果有多種方式確定,老猿認為如下方式最簡單:
以搜索小說《青萍》為例來看其中的一個返回記錄:
h3 class="t">a data-click="{
'F':'778317EA',
'F1':'9D73F1E4',
'F2':'4CA6DE6B',
'F3':'54E5243F',
'T':'1620130755',
'y':'FE7FF57A'}"
rel="external nofollow" target="_blank">
em>青萍/em>最新章節,em>青萍/em>免費閱讀 - 大神小說網/a>
/h3>
整個搜索返回的結果在一個h3的標簽內,返回的搜索結果對應url在a標簽內,具體url由href來指定。這里返回的url實際上是一個百度重定向的地址,可以通過打開該url訪問對應網站,并通過返回響應消息獲取真正網站的URL。
2.3、小說網站關于最新更新的展現及html報文格式
根據老猿分析,約占30%的小說網站關于最新更新章節的展現類似如下:
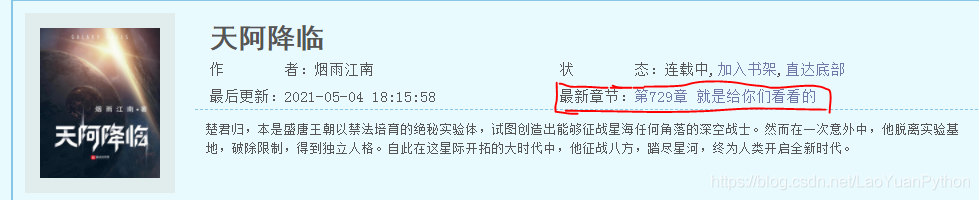
首先有類似“最新章節”或“最新更新”或“最近更新”等類似提示詞,在該提示詞后是顯示最新章節的章節序號及章節名的一個鏈接,對應的報文類似如下:
p>最新章節:a href="/book/12/12938/358787.html" rel="external nofollow" target="_blank">第729章 就是給你們看看的/a>/p>
這個報文的特點是:
“最新章節”的文本信息與小說最新章節的鏈接在同一個父標簽內。另外需要說明的是返回的章節url并不是絕對地址,而是小說網站的相對地址。
老猿對搜索小說查找最新章節都是基于以上格式的,因此實際上程序最終獲取的小說網站只占了整個搜索結果的30%左右,不過對于看小說來說已經足夠了。
三、實現思路及代碼
3.1、根據url獲取網站名
def getHostName(url):
httpPost = url[10:]
hostName = url[:10]+httpPost.split('/')[0]
return hostName
3.2、根據百度返回搜索結果地址打開網站獲取小說信息
基于2.3部分介紹的小說網站返回內容,我們來根據百度返回搜索結果的URL來打開對應小說網站,并計算從請求發起到響應返回的時間:
def getNoteInfo(url):
"""
打開指定小說網頁URL獲取最新章節信息
url:百度搜索結果指定的搜索匹配記錄的url
返回該URL對應的章節ID、打開耗時、網站真正URL、網站主機名、章節相對url、章節名
"""
head = mkhead()
start = time.time_ns()
req = urllib.request.Request(url=url, headers=head)
try:
resp = urllib.request.urlopen(req,timeout=2)
#根據響應頭獲取真正的網頁URL對應的網站名
hostName = getHostName(resp.url)
text = resp.read()
#網頁編碼有2種:utf-8和GBK
pageText = text.decode('utf-8')
except UnicodeDecodeError:
pageText = text.decode('GBK')
except Exception as e:
errInf = f"打開網站 {url} 失敗,異常原因:\n{e}\n" + '\n' + traceback.format_exc() + '\n'
logPag(errInf, False)
return None
#最新章節的HTML報文類似: 'p>最新章節:a href="/html/107018/122306672.html" rel="external nofollow" >第672章 天之關梁/a>/p>'
end = time.time_ns()
soup = BeautifulSoup(pageText, 'lxml')
# 根據最新章節的提示信息搜索最新章節
result = soup.find_all(string=re.compile(r'最新更新[::]|最新章節[::]|最近更新[::]|最新[::]'))
found = False
for rec in result:
recP = rec.parent
pa = recP.a
matchs = re.match(r'(?:最新更新|最新章節|最近更新|最新)[::]第(.+)章(.+)', recP.text)
if not matchs:return None
groups = matchs.groups()
if matchs and pa is not None:
found = True
chapter = toInt(groups[0]) #章節序號
chapterName = groups[1] #章節名
chaperUrl = pa.attrs['href'] #章節相對URL
break
if not found:
return None
cost = (end - start) / 1000000 #網頁打開耗時計算
return (chapter,cost,resp.url,hostName,chaperUrl,chapterName)
注意:由于不同網站訪問響應情況不一樣,因此在打開網頁時設定超時是很有必要的,這樣可以避免訪問緩慢的網站耽誤整體訪問時間。
3.3、獲取小說網頁絕對url地址
將返回信息中相對url和網站名結合拼湊網頁的絕對url地址:
def getChapterUrl(noteInf):
chapter, cost, url, hostName, chaperUrl, chapterName = noteInf
if chaperUrl.strip().startswith('http'):return chaperUrl
elif chaperUrl.strip().startswith('/'):return hostName.strip()+chaperUrl.strip()
else:return hostName.strip()+'/'+chaperUrl.strip()
3.4、計算排序權重
根據搜索小說網頁訪問的信息計算排序權重,確保最新章節排在最前,相同章節訪問速度最快網站排在最前。
def noteWeight(n):
#入參n為小說信息元組: chapter, cost, url, hostName, chaperUrl, chapterName
ch,co = n[:2]
w = ch * 100000 + min(99999, 100000 / co)
return w
3.5、進行百度搜索并解析搜索結果訪問小說網站最新更新
根據搜索詞在百度執行搜索,并取最新章節且訪問速度最快的前5個網站url進行輸出:
def BDSearchUsingChrome(inputword,maxCount=150):
"""
輸出相關搜索結果中具有最新章節且訪問速度最快的前5個網站url
:param word: 搜索關鍵詞,如小說名、小說名+作者名等
:param maxCount: 最多處理的搜索記錄數
:return: None
"""
#百度請求url類似:https://www.baidu.com/s?wd=青萍pn=10rn=50
rn = 50 #每頁50條記錄
#構建請求頭模擬本機谷歌瀏覽器訪問百度網頁
head = mkheadByHostForChrome('baidu.com')
word = urllib.parse.quote(inputword)
urlPagePre = 'https://www.baidu.com/s?wd='+word+'rn=50'
pageCount = int(0.999+maxCount/rn)
validNoteInf = []
seq = 0
logPag("開始執行搜索...")
for page in range(pageCount):
pn = rn*page
urlPage = urlPagePre+str(pn)
pageReq = urllib.request.Request(url=urlPage, headers=head)
pageResp = urllib.request.urlopen(pageReq,timeout=2)
pageText = pageResp.read().decode()
if pageResp.status == 200:
soup = BeautifulSoup(pageText,'lxml')
links = soup.select('h3.t a[href^="http://www.baidu.com/link?url="]')
for l in links:
noteInf = getNoteInfo(l.attrs['href'])
seq += 1
if noteInf is None:
#print(seq,'、',l.attrs['href'],None)
logPag(f"{seq}、{l.attrs['href']}:查找最新章節失敗,忽略",True)
else:
logPag(f"{seq}、返回小說信息: {noteInf}",True)
#chapter,cost,url,hostName,chaperUrl,chapterName = noteInf
validNoteInf.append(noteInf)
validNoteInf.sort(key=noteWeight,reverse=True)
print(f"小說: {inputword} 最新更新訪問最快的5個網站是:")
for l in validNoteInf[:5]:#輸出相關搜索結果中具有最新章節且訪問速度最快的前5個網站url
print(f"{validNoteInf.index(l)+1}、第{l[0]}章 {l[-1]} {getChapterUrl(l)} ,網頁打開耗時 {l[1]} 毫秒")
input("按回車鍵退出!")
四、搜索案例
以搜索月關大大的青萍作為案例,執行搜索的語句為:
BDSearchUsingChrome('青萍月關',150)
執行結果:
小說: 青萍月關 最新更新訪問最快的5個網站是:
1、第688章 東邊日出西邊雨 http://www.huaxiaci.com/41620/37631250.html ,網頁打開耗時 262.0 毫秒
2、第688章 東邊日出西邊雨 http://www.huaxiaci.com/41620/37631250.html ,網頁打開耗時 278.0 毫秒
3、第688章 東邊日出西邊雨 http://www.huaxiaci.com/41620/37631250.html ,網頁打開耗時 345.5 毫秒
4、第688章 東邊日出西邊雨 https://www.24kwx.com/book/9/9202/8889236.html ,網頁打開耗時 774.0 毫秒
5、第688章 東邊日出西邊雨 https://www.27kk.net/9526/2658932.html ,網頁打開耗時 800.5 毫秒
按回車鍵退出!
五、小結
本文介紹了使用Python搜索指定小說最新更新章節以及訪問最快網站的實現思想和關鍵應用代碼,實現自動搜索小說最新更新章節以及獲取訪問最快的網站。以上的實現由于已經獲取最新章節的鏈接,再稍微改進,就可以直接將最新章節下載到本地觀看。
到此這篇關于Python爬蟲之爬取最新更新的小說網站的文章就介紹到這了,更多相關Python爬取最新更新的小說網站內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- python使用XPath解析數據爬取起點小說網數據
- python爬蟲之爬取筆趣閣小說
- python爬取晉江文學城小說評論(情緒分析)
- Python爬蟲入門教程02之筆趣閣小說爬取
- python 爬取小說并下載的示例
- python爬取”頂點小說網“《純陽劍尊》的示例代碼
- Python scrapy爬取小說代碼案例詳解
- Python爬取365好書中小說代碼實例
- python爬蟲爬取筆趣網小說網站過程圖解
- Python實現的爬取小說爬蟲功能示例
- Python制作爬蟲采集小說
- python 爬取國內小說網站
