pandas讀取txt文件
讀取txt文件需要確定txt文件是否符合基本的格式,也就是是否存在\t,,,等特殊的分隔符
一般txt文件長成這個樣子
txt文件舉例
下面的文件為空格間隔
1 2019-03-22 00:06:24.4463094 中文測試
2 2019-03-22 00:06:32.4565680 需要編輯encoding
3 2019-03-22 00:06:32.6835965 ashshsh
4 2017-03-22 00:06:32.8041945 eggg
讀取命令采用 read_csv或者 read_table都可以
import pandas as pd
df = pd.read_table("./test.txt")
print(df)
import pandas as pd
df = pd.read_csv("./test.txt")
print(df)
但是,注意,這個地方讀取出來的數據內容為3行1列的DataFrame類型,并沒有按照我們的要求得到3行4列
import pandas as pd
df = pd.read_csv("./test.txt")
print(type(df))
print(df.shape)
class 'pandas.core.frame.DataFrame'>
(3, 1)
read_csv函數
默認: 從文件、URL、文件新對象中加載帶有分隔符的數據,默認分隔符是逗號。
上述txt文檔并沒有逗號分隔,所以在讀取的時候需要增加sep分隔符參數
df = pd.read_csv("./test.txt",sep=' ')
read_pickle函數
read_pickle is only guaranteed to be backwards compatible to pandas 0.20.3.
Examples
>>> original_df = pd.DataFrame({"foo": range(5), "bar": range(5, 10)})
>>> original_df
foo bar
0 0 5
1 1 6
2 2 7
3 3 8
4 4 9
>>> pd.to_pickle(original_df, "./dummy.pkl")
>>> unpickled_df = pd.read_pickle("./dummy.pkl")
>>> unpickled_df
foo bar
0 0 5
1 1 6
2 2 7
3 3 8
4 4 9
>>> import os
>>> os.remove("./dummy.pkl")
補充:線上部署模型 讀取pkl文件跟excel
先把生成的excel文件(pkl文件)準備好, 放到本地測試的路徑下
import platform
import pandas as pd
if platform.system() == 'Windows':
home_dir = r'F:\python_項目\主后臺\r360_taobao\moxin' #本地地址
else:
home_dir = r'/home/TG_MASTER_ADMIN_API/r360_taobao/moxin' #線上的路徑找到文件前一個文件夾
def testMx():
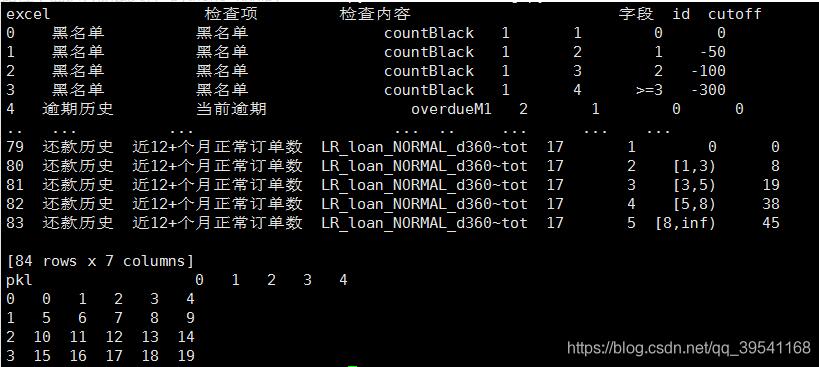
box = pd.read_excel(home_dir+'/規則新版設計1.xlsx', sheet_name='宜信標準評分卡')
print("excel\t\t",box)
box = pd.read_pickle(home_dir + '/foo.pkl')
print("pkl\t\t",box)
if __name__ == '__main__':
testMx()
本地測試

給線上傳代碼
找到主文件路徑下面運行測試文件 python3 xxx.py
不好使的話去項目文件 框架下面 寫一個測試文件 把那個方法寫進來 python3 XXX.py就OK了
以上為個人經驗,希望能給大家一個參考,也希望大家多多支持腳本之家。如有錯誤或未考慮完全的地方,望不吝賜教。
您可能感興趣的文章:- 如何使用pandas讀取txt文件中指定的列(有無標題)
- pandas 把數據寫入txt文件每行固定寫入一定數量的值方法
- python利用pandas將excel文件轉換為txt文件的方法
- pandas學習之txt與sql文件的基本操作指南
