目錄
- 一、什么是XML?
- 二、Python XML解析模塊
- 2.1、xml.etree.ElementTree模塊
- 2.2、xml.dom.minidom模塊
一、什么是XML?
XML代表可擴展標記語言。它在外觀上類似于HTML,但XML用于數據表示,而HTML用于定義正在使用的數據。XML專門設計用于在客戶端和服務器之間來回發送和接收數據。看看下面的例子:
例子:
? xml version ="1.0" encoding ="UTF-8" ?>
metadata>
food>
item name ="breakfast" > Idly /item>
price> $2.5 /price>
description>
兩個 idly's with chutney
/description>
calories> 553 /calories>
/food>
food>
item name ="breakfast" > Paper Dosa /item>
price> $2.7 /price>
calories> 700 /calories>
/food>
food>
item name ="breakfast" > Upma /item>
price> $3.65 /price>
description>
Rava upma with bajji
/description>
calories> 600 /calories>
/food>
food>
item name ="breakfast" > Bisi Bele Bath /item>
price> $4.50 /price>
description>
Bisi Bele Bath with sev
/description>
calories> 400 /calories>
/food>
food>
item name ="breakfast" > Kesari Bath /item>
price> $1.95 /price>
description>
藏紅花甜拉瓦
/description>
calories> 950 /calories>
/食物>
/元數據>
上面的示例顯示了我命名為“Sample.xml”的文件的內容,我將在此Python XML解析器教程中為所有即將推出的示例使用相同的內容。
二、Python XML解析模塊
Python允許使用兩個模塊解析這些XML文檔,即xml.etree.ElementTree模塊和Minidom(最小DOM實現)。解析意味著從文件中讀取信息并通過識別該特定XML文件的部分將其拆分為多個部分。讓我們進一步了解如何使用這些模塊來解析XML數據。
2.1、xml.etree.ElementTree模塊
該模塊幫助我們在樹結構中格式化XML數據,這是分層數據的最自然表示。元素類型允許在內存中存儲分層數據結構,并具有以下屬性:
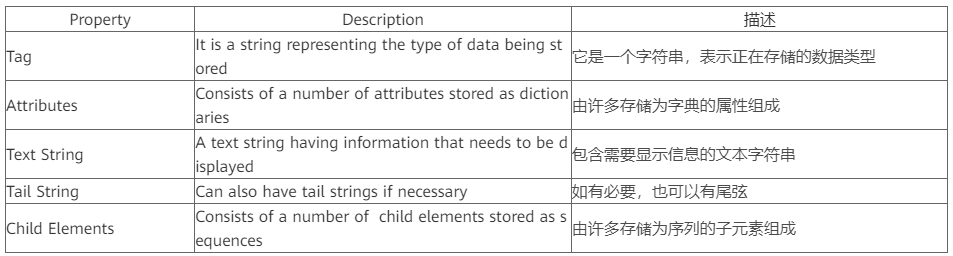
ElementTree是一個包裝元素結構并允許與XML相互轉換的類。現在讓我們嘗試使用python模塊解析上述XML文件。
有兩種使用“ElementTree”模塊解析文件的方法。第一個是使用parse()函數,第二個是fromstring()函數。parse()函數解析作為文件提供的XML文檔,而fromstring解析作為字符串提供的XML,即在三引號內。
使用parse()函數:
如前所述,該函數采用文件格式的XML來解析它。看下面的例子:
例子:
import xml.etree.ElementTree as ET
mytree = ET.parse('sample.xml')
myroot = mytree.getroot()
如您所見,您需要做的第一件事是導入xml.etree.ElementTree模塊。然后,parse()方法解析“Sample.xml”文件。getroot()方法返回“Sample.xml”的根元素。
執行上述代碼時,您不會看到返回的輸出,但不會出現表明代碼已成功執行的錯誤。要檢查根元素,您可以簡單地使用print語句,如下所示:
例子:
import xml.etree.ElementTree as ET
mytree = ET.parse('sample.xml')
myroot = mytree.getroot()
print(myroot)
輸出:
元素'元數據'在0x033589F0>
上面的輸出表明我們的XML文檔中的根元素是“元數據”。
使用fromstring()函數:
您還可以使用fromstring()函數來解析您的字符串數據。如果要執行此操作,請將XML作為字符串傳遞給三引號,如下所示:
import xml.etree.ElementTree as ET
data='''?xml version="1.0" encoding="UTF-8"?>
metadata>
food>
item name="breakfast">Idly/item>
price>$2.5/price>
description>
Two idly's with chutney
/description>
calories>553/calories>
/food>
/metadata>
'''
myroot = ET.fromstring(data)
#print(myroot)
print(myroot.tag)
上面的代碼將返回與前一個相同的輸出。請注意,用作字符串的XML文檔只是“Sample.xml”的一部分,我使用它來提高可見性。您也可以使用完整的XML文檔。
您還可以使用“標簽”對象檢索根標簽,如下所示:
例子:
輸出:
元數據
您還可以通過指定要在輸出中看到的字符串部分來對標簽字符串輸出進行切片。
例子:
輸出:
元
如前所述,標簽也可以具有字典屬性。要檢查根標記是否具有任何屬性,您可以使用“attrib”對象,如下所示:
例子:
輸出:
{}
如您所見,輸出是一個空字典,因為我們的根標簽沒有屬性。
尋找感興趣的元素:
根也由子標簽組成。要檢索根標記的子項,您可以使用以下命令:
例子:
輸出:
食物
現在,如果要檢索根的所有第一個子標簽,可以使用for循環迭代它,如下所示:
例子:
for x in myroot[0]:
print(x.tag, x.attrib)
輸出:
item {'name': 'breakfast'}
價格{}
描述{}
卡路里{}
返回的所有項目都是食物的子屬性和標簽。
要使用ElementTree將文本從XML中分離出來,您可以使用text屬性。例如,如果我想檢索有關第一個食品的所有信息,我應該使用以下代碼:
例子:
for x in myroot[0]:
print(x.text)
輸出:
懶懶地
$ 2.5
兩悠閑地與酸辣醬的
553
可以看到,第一項的文本信息已經作為輸出返回了。現在,如果您想顯示具有特定價格的所有商品,您可以使用get()方法。此方法訪問元素的屬性。
例子:
for x in myroot.findall('food'):
item =x.find('item').text
price = x.find('price').text
print(item, price)
輸出:
Idly$2.5
Paper Dosa$2.7
Upma$3.65
Bisi Bele Bath$4.50
Kesari Bath$1.95
上面的輸出顯示了所有必需的項目以及每個項目的價格。使用ElementTree,您還可以修改XML文件。
修改XML文件:
可以操作XML文件中的元素。為此,您可以使用set()函數。讓我們首先看看如何向XML添加一些東西。
添加到XML:
以下示例顯示了如何在項目描述中添加內容。
例子:
for description in myroot.iter('description'):
new_desc = str(description.text)+'wil be served'
description.text = str(new_desc)
description.set('updated', 'yes')
mytree.write('new.xml')
write()函數幫助創建一個新的xml文件并將更新的輸出寫入相同的文件。但是,您也可以使用相同的功能修改原始文件。執行完上述代碼后,您將能夠看到已創建具有更新結果的新文件。

上圖顯示了對我們食品的修改描述。要添加新的子標簽,您可以使用SubElement()方法。例如,如果您想在第一項Idly中添加一個新的專業標簽,您可以執行以下操作:
例子:
ET.SubElement(myroot[0], 'speciality')
for x in myroot.iter('speciality'):
new_desc = 'South Indian Special'
x.text = str(new_desc)
mytree.write('output5.xml')
輸出:
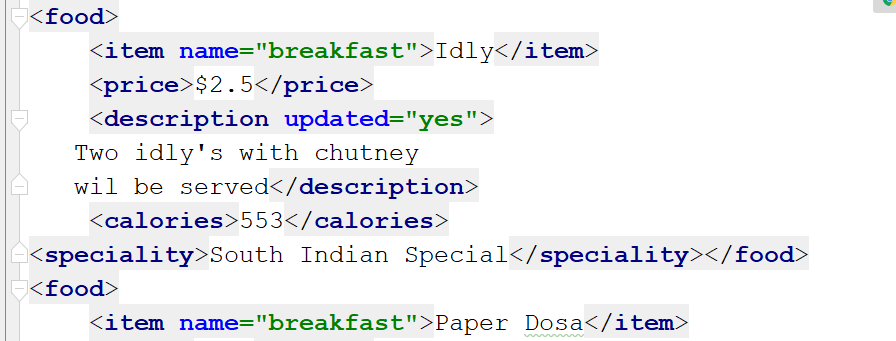
如您所見,在第一個食品標簽下添加了一個新標簽。通過在[]括號內指定下標,您可以在任何地方添加標簽。現在讓我們看一下如何使用此模塊刪除項目。
從XML中刪除:
要使用ElementTree刪除屬性或子元素,您可以使用pop()方法。此方法將刪除用戶不需要的所需屬性或元素。
例子:
myroot[0][0].attrib.pop('name', None)
# create a new XML file with the results
mytree.write('output5.xml')
輸出:

上圖顯示name屬性已從item標記中刪除。要刪除完整的標簽,您可以使用相同的pop()方法,如下所示:
例子:
myroot[0].remove(myroot[0][0])
mytree.write('output6.xml')
輸出:
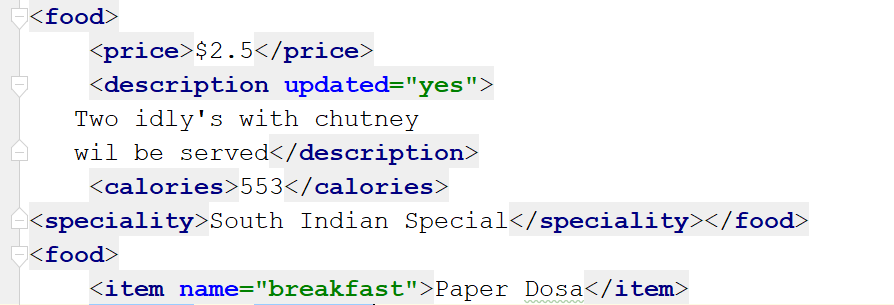
輸出顯示食品標簽的第一個子元素已被刪除。如果要刪除所有標簽,可以使用clear()函數,如下所示:
例子:
myroot[0].clear()
mytree.write('output7.xml')
輸出:
執行上述代碼時,food標簽的第一個子標簽將被完全刪除,包括所有子標簽。到這里為止,我們一直在使用這個Python XML解析器教程中的xml.etree.ElementTree模塊。現在讓我們看看如何使用Minidom解析XML。
2.2、xml.dom.minidom模塊
這個模塊基本上是由精通DOM(文檔對象模塊)的人使用的。DOM應用程序通常首先將XML解析為DOM。在xml.dom.minidom中,這可以通過以下方式實現:
使用parse()函數:
第一種方法是通過提供要解析的XML文件作為參數來使用parse()函數。例如:
例子:
from xml.dom import minidom
p1 = minidom.parse("sample.xml");
執行此操作后,您將能夠拆分XML文件并獲取所需的數據。您還可以使用此函數解析打開的文件。
例子:
dat=open('sample.xml')
p2=minidom.parse(dat)
在這種情況下,存儲打開文件的變量作為參數提供給解析函數。
使用parseString()方法:
當您想要提供要作為字符串解析的XML時,將使用此方法。
例子:
p3 = minidom.parseString('myxml>Usingempty/> parseString/myxml>')
您可以使用上述任何一種方法來解析XML。現在讓我們嘗試使用此模塊獲取數據。
尋找感興趣的元素:
在我的文件被解析后,如果我嘗試打印它,返回的輸出會顯示一條消息,表明存儲解析數據的變量是DOM對象。
例子:
dat=minidom.parse('sample.xml')
print(dat)
輸出:
xml.dom.minidom.Document對象在0x03B5A308>
使用GetElementByTagName訪問元素:
例子:
tagname= dat.getElementsByTagName('item')[0]
print(tagname)
如果我嘗試使用GetElementByTagName方法獲取第一個元素,我將看到以下輸出:
輸出:
DOM元素:0xc6bd00處的項目>
請注意,只返回了一個輸出,因為為了方便我使用了[0]下標,這將在進一步的示例中刪除。
要訪問屬性的值,我必須按如下方式使用value屬性:
例子:
dat = minidom.parse('sample.xml')
tagname= dat.getElementsByTagName('item')
print(tagname[0].attributes['name'].value)
輸出:
早餐
要檢索這些標簽中存在的數據,您可以使用data屬性,如下所示:
例子:
print(tagname[1].firstChild.data)
輸出:
紙Dosa
您還可以使用value屬性拆分和檢索屬性的值。
例子:
print(items[1].attributes['name'].value)
輸出:
早餐
要打印出我們菜單中可用的所有項目,您可以遍歷這些項目并返回所有項目。
例子:
for x in items:
print(x.firstChild.data)
輸出:
袖手旁觀
紙DOSA
UPMA
碧斯百麗沐浴
Kesari浴
要計算菜單上的項目數,您可以使用len()函數,如下所示:
例子:
輸出指定我們的菜單包含5個項目。
這使我們結束了本Python XML解析器教程。我希望你已經清楚地了解了一切。
以上就是分析如何在Python中解析和修改XML的詳細內容,更多關于Python解析和修改XML的資料請關注腳本之家其它相關文章!
您可能感興趣的文章:- Python lxml庫的簡單介紹及基本使用講解
- Python xmltodict模塊安裝及代碼實例
- python讀取xml文件方法解析
- Python將字典轉換為XML的方法
- python讀取配置文件方式(ini、yaml、xml)
- python 截取XML中bndbox的坐標中的圖像,另存為jpg的實例
- python代碼xml轉txt實例
- python:批量統計xml中各類目標的數量案例
- 利用 Python ElementTree 生成 xml的實例
- Python3 xml.etree.ElementTree支持的XPath語法詳解
