其中 offset and fetch 最重要的新特性是 用來 分頁,既然要分析 分頁,就肯定要和之前的分頁方式來比較了,特別是 Row_Number() 了,在比較過程中,發(fā)現(xiàn)了蠻多,不過最重要的,通過比較本質(zhì),得出了優(yōu)劣,也和大家一起分享下。
準(zhǔn)備工作,建立測試表:Article_Detail,主要是用來存放一些文章信息,測試的時間,都是從網(wǎng)易上面轉(zhuǎn)載的新聞,同時,測試表數(shù)據(jù)字段類型是比較均勻的,為了更好的測試,表結(jié)構(gòu)如下圖:
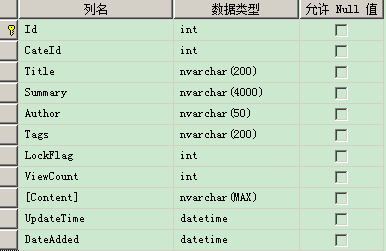
內(nèi)容:
數(shù)據(jù)量:129,991 條記錄
語法分析
1. NTILE() 的分頁方法
NTILE() 方法可以用來分頁,但是應(yīng)用場景十分的狹窄,并且性能差勁,和 Row_Number() 與 offset fetch 分頁比起來沒有任何優(yōu)勢,也只有在只讀表上面分頁的話,還是比較合適的;雖然不好用,但是還能來分頁的,所以只簡單的介紹下。
語法:
NTILE (integer_expression) OVER ( [ partition_by_clause> ] order_by_clause > )
將有序分區(qū)中的行分發(fā)到指定數(shù)目的組中。 各個組有編號,編號從一開始。 對于每一個行,NTILE 將返回此行所屬的組的編號。
測試中用到的 Sql 語句 :
復(fù)制代碼 代碼如下:
set statistics time on
set statistics io on
set statistics profile on;
with #pager as
(
select ID,Title,NTILE(8666) OVER(Order By ID) as pageid from Article_Detail
)
select ID,Title from #pager where pageid=50
set statistics profile on;
其中上述數(shù)字中的 8666 是根據(jù) RowCount / Pagesize 計算出來的,不過多介紹,可以自行參考 MSDN的
2. ROW_NUMBER() 的分頁方法
在 Sql Server 2000 之后的版本中,ROW_NUMBER() 這種分頁方式一直都是很不錯的,比起之前的游標(biāo)分頁,性能好了很多,因?yàn)?ROW_NUMBER() 并不會引起全表掃表,但是,語法比較復(fù)雜,并且,隨著頁碼的增加,性能也越來越差。
語法 :
ROW_NUMBER ( ) OVER ( [ PARTITION BY value_expression , ... [ n ] ] order_by_clause )
測試中用到的 Sql 語句:
復(fù)制代碼 代碼如下:
dbcc freeproccache
dbcc dropcleanbuffers
set statistics time on
set statistics io on
set statistics profile on;
with #pager as
(
select ID,Title,ROW_NUMBER() OVER(Order By ID) as rowid from Article_Detail
)
select ID,Title from #pager where rowid between (15 * (50-1)+1) and 15 * 50
set statistics profile off;
3. Offset and Fetch 的分頁方法
語法:
OFFSET { integer_constant | offset_row_count_expression } { ROW | ROWS }
FETCH { FIRST | NEXT } { integer_constant | fetch_row_count_expression } { ROW | ROWS } ONLY
從語法可以看出來 兩個方法 后面不但能接 intege 類型的參數(shù),還能接 表達(dá)式的,比如 1*2 +3 之類的,同時, Row 或者 Rows 是不區(qū)分大小寫和單復(fù)數(shù)的哦
在看測試用的 Sql 語句,真的是簡潔的不能再簡潔了,看兩遍都能記住的語法,分頁可以如此的簡潔:
復(fù)制代碼 代碼如下:
dbcc freeproccache
dbcc dropcleanbuffers
set statistics time on
set statistics io on
set statistics profile on;
select ID,Title from Article_Detail order by id OFFSET (15 * (50-1)) ROW FETCH NEXT 15 rows only
set statistics profile off;
一句就搞定!
性能比較
1. NTILE() 的執(zhí)行計劃

從執(zhí)行計劃中,就可以看出來,進(jìn)行了一次全表掃表,兩次 Nested Loops ,還有無數(shù)其他運(yùn)算,就一次全表掃表,就知道性能之差了
2. ROW_NUMBER() 的執(zhí)行計劃
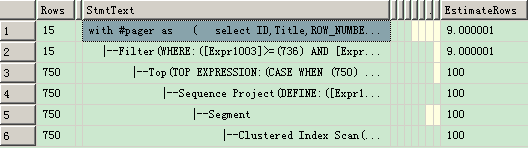
從執(zhí)行計劃中可以看出來, 聚集索引掃描占用了100% 的資源,但是通過 EstimateRows = 100 和 Rows = 750 可以看出來,并沒有進(jìn)行全表掃描,并且IO 操作很小,所以性能還是很不錯的
3. Offset and Fetch 的 執(zhí)行計劃

執(zhí)行計劃只有3行,并且占用資源 100% 的IO 操作 ,EstimateRows = 100 和 Rows = 750 是和 ROW_NUMBER() 完全一樣的,但是其他的一些操作卻少了很多,也就是說,并沒有全表掃描,并降低了CPU 的消耗。
綜合比較:
在 Sql Server 2012 里面,分頁方法中,Offset and Fetch 同 ROW_NUMBER() 比較起來,無論是性能還是語法,都是有優(yōu)勢的。
但是性能方面,優(yōu)勢并不是太大,兩者 的 IO 消耗完全相同,只是 在 CPU 方面,Offset and Fetch 方面要好一些,但是不明顯。如果對于一個 每秒都要處理成千上萬條的分頁Sql語句的DB 來說,Offset and Fetch 在CPU 方面的優(yōu)勢會比較明顯的,否則,性能的提升并不明顯。
語法方面 Offset and Fetch 則是十分的簡潔,一句搞定,比起 Row_Number() 好了太多 ~
同是 Offset and Fetch 并不僅僅可以用來分頁哦,具體其他使用,大家可以自行參考 MSDN
您可能感興趣的文章:- 高效的SQLSERVER分頁查詢(推薦)
- sqlserver2005使用row_number() over分頁的實(shí)現(xiàn)方法
- SQL SERVER 2008 中三種分頁方法與比較
- oracle,mysql,SqlServer三種數(shù)據(jù)庫的分頁查詢的實(shí)例
- 真正高效的SQLSERVER分頁查詢(多種方案)
- SQL Server 分頁查詢存儲過程代碼
- 五種SQL Server分頁存儲過程的方法及性能比較
- sqlserver分頁的兩種寫法分別介紹
- sqlserver 通用分頁存儲過程
- sqlserver 存儲過程分頁(按多條件排序)
- sql server中千萬數(shù)量級分頁存儲過程代碼
- sqlserver 高性能分頁實(shí)現(xiàn)分析
- SQL Server 分頁查詢通用存儲過程(只做分頁查詢用)
- sql server實(shí)現(xiàn)分頁的方法實(shí)例分析