這一篇筆記我們簡述一下
- MySQL的B+Tree索引到底是咋回事���?
- 聚簇索引索引到底是如何長高的���。
一點一點看�����,其實蠻好理解的���。
如果你看過了我之前的筆記�,你肯定知道了MySQL進行CRUD是在內(nèi)存中進行的�����,也就是在Buffer Pool中�����。然后你也知道了當(dāng)內(nèi)存中沒有MySQL需要的數(shù)據(jù)時,MySQL會從Disk中通過IO操作將數(shù)據(jù)讀入內(nèi)存中�����。讀取的單位呢就是:數(shù)據(jù)頁
一般數(shù)據(jù)頁長下面這樣
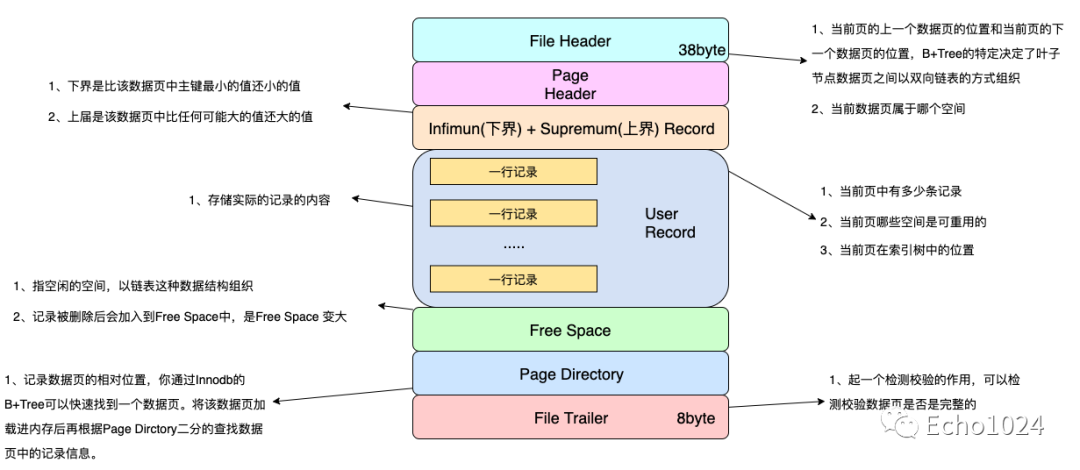
沒錯�����,數(shù)據(jù)頁中存儲著真實的數(shù)據(jù)���,而且數(shù)據(jù)頁在內(nèi)存中是以雙向聯(lián)表的方式組織起來的!如下圖
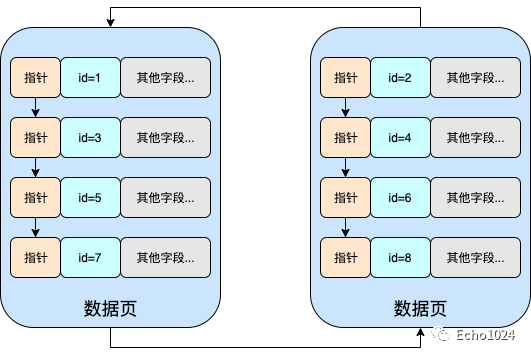
而在B+Tree的設(shè)定中���,它要求主鍵索引時遞增的,也就是說如果主鍵索引時遞增的話,那么就要求右側(cè)的數(shù)據(jù)頁中的所有數(shù)據(jù)均比左側(cè)數(shù)據(jù)頁中的數(shù)據(jù)大�����。但是很明顯上圖并不符合,因此需要通過頁分裂來調(diào)整成下面這樣�����。
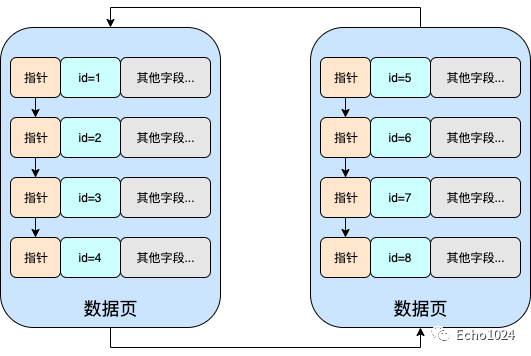
好�����,現(xiàn)在你回想一下�,之前你肯定有聽說過:MySQL的B+Tree聚簇索引�,只有葉子節(jié)點才存儲真實的數(shù)據(jù),而非葉子節(jié)點中存儲的是索引數(shù)據(jù)�,而且葉子節(jié)點之間是通過雙向鏈表連接起來
沒錯���,那所有的B+Tree的葉子節(jié)點就是上圖中的數(shù)據(jù)頁�,并且它們確實是通過雙向鏈表關(guān)聯(lián)起來的���!
我們接著往下看�,如果只看上圖由數(shù)據(jù)頁連接起來的雙向鏈表的話,這時如果我們檢索id=7的數(shù)據(jù)行�����,那會發(fā)生什么�?
很明顯我們要從頭開始掃描!
那你可能會問:方才不是說B+Tree要求主鍵是遞增的嘛���?并且有頁分裂機制保證右邊的數(shù)據(jù)頁中的所有數(shù)據(jù)均比它左邊的數(shù)據(jù)頁的索引值大。那進行二分查找不行嘛�?
答:是的,確實可以在單個數(shù)據(jù)頁中進行二分查找,但是數(shù)據(jù)頁之間的組織關(guān)系是鏈表呀,所以從頭開始遍歷是避免不了的。
那MySQL怎么辦的呢�����?
如下圖:MySQL針對諸多的數(shù)據(jù)頁抽象出了一個索引目錄
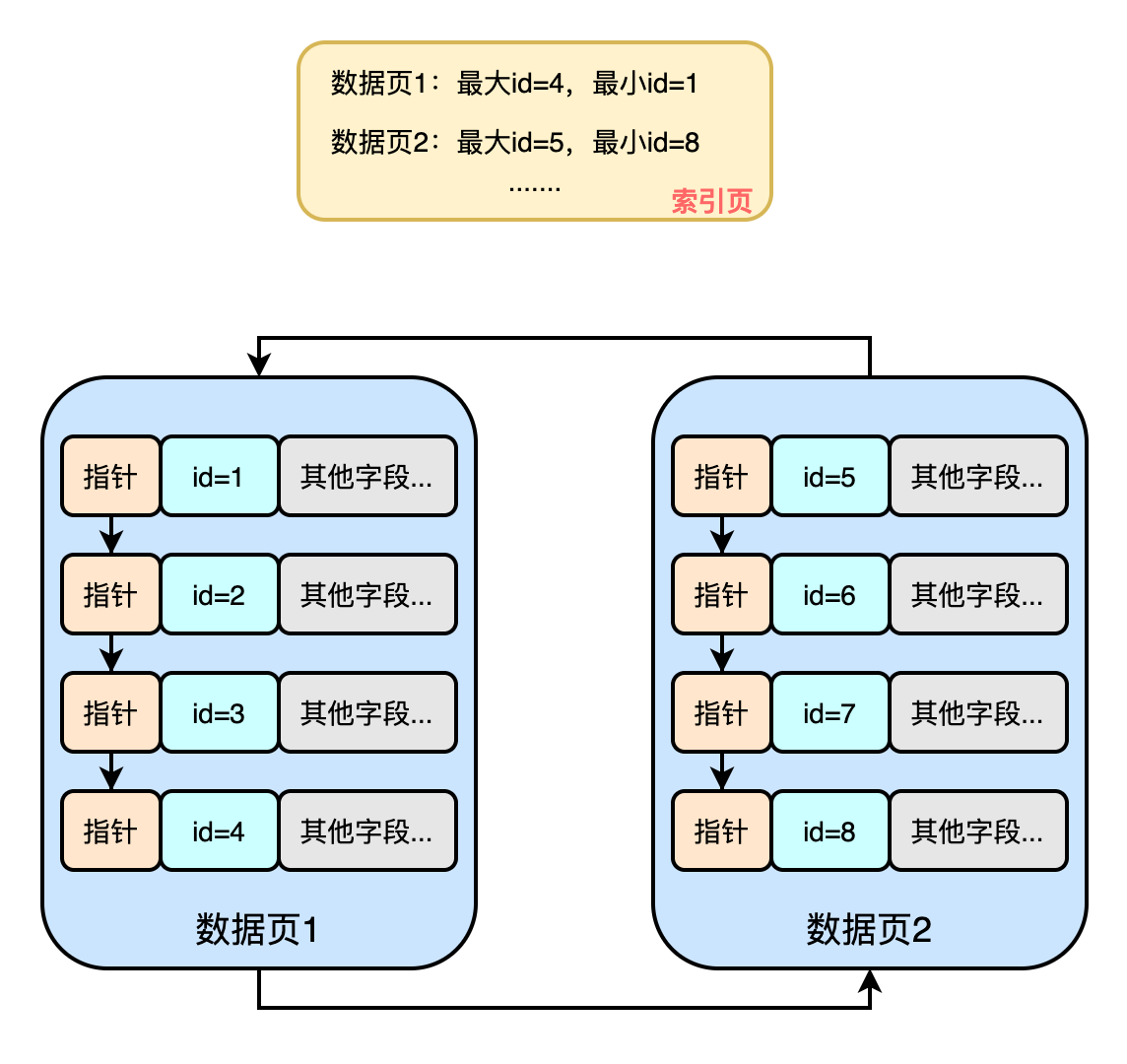
那有了這個索引目錄我們再在諸多的數(shù)據(jù)頁中檢索時看起來就容易多了�!直接就擁有了二分檢索的能力!
而且這個所以目錄其實也是存在于數(shù)據(jù)頁中的�����,不同于葉子節(jié)點的是���,它里面知識存儲了索引信息�,而葉子節(jié)點中存儲的是真實數(shù)據(jù)?
而索引頁的誕生也就意味著B+Tree的雛形已經(jīng)誕生了���!
隨著用戶不斷的select,buffer pool中的數(shù)據(jù)頁的越來越多�,那么索引頁中的數(shù)據(jù)也會水漲船高�。當(dāng)現(xiàn)有的索引體量超過16KB(一個數(shù)據(jù)頁的容量)時就不得不搞一個新的索引頁來存儲新的索引信息�。這時這顆B+Tree就會慢慢變得越來越胖。
那你也知道B+Tree是B樹的變種,而B樹其實可以是2-3樹���、2-3-4數(shù)....等等M階樹的泛稱,當(dāng)每個節(jié)點中能存儲的元素達到上限后,樹就會長高(上一篇文章有講過)�。
就像下圖這樣:

以上就是一看就懂的MySQL的聚簇索引及聚簇索引是如何長高的的詳細內(nèi)容�,更多關(guān)于MySQL聚簇索引的資料請關(guān)注腳本之家其它相關(guān)文章�!
您可能感興趣的文章:- MySQL學(xué)習(xí)教程之聚簇索引
- 詳解MySQL 聚簇索引與非聚簇索引
- mysql聚簇索引的頁分裂原理實例分析
