概述
groupby()可以根據DataFrame中的某一列或者多列內容進行分組聚合,當DataFrame聚合后為兩列索引時,可以使用unstack()將聚合的兩列中一列值調整為行索引,另一列的值調整為列索引。
代碼說明
test_df = pd.DataFrame({ 'col_1':['a', 'a', 'b', 'a', 'a', 'b', 'c', 'a', 'c'],
'col_2':['d', 'd', 'd', 'e', 'f', 'e', 'd', 'f', 'f'],
'col_3':[ 1, 2, 3, 1, 4, 5, 6, 4, 5]})
1.僅對數據進行分組聚合
df1=test_df.groupby(['col_1', 'col_2']).count()
df1:
col_3
col_1 col_2
a d 2
e 1
f 2
b d 1
e 1
c d 1
f 1
df.index:
MultiIndex(levels=[['a', 'b', 'c'], ['d', 'e', 'f']],
labels=[[0, 0, 0, 1, 1, 2, 2], [0, 1, 2, 0, 1, 0, 2]],
names=['col_1', 'col_2'])
df1.columns:
Index(['col_3'], dtype='object')
2.對分組聚合后的數據進行unstack
df2=test_df.groupby(['col_1', 'col_2']).count().unstack()
df2:
col_3
col_2 d e f
col_1
a 2.0 1.0 2.0
b 1.0 1.0 NaN
c 1.0 NaN 1.0
df2.index:
Index(['a', 'b', 'c'], dtype='object', name='col_1')
df2.columns:
MultiIndex(levels=[['col_3'], ['d', 'e', 'f']],
labels=[[0, 0, 0], [0, 1, 2]],
names=[None, 'col_2'])
3.對分組聚合后的某列進行unstack
df3=test_df.groupby(['col_1', 'col_2']).count()['col_3'].unstack()
df3:
col_2 d e f
col_1
a 2.0 1.0 2.0
b 1.0 1.0 NaN
c 1.0 NaN 1.0
df.index:
Index(['a', 'b', 'c'], dtype='object', name='col_1')
de.columns:
Index(['d', 'e', 'f'], dtype='object', name='col_2')
補充:pandas中pivot()方法和groupby()方法的說明和對比
pandas中有兩個很有用的方法,pivot()或者pivot_table()和groupby(),其中pivot()方法是指定相應的列分別作為行標簽和列標簽,并指定相應的列作為值,然后重新生成一個新的DataFrame對象,這樣的好處是使得數據更加的直觀和容易分析,俗稱數據透視;而groupby()方法是指定相應的列進行分組,把這列中具有相同值的行分為同一組,這個過程稱為分組,返回一個groupby對象,一般的,分組之后會伴有聚合運算,即對每組進行需要的聚合運算(比如求和求積等)。
因此,pivot()方法是為了讓數據重新排列組合,使其更直觀,數據透視;而groupby()方法則是對數據進行分組聚合運算;兩者實際上功能特點很明顯,并沒有什么可比性,只是在利用這兩種方法時,原數據的結構是有些相似的,僅此而已;anyway,本文硬是把兩者放在一起比較確實有些牽強的。
但實際上本文的目的是通過使用這兩種不同的方法達成一個相同的目的,由此明晰兩種方法的用法和優劣勢,并由此更好的掌握它們。
首先我們構造一個DataFrame對象,如圖。
其中reindex方法是為了調換name和date兩列的順序。

現在我們有一個目標是去計算每個人在所有日期的總的value,對此,我們先用pivot()方法看看如何實現。
如下圖,首先對df1利用pivot()方法進行重新排列,具體的參數如圖,以name為行標簽,date為列標簽,values為值,其中在原表中沒有對應值,則顯示NaN。
經過重新排列,我們可以很直觀的看出在原表中name和data兩列對應值的對應關系,這更有助于我們分析name、date、values這三列的關系,這才是pivot()方法的主要功能。
當然,對于我們最初的目標,我們可以通過對NaN填充0值,然后再對每列求和即可,即df2.sum(axis=1)。
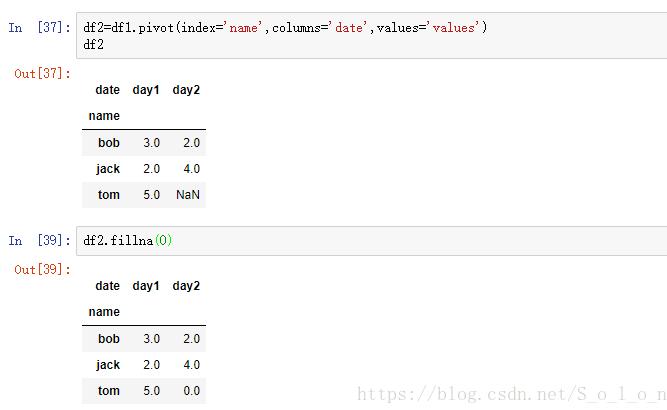
然后,我們再用groupby()方法來實現我們的目標,具體代碼如圖。
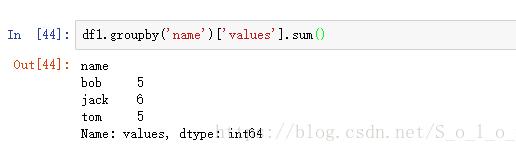
這里,我們只要對name列進行分組,得到分組后的groupby對象,然后再對values列進行求和,最后就會返回每個名字對應的總的value。
通過以上論述,可知要達成我們的最初的目標,顯然groupby()方法要簡單的多,這當然是由于pivot()和grouby()的功能特性所決定的,因為這本來就是groupby()所擅長的。
這里用pivot()來實現我們的目標雖然是可以,但是明顯大材小用了。
我們通過這些例子就是想說明兩者的用法,以及不同的功能特點,以此更好的掌握和理解這兩種方法。
以上為個人經驗,希望能給大家一個參考,也希望大家多多支持腳本之家。如有錯誤或未考慮完全的地方,望不吝賜教。
您可能感興趣的文章:- pandas groupby分組對象的組內排序解決方案
- pandas數據分組groupby()和統計函數agg()的使用
- pandas之分組groupby()的使用整理與總結
- Pandas之groupby( )用法筆記小結
- 利用Pandas和Numpy按時間戳將數據以Groupby方式分組
- Pandas GroupBy對象 索引與迭代方法
- 淺談pandas用groupby后對層級索引levels的處理方法
- pandas獲取groupby分組里最大值所在的行方法
- Pandas groupby apply agg 的區別 運行自定義函數說明
