前言
說到二手房信息,不知道你們心里最先跳出來的公司(網站)是什么,反正我心里第一個跳出來的是網站是 58 同城。哎呦,我這暴脾氣,想到就趕緊去干。
但很顯然,我失敗了。說顯然,而不是不幸,這是因為 58 同城是大公司,我這點本事爬不了數據是再正常不過的了。下面來看看 58 同城的反爬手段了。這是我爬取下來的網頁源碼。

我們看到爬取下來的源碼有很多英文大寫字母和數字是網頁源碼中沒有的,后來我了解到 58 同城對自己的網站的源碼進行了文本加密,所以就出現了我爬取到的情況。
爬取二手房信息
我打開 58 同城的 robots 協議。

好家伙,不愧是大公司,所有的動態網址都不讓爬取,打擾了。我只好轉頭離開,去尋找可以讓我這種小白爬取的二手房網站。于是我找到了c21網站,不知道是我的原因,還是別的原因,反正我是沒有找到這個網站的 robots 協議。不管了,既然沒找到,就默認沒有吧,直接開始爬取。
我本來打算通過二手房的目錄跳到一個具體信息,然后爬取二手房的一些基本信息和屬性。
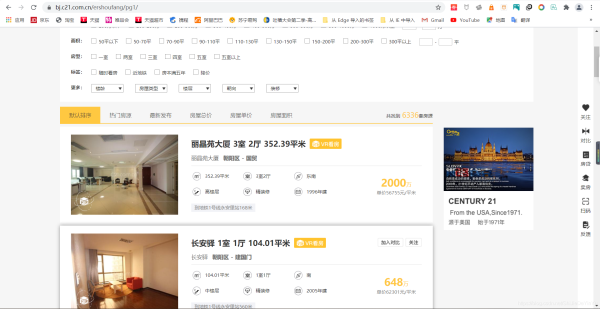
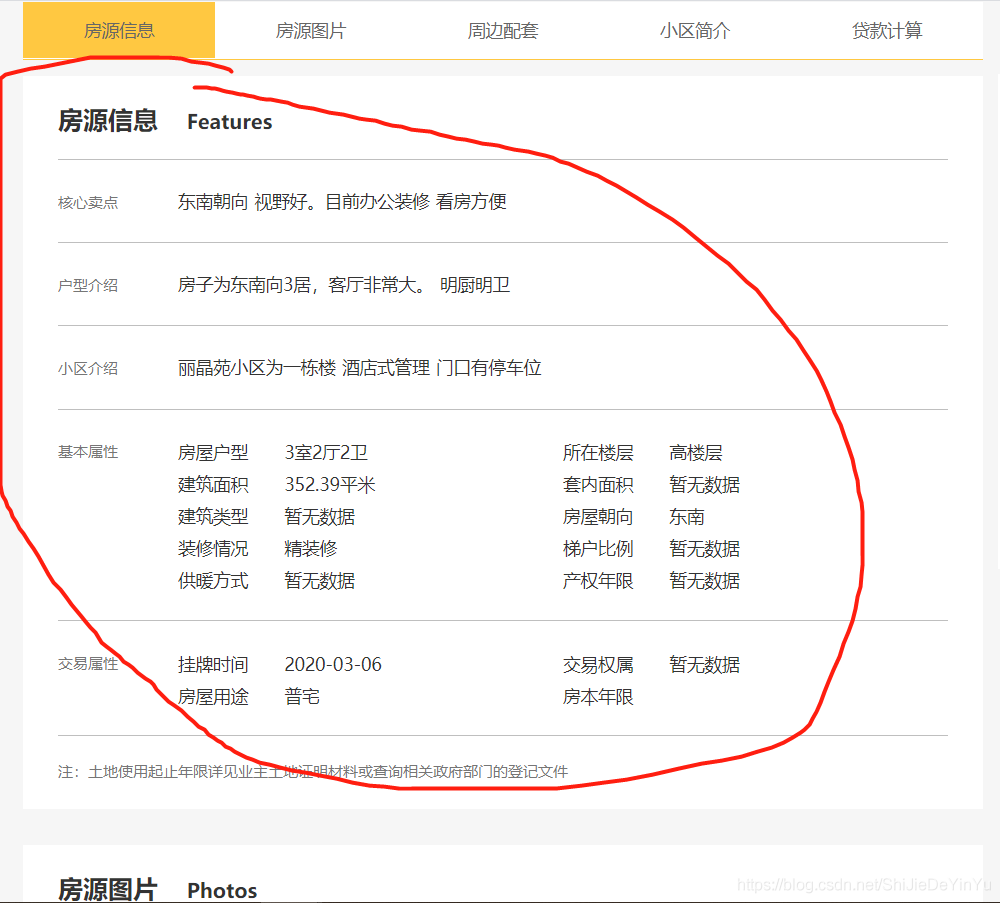
像我紅筆圈起來的部分。但很可惜我失敗了,后來我看了看紅筆圈起來的部分的爬取到的源碼。
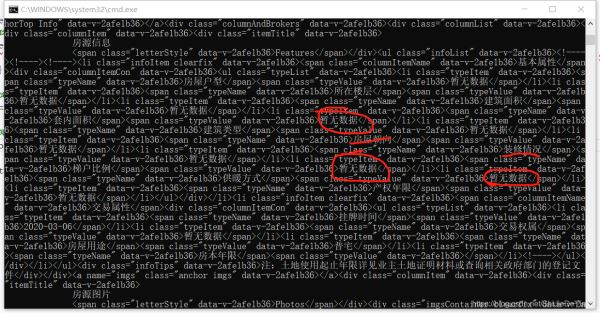
好家伙,還可以這樣。不過這怎么可以難倒機智的我?(其實我真不知道怎么解決它)。沒關系,之前的源碼里不是有類似的信息嗎?我只好將就一下了。
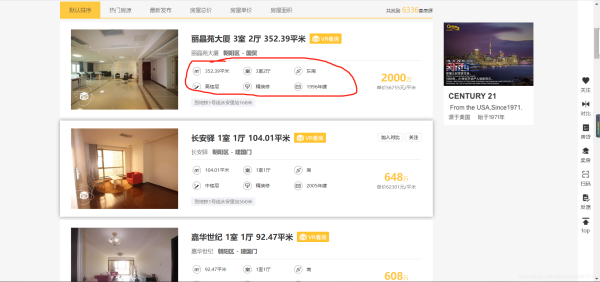
然后是翻頁。翻頁問題很好解決,我們很快就發現網頁都是 https://bj.c21.com.cn/ershoufang/pg2/。其中的頁數和 pg 后面的數字有關。
然后就是分析這些數據源碼的位置了。
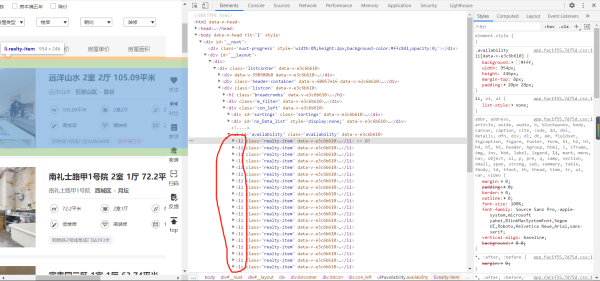
首先,我們發現我們要爬取的數據全在 li 標簽里,所以我們可以先獲得 li 標簽的列表。偽代碼就像這樣。
form lxml import etree
…… ……
tree = etree.HTML(源碼)
li_list = tree.xpath( li 標簽的路徑)
這時候我們獲得的就是 li 標簽的 etree 的類,可以繼續使用 etree 類里的函數。然后我們就可以利用 for 循環提出不同房源的 li 標簽,根據自己的需要獲取文本信息。
歐克,了解了這些(感覺源碼前前后后就是四個字 ”我是菜雞“ )我們就可以開始寫代碼了。
import requests
from lxml import etree
import re
if __name__ == "__main__":
# UA偽裝
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"
}
for pg in range(1, 3): # 翻兩頁
# 指定 url
url = "https://bj.c21.com.cn/ershoufang/pg%s/" % str(pg)
# 獲取網頁源碼
page = requests.get(url = url, headers = header).text
# xpath 解析
tree = etree.HTML(page)
li_list = tree.xpath('//ul[@id="availability"]/li')
for li in li_list:
title = li.xpath('div[2]/div/a/text()')[0] # 房子的名稱
# print(title[0]) # 測試
add = li.xpath('div[2]/div/p//a/text()') # 地址
add = add[-2: ] + add[0:1] # 地址范圍由大到小
# print(add) # 測試
div_list = li.xpath('div[2]/div[2]/div')
# 具體信息
message_list = ["建筑面積", "房屋戶型", "房屋朝向", "所在樓層", "裝修情況", "建成時間"]
for i in range(6):
div = div_list[i]
message = div.xpath('span/text()')[0]
message = re.sub("\s", "", str(message)) # 因為發現獲取的文本有很多換行符和空格,所以需要去掉
message = re.sub("\\n", "", str(message))
message_list[i] = message_list[i] + ":" + message
# print(message_list) # 測試
# 交通情況
traffic = li.xpath('div[2]/div[4]//text()')
# print(traffic) # 測試
# 價格情況
price = li.xpath('div[2]/div[3]//text()')
price = price[0] + price[1]
# print(price) # 測試
with open("C:\\Users\\ASUS\\Desktop\\CSDN\\數據解析\\xpath\\二手房\\" + "二手房.txt", "a", encoding = "utf-8") as fp:
fp.write(title + "\n")
for message in message_list:
fp.write(message + "\n")
if traffic == []:
fp.write("交通情況:無介紹" + "\n")
else:
fp.write("交通情況:" + traffic[0] + "\n")
fp.write("價格:" + price + "\n\n")
print(title, "下載完成!!!")
print("over!!!")
爬取結果
最后的運行結果就像這樣

到此這篇關于Python爬蟲之爬取二手房信息的文章就介紹到這了,更多相關Python爬取二手房信息內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Python手拉手教你爬取貝殼房源數據的實戰教程
- Python scrapy爬取蘇州二手房交易數據
- Python爬蟲之爬取我愛我家二手房數據
- python爬取鏈家二手房的數據
- 基于python爬取鏈家二手房信息代碼示例
- python爬蟲 爬取58同城上所有城市的租房信息詳解
- Python爬蟲入門案例之爬取二手房源數據
