目錄
- 導出公眾號所有文章
- 開發者ID與開發者密碼
- 保存數據到CSV文件
導出公眾號所有文章
隨著互聯網的不斷發展,網絡上興起了很多的自媒體平臺。不用我說,相信大家也能知道當下非常流行的平臺都有哪些。
可以說凡是比較知名的自媒體,都有自己的公眾號。但是平臺的創新與出現可謂層出不窮,如果需要入住平臺,肯定需要獲取原平臺的歷史資源。
比如說微信公眾號,我們就需要獲取微信公眾號的文章,將其導出后,入住其他的平臺,那么如何獲取自己公眾號下的所有文章呢?
開發者ID與開發者密碼
其實,公眾號給我們開發中提供了非常友好的接口,并不需要我們一個一個去爬,就可以獲取文章的所有鏈接。

如上圖所示,我們需要進入公眾號主頁,然后通過設置與開發-基本配置,找到開發者ID與開發者密碼。
因為微信給我們提供了接口專門用于我們獲取公眾號的文章,具體的接口網址,如下面代碼所示:
https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credentialappid=APPIDsecret=APPSECRET
這里的APPID就是開發中ID,APPSECRET就是開發者密碼,如下圖所示進行獲取。
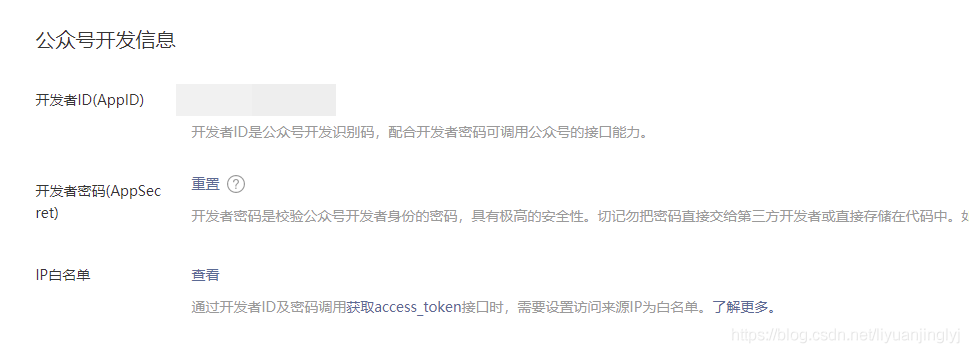
不過,這里有一個IP白名需要注意,為了公眾號文章的安全,必須設置IP地址才能獲取。如果后面的代碼并沒有在IP下運行,那么肯定會報錯。
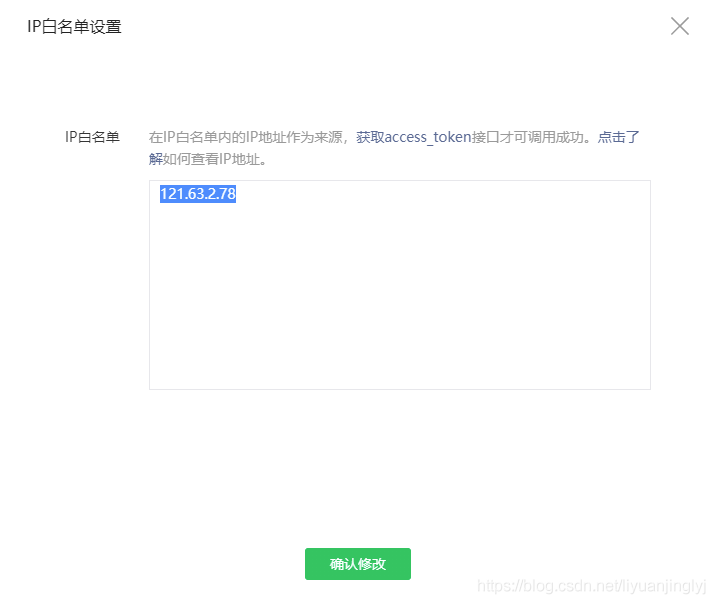
如上圖所示,IP白名單是直接設置你的IP地址,設置完成之后點擊修改,彈出二維碼后用微信掃描即可。
https://api.weixin.qq.com/cgi-bin/material/batchget_material?access_token=
這樣還不行,因為該網址接口只是獲取access_token,也就是訪問公眾號的令牌,而獲取公眾號文章的鏈接是上面這個。
獲取Json格式的公眾號文章信息
既然已經基本了解了原理,下面我們來通過實戰獲取所有的公眾號標題,鏈接,描述以及文章的展示圖。示例如下:
import requests
import json
import csv
def getGZHJson(appid, secret):
path = " https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential"
url = path + "appid=" + appid + "secret=" + secret
result = requests.get(url)
token = json.loads(result.text)
access_token = token['access_token']
data = {
"type": "news",
"offset": 0,
"count": 1,
}
headers = {
'content-type': "application/json",
'Accept-Language': 'zh-CN,zh;q=0.9'
}
url = 'https://api.weixin.qq.com/cgi-bin/material/batchget_material?access_token=' + access_token
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
result = json.loads(result.text)
count = int(result['total_count'])
gzh_dict = {"news_item": []}
for i in range(0, count):
data['offset'] = i
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
result = json.loads(result.text)
for item in result['item'][0]['content']['news_item']:
temp_dict = {}
temp_dict['title'] = item["title"]
temp_dict['digest'] = item["digest"]
temp_dict['url'] = item["url"]
temp_dict['thumb_url'] = item["thumb_url"]
print(temp_dict)
gzh_dict['news_item'].append(temp_dict)
return json.dumps(gzh_dict)
getGZHJson('開發者ID', '開發者密碼')
這里,我們先來看一下result的原始文本數據,具體如下所示:

原始的JSON數據中,有一個非常重要的數據也就是total_count,也就是公眾號成立以來,推送的次數。
但是需要注意,公眾號可以單次推送一篇,或者單次推送2,3,4篇,并不一直都是一模一樣。
而獲取哪次推送的數據,你可以通過offset逆向溯源,至于每次是多少篇,則需要通過返回的Json數據news_item有多少個決定。如下圖所示:

所以,我們還有在里面加上一次遍歷,第1層遍歷的是微信公眾號推送的哪天數據,第2層遍歷,遍歷的是當天發送的篇數。運行之后,效果如下:
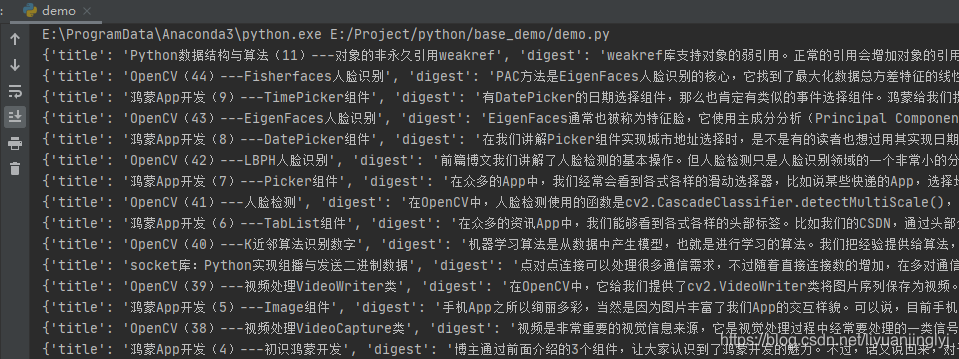
| 參數 |
含義 |
| title |
文章標題 |
| digest |
文章描述 |
| url |
文章鏈接 |
| thumb_url |
文章展示圖 |
保存數據到CSV文件
當然,我們獲取數據并不是為了在控制臺去打印,而是為了導出數據。所以,我們將上面的數據打包到CSV文件中保存起來。
示例如下:
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
print(result.encoding)
result = json.loads(result.text)
count = int(result['total_count'])
#替換下面的代碼
ulist = ["_id", "title", 'digest', 'url', 'thumb_url']
# 保存數據到csv文件
new_item_csv = 'week'
with open('{}.csv'.format(new_item_csv), 'w', encoding='utf-8-sig', newline='') as f:
writer = csv.writer(f, dialect='excel')
writer.writerow(ulist)
for i in range(0, count):
data['offset'] = i
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
result = json.loads(result.text)
for item in result['item'][0]['content']['news_item']:
writer.writerow([count_id, item["title"], item["digest"], item["url"], item["thumb_url"]])
count_id += 1
這里,只需要改count = int(result[‘total_count'])代碼下面的所有數據即可。上面的代碼保持不變。
需要額外注意的是,之所以設置result.encoding = result.apparent_encoding,是因為返回數據的編碼事先我們并不知道,這樣做能保證任何編碼都能有效的解析。
運行之后,如下圖所示,所有的公眾號文章的基本詳情就全部獲取到了。
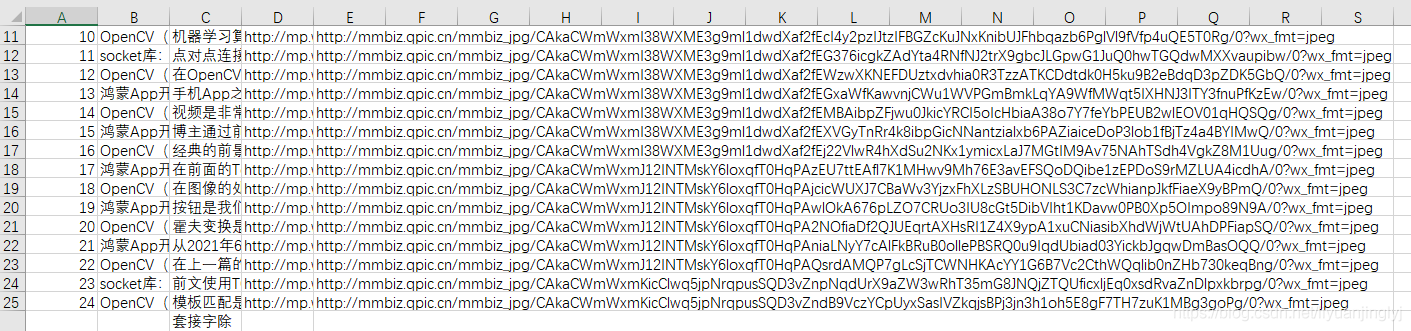
到此這篇關于使用Python獲取公眾號下所有的文章的文章就介紹到這了,更多相關Python獲取公眾號文章內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Python 微信公眾號文章爬取的示例代碼
- python如何導出微信公眾號文章方法詳解
- Python selenium爬取微信公眾號文章代碼詳解
- Python如何爬取微信公眾號文章和評論(基于 Fiddler 抓包分析)
- python抓取搜狗微信公眾號文章
- python爬取微信公眾號文章的方法
- python爬取指定微信公眾號文章
- python采集微信公眾號文章
- python爬取微信公眾號文章
