from selenium import webdriver
from PIL import Image
import base64
import requests
import time
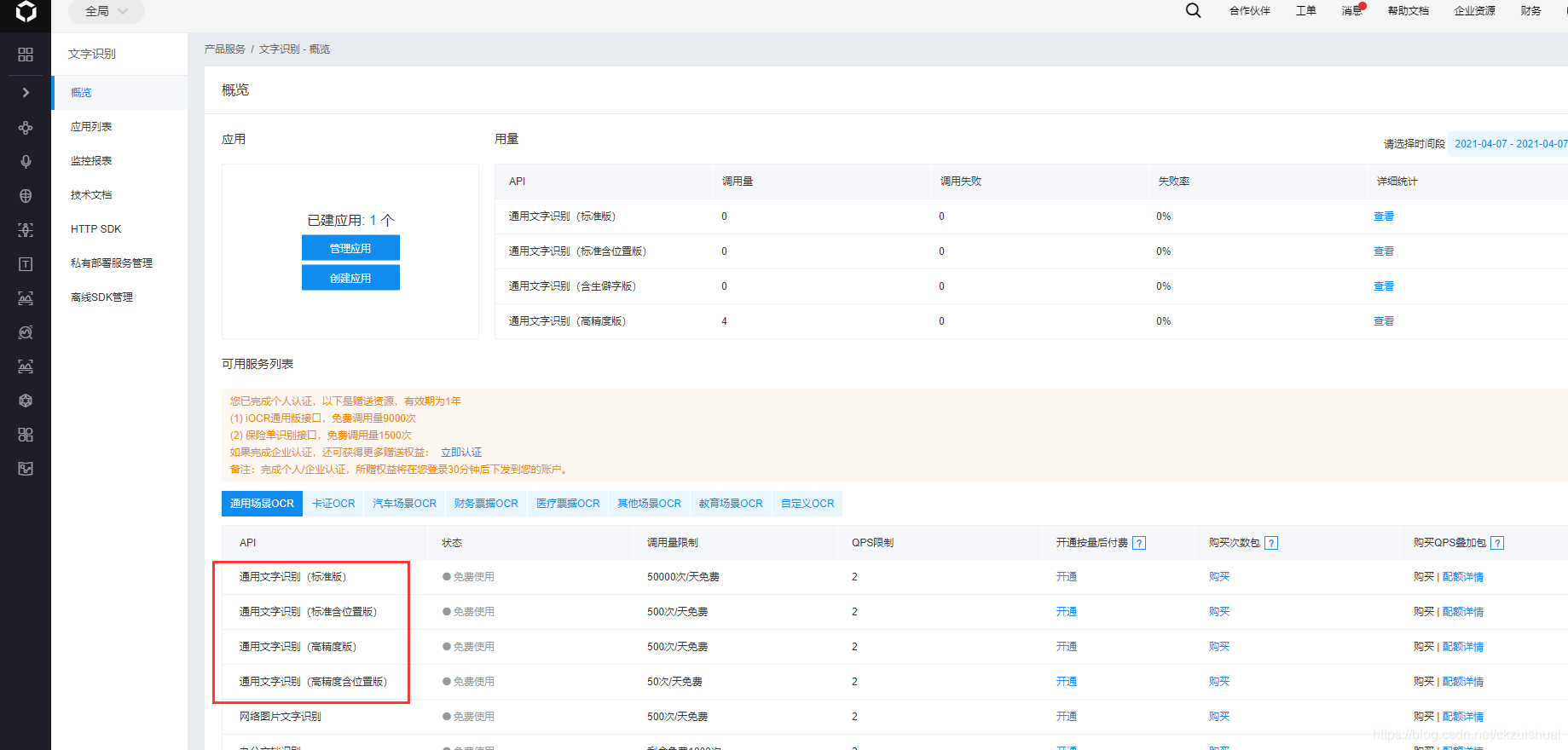
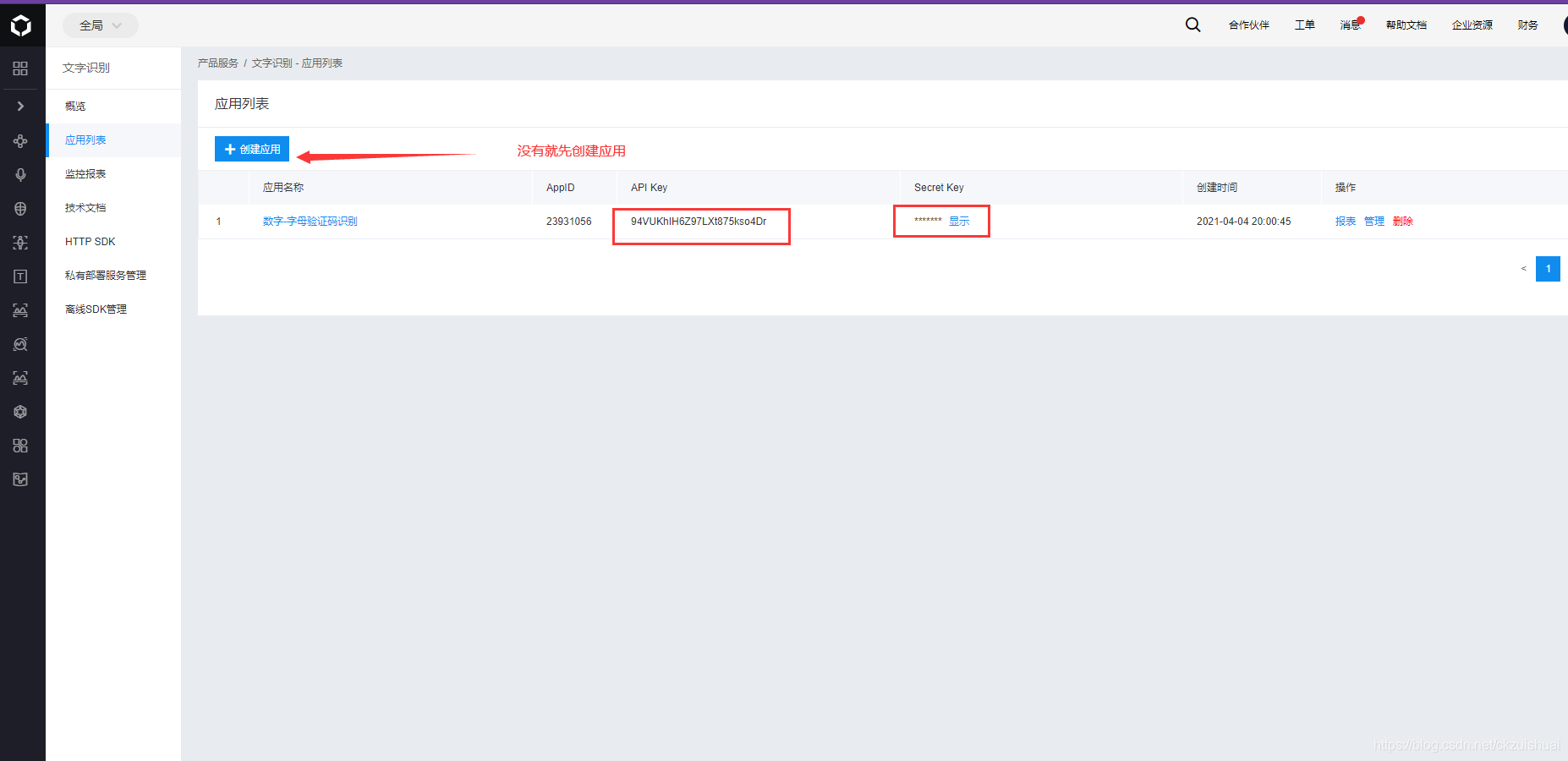
def baidu_api(Verification_code, AK, SK):#Verification_code驗證碼路徑,AK,SK百度云的身份識別碼
chrome.get_screenshot_as_file('reg.png') # 獲取登陸頁面的圖片
code_img = chrome.find_element_by_xpath(Verification_code) # 找到驗證碼圖片的位置
img = Image.open('reg.png')# 保存圖片
c_img = img.crop((code_img.location['x'], code_img.location['y'], code_img.location['x'] + code_img.size['width'],
code_img.location['y'] + code_img.size['height'])) # 截取驗證碼圖片
c_img.save('reg_code.png')
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials' \
'client_id='+AK+'' \
'client_secret='+ SK
response = requests.get(host)
token = response.json()['access_token']
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
f = open('reg_code.png', 'rb')# 二進制方式打開圖片文件
img = base64.b64encode(f.read())
params = {"image": img}
access_token = token
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
dict_a = response.json()['words_result']
if response:
dict_a = eval(str(dict_a)[1:-1])#數據類型的格式轉換
dict_a = dict(dict_a)#轉化為字典類型
dict_a = dict_a['words']
dict_a = "".join(dict_a.split()) # 使用一個空字符串合成列表內容生成新的字符串
dict_a = dict_a.lower()#把大寫字母改為小寫字母
return dict_a
else:
chrome.refresh()
chrome = webdriver.Chrome()#瀏覽器實例化
chrome.maximize_window()#最大化瀏覽器
chrome.get('自己登陸的網址')
test = baidu_api(Verification_code, AK, SK)#返回識別的驗證碼
chrome = webdriver.Chrome()
print(test)#驗證碼
到此這篇關于python自動化調用百度api解決驗證碼的文章就介紹到這了,更多相關python調用百度api驗證碼內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家��!