搜索引擎工作過程非常復雜,今天和大家分享一下我所了解的百度蜘蛛是怎么實現網頁收錄的。
搜索引擎工作大致可以分為四個過程。
1、蜘蛛爬行抓取。
2、信息過濾。
3、建立網頁關鍵詞索引。
4、用戶搜索輸出結果。
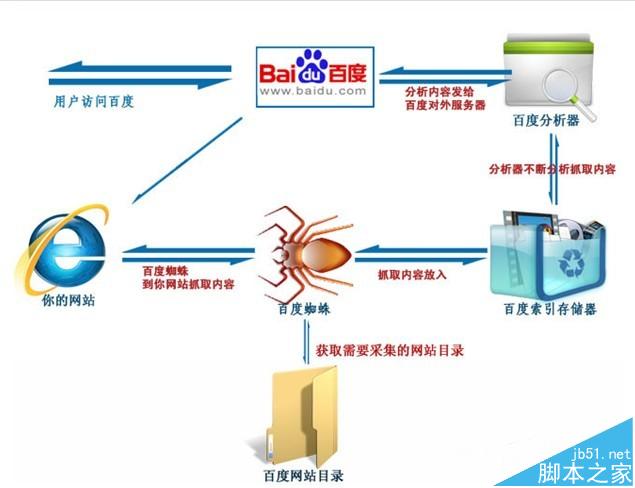
蜘蛛爬行抓取
當百度蜘蛛來到一個頁面時,它會跟蹤頁面上的鏈接,從這個頁面爬行到下一個頁面,就好像一個遞歸過程,這樣常年累月,不止疲倦的工作。比如蜘蛛來到了我的博客首頁http://blog.sina.com.cn/netSEOer,它會先讀取根目錄下的robots.txt文件,如果沒有禁止搜索引擎抓取,那么蜘蛛就開始針對網頁上的鏈接,進行逐一跟蹤爬行。比如我的置頂文章“SEO概述|什么是SEO SEO到底是干嘛的”,引擎就會多進程式的來到這篇文章所在的網頁抓取信息,如此循壞,沒有終結。
信息過濾
為了避免重復爬行和抓取網址,搜索引擎會有一個記錄已爬行和未被爬行的地址庫,如果你有一個新網站時,你可以去百度官網提交網站的網址,引擎就會記錄它,并把它歸類到未爬行的網址,然后蜘蛛就會根據這個表格,從數據庫中提取URL,訪問并抓取頁面。
蜘蛛并不會收錄所有的頁面,它要經過嚴格檢測。當蜘蛛在爬行和抓取一個網頁的內容時,會進行一定程度的復制內容檢測,如果網頁所在的網站權重低,而且大部分文章都是抄襲來的話,蜘蛛就很可能不喜歡你的網站了,不在繼續爬行,也就不收錄你的網站。
建立網頁關鍵詞索引
當蜘蛛抓取了一個頁面之后,首先會對頁面文字內容進行分析。通過分詞技術,將網頁的內容簡化到關鍵詞,并把關鍵詞和對應的網址制成表格建立索引。
索引又有正向索引和反向索引,正向索引是把網頁內容對應的關鍵詞,反向是關鍵詞對應的網頁信息。
輸出結果
當用戶搜索了某個關鍵詞之后,就會通過前面建立的索引表進行關鍵詞匹配,通過反向索引表找到關鍵詞對應的頁面,通過引擎對網頁綜合評分計算以后,根據網頁的評分來決定網頁的先后順序排名。
相關推薦:
網站優化 百度蜘蛛到底喜歡什么?
怎么查詢ip是否為百度蜘蛛ip? tracert指令的使用方法
