目錄
- python 語(yǔ)法簡(jiǎn)要介紹
- 爬取網(wǎng)頁(yè)
- 解析網(wǎng)頁(yè)
- 儲(chǔ)存網(wǎng)頁(yè)
python作為一種已經(jīng)廣泛傳播且相對(duì)易學(xué)的解釋型語(yǔ)言,現(xiàn)如今在各方面都有著廣泛的應(yīng)用。而爬蟲(chóng)則是其最為我們耳熟能詳?shù)膽?yīng)用,今天筆者就著重針對(duì)這一方面進(jìn)行介紹。
python 語(yǔ)法簡(jiǎn)要介紹
python 的基礎(chǔ)語(yǔ)法大體與c語(yǔ)言相差不大,由于省去了c語(yǔ)言中的指針等較復(fù)雜的結(jié)構(gòu),所以python更被戲稱為最適合初學(xué)者的語(yǔ)言。而在基礎(chǔ)語(yǔ)法之外,python由其龐大的第三方庫(kù)組成,而其中包含多種模塊,而通過(guò)模塊中包含的各種函數(shù)與方法能夠幫助我們實(shí)現(xiàn)各種各樣的功能。
而在python爬蟲(chóng)中,我們需要用到的標(biāo)準(zhǔn)庫(kù)有:
其中urllib庫(kù)可以幫助我們爬取目標(biāo)網(wǎng)頁(yè)的html代碼,bs4中的beautifulsoup模塊以及re庫(kù)中的正則表達(dá)式可以將我們需要的數(shù)據(jù)從代碼中提取出來(lái),而xlwt庫(kù)可以將數(shù)據(jù)儲(chǔ)存至excel表中,從而最終完成數(shù)據(jù)的爬取。
接下來(lái),就步入我們此次介紹的重點(diǎn)——完整爬取一個(gè)網(wǎng)頁(yè)的數(shù)據(jù)。
本篇文章以爬取豆瓣電影top250的數(shù)據(jù)為例,并將爬取的過(guò)程分為三個(gè)部分:
1.爬取網(wǎng)頁(yè)
2.解析網(wǎng)頁(yè)
3.儲(chǔ)存網(wǎng)頁(yè)
那么,讓我們開(kāi)始吧!
豆瓣top250網(wǎng)址:https://movie.douban.com/top250?start=
爬取網(wǎng)頁(yè)
引入urllib庫(kù)中的request模塊
urllib庫(kù)的基本操作可參考該網(wǎng)址:
https://www.jb51.net/article/209542.htm
def askURL(url):
head = {
"User-Agent": "Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 88.0.4324.182Safari / 537.36"
}# 模擬瀏覽器的登錄
request = urllib.request.Request(url,headers=head)
#將網(wǎng)頁(yè)的url和頭部信息封裝至一起
response = urllib.request.urlopen(request)
#獲取網(wǎng)頁(yè)的html代碼
html = response.read().decode("utf-8")
#將獲取的數(shù)據(jù)轉(zhuǎn)化為utf-8格式
#print(html) #此步可以實(shí)驗(yàn)一下能否成功爬取網(wǎng)頁(yè)的html代碼
return html
1.其中urllib.request.Request可以幫我們把要爬取的網(wǎng)頁(yè)的url及其他的頭部信息封裝至一起。
2.urlopen函數(shù)則可以幫助我們爬取下該網(wǎng)頁(yè)的html代碼
3.有一些網(wǎng)站會(huì)設(shè)置一下反爬機(jī)制來(lái)阻止我們的爬蟲(chóng),此時(shí)就需要我們?cè)O(shè)置頭部信息來(lái)模擬瀏覽器訪問(wèn)網(wǎng)站
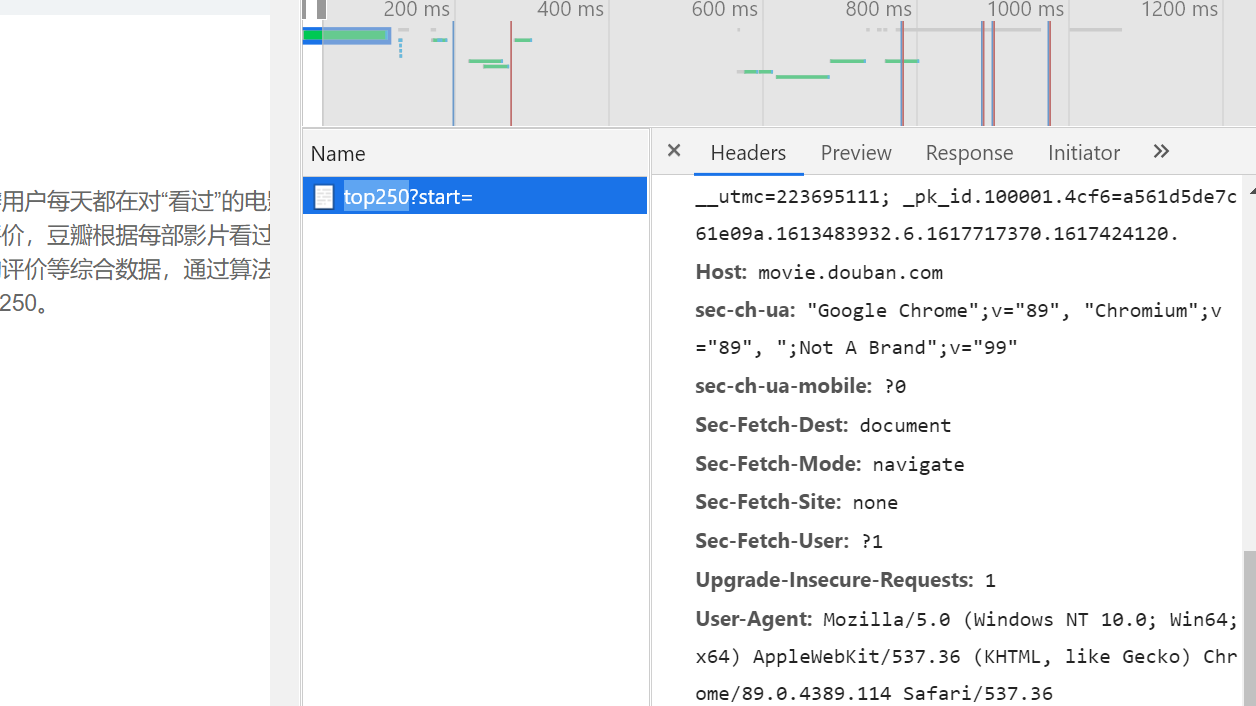
需要用瀏覽器進(jìn)入該網(wǎng)址,使用開(kāi)發(fā)者模式獲取我們需要的頭部信息(也就是該圖中的user-agent)
4.最后需要將我們的爬取下的html代碼轉(zhuǎn)化為utf-8格式進(jìn)行輸出
解析網(wǎng)頁(yè)
import re
from bs4 import BeautifulSoup
引入re庫(kù)和bs4庫(kù)
def getData(baseurl):
datalist = [] #建立一個(gè)存放解析出的數(shù)據(jù)的元組
for i in range(0,10):
url = baseurl + str(i*25)
# 通過(guò)以下兩張截圖,我們可以發(fā)現(xiàn)豆瓣將每25部電影分為一頁(yè),共分成了10頁(yè)、
# 而其url的差別僅在最后加了25,故通過(guò)該規(guī)律,可將所有10張網(wǎng)頁(yè)的url全部獲取
html = askURL(url)
soup = BeautifulSoup(html,"html.parser")
#通過(guò)beautifulsoup模塊自帶的html代碼解析器進(jìn)行解析
#并將解析器解析出的數(shù)據(jù)放至soup中

逐頁(yè)進(jìn)行解析,使解析出的數(shù)據(jù)能被我們接下來(lái)要使用的正則表達(dá)式識(shí)別
所謂正則表達(dá)式,就是對(duì)字符串操作的一種邏輯公式,就是用事先定義好的一些特定字符、及這些特定字符的組合,組成一個(gè)“規(guī)則字符串”,這個(gè)“規(guī)則字符串”用來(lái)表達(dá)對(duì)字符串的一種過(guò)濾邏輯,通過(guò)這種過(guò)濾,就可以得到我們想要的信息,就例如影片的名稱,評(píng)分等信息。
findlink = re.compile(r'a href="(.*?)" rel="external nofollow" >') # r表示不受轉(zhuǎn)義字符的影響
#該代碼通過(guò)正則表達(dá)式搜尋到所有關(guān)于影片鏈接的數(shù)據(jù),以下代碼類似
findImgSrc = re.compile(r'img.*src="(.*?)"',re.S) #讓換行符包含在字符中
findtitle = re.compile(r'span class="title">(.*)/span>')
findscore = re.compile(r'span class="rating_num" property="v:average">(.*)/span>')
findjudge = re.compile(r'span>(\d*)人評(píng)價(jià)/span>')
findinq = re.compile(r'span class="inq">(.*)/span>')
findbd = re.compile(r'p class="">(.*?)/p>',re.S)
for item in soup.find_all("div",class_="item"):
#提取所有class為“item”的div模塊,并通過(guò)for循環(huán)一步步處理
data = []
item = str(item) #將item轉(zhuǎn)化為字符串類型
link = re.findall(findlink,item)[0]
#通過(guò)影片詳情鏈接的正則表達(dá)式抽取數(shù)據(jù)
data.append(link)
#存放至data列表中
ImgSrc = re.findall(findImgSrc,item)[0]
data.append(ImgSrc)
title = re.findall(findtitle,item)
if len(title)==2:
#如果影片有多個(gè)名稱,則分別進(jìn)行存儲(chǔ)
ctitle = title[0]
data.append(ctitle)
otitle = title[1].replace("/","")
data.append(otitle)
else:
data.append(title[0])
data.append(" ")
score = re.findall(findscore,item)
data.append(score)
judge = re.findall(findjudge,item)
data.append(judge)
inq = re.findall(findinq,item)
if len(inq)!=0:
inq = inq[0].replace("。","")
data.append(inq)
else:
data.append("")
#若有影片詳情,則輸出;若沒(méi)有,則輸出為空
bd = re.findall(findbd,item)[0]
bd = re.sub('br(\s+)?/>(\s+)?'," ",bd)
bd = re.sub('/'," ",bd)
data.append(bd.strip()) # 去掉前后空格
datalist.append(data)
print(datalist)
return datalist
以上代碼能通過(guò)正則表達(dá)式抽取出需要的數(shù)據(jù)存放data列表中,然后將所有的data數(shù)據(jù)存放至datalist列表中。
儲(chǔ)存網(wǎng)頁(yè)
將解析出的數(shù)據(jù)儲(chǔ)存到excel表中
引入xlwt庫(kù)
xlwt的基本操作可參考該網(wǎng)址:
https://www.jb51.net/article/209536.htm
def savepath(datalist):
workbook = xlwt.Workbook(encoding="utf-8")
#創(chuàng)建以u(píng)tf-8格式編碼的一個(gè)workbook對(duì)象,該對(duì)象最后能保存為excel表格
worksheet = workbook.add_sheet("sheetwdy")
#創(chuàng)建工作表“sheetwdy”
col = ("電影詳情鏈接", "圖片鏈接", "影片中文名", "影片外國(guó)名", "評(píng)分", "評(píng)價(jià)數(shù)", "概況", "相關(guān)信息")
#創(chuàng)建一個(gè)元組
for i in range(0, 8):
worksheet.write(0, i, col[i])
# 將我們剛定義的元組中的信息寫(xiě)入excel表的第一行
for i in range(0, 250):
print("第%d條" % (i + 1))
data = datalist[i]
for j in range(0, 8):
worksheet.write(i + 1, j, data[j])
#將解析出的數(shù)據(jù)通過(guò)for循環(huán)一條條導(dǎo)入excel表中
workbook.save("豆瓣250.xls")
#將該excel表進(jìn)行保存
如此我們便可以把解析出的數(shù)據(jù)存儲(chǔ)至excel表中了
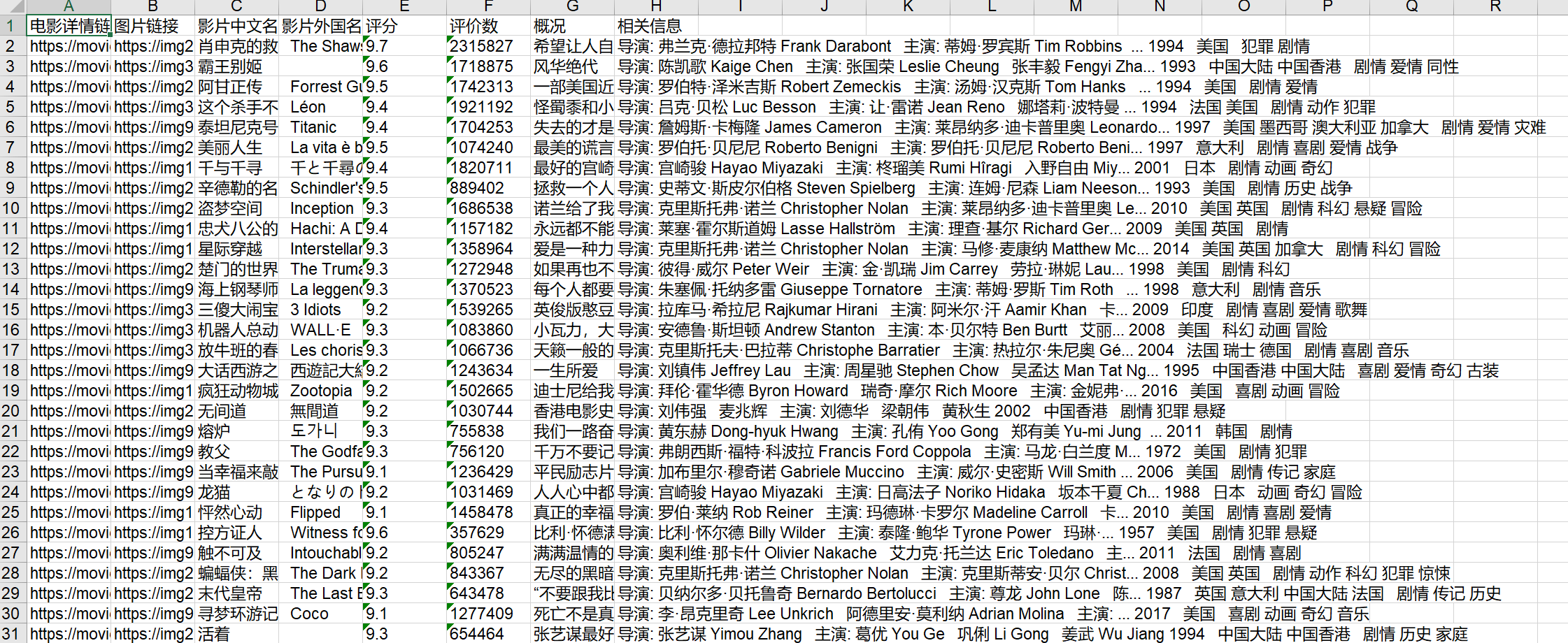
以上便為成品圖
以上就是python 爬取豆瓣網(wǎng)頁(yè)的示例的詳細(xì)內(nèi)容,更多關(guān)于python 爬取豆瓣網(wǎng)頁(yè)的資料請(qǐng)關(guān)注腳本之家其它相關(guān)文章!
您可能感興趣的文章:- python爬取各省降水量及可視化詳解
- python爬蟲(chóng)之教你如何爬取地理數(shù)據(jù)
- Python爬蟲(chóng)之教你利用Scrapy爬取圖片
- python基于scrapy爬取京東筆記本電腦數(shù)據(jù)并進(jìn)行簡(jiǎn)單處理和分析
- 教你如何用python爬取王者榮耀月收入流水線
- 用python爬蟲(chóng)爬取CSDN博主信息
- Python爬蟲(chóng)爬取全球疫情數(shù)據(jù)并存儲(chǔ)到mysql數(shù)據(jù)庫(kù)的步驟
- Python爬蟲(chóng)之爬取2020女團(tuán)選秀數(shù)據(jù)
