1、sql語句的模塊解析
當我們寫一個查詢語句時,一般包含三個部分,select部分,from數據源部分,where限制條件部分,這三部分的內容在sql中有專門的名稱:

當我們寫sql時,如上圖所示,在進行邏輯解析時會把sql分成三個部分,project,DataSource,Filter模塊,當生成執行部分時又把他們稱為:Result模塊、
DataSource模塊和Opertion模塊。
那么在關系數據庫中,當我們寫完一個查詢語句進行執行時,發生的過程如下圖所示:

整個執行流程是:query -> Parse -> Bind -> Optimize -> Execute
1、寫完sql查詢語句,sql的查詢引擎首先把我們的查詢語句進行解析,也就是Parse過程,解析的過程是把我們寫的查詢語句進行分割,把project,DataSource和Filter三個部分解析出來從而形成一個邏輯解析tree,在解析的過程中還會檢查我們的sql語法是否有錯誤,比如缺少指標字段、數據庫中不包含這張數據表等。當發現有錯誤時立即停止解析,并報錯。當順利完成解析時,會進入到Bind過程。
2、Bind過程,通過單詞我們可看出,這個過程是一個綁定的過程。為什么需要綁定過程?這個問題需要我們從軟件實現的角度去思考,如果讓我們來實現這個sql查詢引擎,我們應該怎么做?他們采用的策略是首先把sql查詢語句分割,分割不同的部分,再進行解析從而形成邏輯解析tree,然后需要知道我們需要取數據的數據表在哪里,需要哪些字段,執行什么邏輯,這些都保存在數據庫的數據字典中,因此bind過程,其實就是把Parse過程后形成的邏輯解析tree,與數據庫的數據字典綁定的過程。綁定后會形成一個執行tree,從而讓程序知道表在哪里,需要什么字段等等
3、完成了Bind過程后,數據庫查詢引擎會提供幾個查詢執行計劃,并且給出了查詢執行計劃的一些統計信息,既然提供了幾個執行計劃,那么有比較就有優劣,數據庫會根據這些執行計劃的統計信息選擇一個最優的執行計劃,因此這個過程是Optimize(優化)過程。
4、選擇了一個最優的執行計劃,那么就剩下最后一步執行Execute,最后執行的過程和我們解析的過程是不一樣的,當我們知道執行的順序,對我們以后寫sql以及優化都是有很大的幫助的.執行查詢后,他是先執行where部分,然后找到數據源之數據表,最后生成select的部分,我們的最終結果。執行的順序是:operation->DataSource->Result
雖然以上部分對SparkSQL沒有什么聯系,但是知道這些,對我們理解SparkSQL還是很有幫助的。
2、SparkSQL框架的架構
要想對這個框架有一個清晰的認識,首先我們要弄清楚,我們為什么需要sparkSQL呢?個人建議一般情況下在寫sql能夠直接解決的問題就不要使用sparkSQL,如果想刻意使用sparkSQL,也不一定能夠加快開發的進程。使用sparkSQL是為了解決一般用sql不能解決的復雜邏輯,使用編程語言的優勢來解決問題。我們使用sparkSQL一般的流程如下圖:
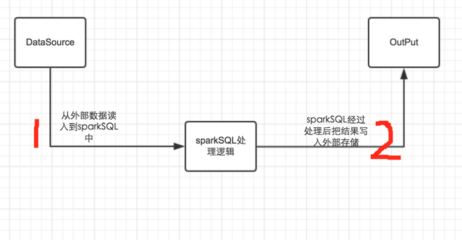
如上圖所示,一般情況下分為兩個部分:a、把數據讀入到sparkSQL中,sparkSQL進行數據處理或者算法實現,然后再把處理后的數據輸出到相應的輸出源中。
1、同樣我們也是從如果讓我們開發,我們應該怎么做,需要考慮什么問題來思考這個問題。
a、第一個問題是,數據源有幾個,我們可能從哪些數據源讀取數據?現在sparkSQL支持很多的數據源,比如:hive數據倉庫、json文件,.txt,以及orc文件,同時現在還支持jdbc從關系數據庫中取數據。功能很強大。
b、還一個需要思考的問題是數據類型怎么映射啊?我們知道當我們從一個數據庫表中讀入數據時,我們定義的表結構的字段的類型和編程語言比如scala中的數據類型映射關系是怎樣的一種映射關系?在sparkSQL中有一種來解決這個問題的方法,來實現數據表中的字段類型到編程語言數據類型的映射關系。這個以后詳細介紹,先了解有這個問題就行。
c、數據有了,那么在sparkSQL中我們應該怎么組織這些數據,需要什么樣的數據結構呢,同時我們對這些數據都可以進行什么樣的操作?sparkSQL采用的是DataFrame數據結構來組織讀入到sparkSQL中的數據,DataFrame數據結構其實和數據庫的表結構差不多,數據是按照行來進行存儲,同是還有一個schema,就相當于數據庫的表結構,記錄著每一行數據屬于哪個字段。
d、當數據處理完以后,我們需要把數據放入到什么地方,并切以什么樣的格式進行對應,這個a和b要解決的問題是相同的。
2、sparkSQL對于以上問題的實現邏輯也很明確,從上圖已經很清楚,主要分為兩個階段,每個階段都對應一個具體的類來實現。
a、 對于第一個階段,sparkSQL中存在兩個類來解決這些問題:HiveContext,SQLContext,同時hiveContext繼承了SQLContext的所有方法,同時又對其進行了擴展。因為我們知道, hive和mysql的查詢還是有一定的差別的。HiveContext只是用來處理從hive數據倉庫中讀入數據的操作,SQLContext可以處理sparkSQL能夠支持的剩下的所有的數據源。這兩個類處理的粒度是限制在對數據的讀寫上,同時對表級別的操作上,比如,讀入數據、緩存表、釋放緩存表表、注冊表、刪除注冊的表、返回表的結構等的操作。
b、sparkSQL處理讀入的數據,采用的是DataFrame中提供的方法。因為當我們把數據讀入到sparkSQL中,這個數據就是DataFrame類型的。同時數據都是按照Row進行存儲的。其中 DataFrame中提供了很多有用的方法。以后會細說。
c、在spark1.6版本以后,又增加了一個類似于DataFrame的數據結構Dataset,增加此數據結構的目的是DataFrame有軟肋,他只能處理按照Row進行存儲的數據,并且只能使用DataFrame中提供的方法,我們只能使用一部分RDD提供的操作。實現Dataset的目的就是讓我們能夠像操作RDD一樣來操作sparkSQL中的數據。
d、其中還有一些其他的類,但是現在在sparkSQL中最主要的就是上面的三個類,其他類以后碰到了會慢慢想清楚。
3、sparkSQL的hiveContext和SQLContext的運行原理
hiveContext和SQLContext與我第一部分講到的sql語句的模塊解析實現的原理其實是一樣的,采用了同樣的邏輯過程,并且網上有好多講這一塊的,就直接粘貼復制啦!!
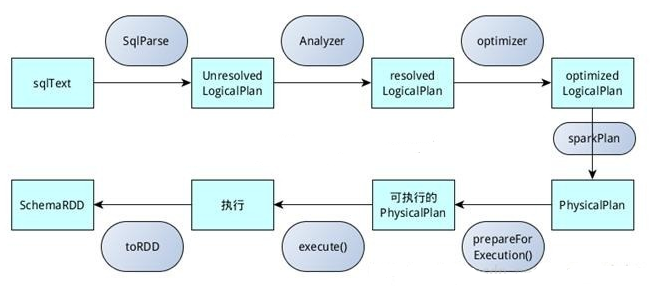
sqlContext總的一個過程如下圖所示:
1.SQL語句經過SqlParse解析成UnresolvedLogicalPlan;
2.使用analyzer結合數據數據字典(catalog)進行綁定,生成resolvedLogicalPlan;
3.使用optimizer對resolvedLogicalPlan進行優化,生成optimizedLogicalPlan;
4.使用SparkPlan將LogicalPlan轉換成PhysicalPlan;
5.使用prepareForExecution()將PhysicalPlan轉換成可執行物理計劃;
6.使用execute()執行可執行物理計劃;
7.生成SchemaRDD。
在整個運行過程中涉及到多個SparkSQL的組件,如SqlParse、analyzer、optimizer、SparkPlan等等
hiveContext總的一個過程如下圖所示:
1.SQL語句經過HiveQl.parseSql解析成Unresolved LogicalPlan,在這個解析過程中對hiveql語句使用getAst()獲取AST樹,然后再進行解析;
2.使用analyzer結合數據hive、源數據Metastore(新的catalog)進行綁定,生成resolved LogicalPlan;
3.使用optimizer對resolved LogicalPlan進行優化,生成optimized LogicalPlan,優化前使用了ExtractPythonUdfs(catalog.PreInsertionCasts(catalog.CreateTables(analyzed)))進行預處理;
4.使用hivePlanner將LogicalPlan轉換成PhysicalPlan;
5.使用prepareForExecution()將PhysicalPlan轉換成可執行物理計劃;
6.使用execute()執行可執行物理計劃;
7.執行后,使用map(_.copy)將結果導入SchemaRDD。

到此這篇關于Spark SQL的整體實現邏輯的文章就介紹到這了,更多相關Spark SQL實現邏輯內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Spark SQL常見4種數據源詳解
- Spark學習筆記之Spark SQL的具體使用
- pyspark.sql.DataFrame與pandas.DataFrame之間的相互轉換實例
- 淺談DataFrame和SparkSql取值誤區
- Spark SQL操作JSON字段的小技巧
- Spark SQL數據加載和保存實例講解
