一、tensorboard的簡要介紹
TensorBoard是一個獨立的包(不是pytorch中的),這個包的作用就是可視化您模型中的各種參數(shù)和結(jié)果。
下面是安裝:
安裝 TensorBoard 后,這些實用程序使您可以將 PyTorch 模型和指標記錄到目錄中,以便在 TensorBoard UI 中進行可視化。 PyTorch 模型和張量以及 Caffe2 網(wǎng)絡(luò)和 Blob 均支持標量,圖像,直方圖,圖形和嵌入可視化。
SummaryWriter 類是您用來記錄數(shù)據(jù)以供 TensorBoard 使用和可視化的主要入口。
看一個例子,在這個例子中,您重點關(guān)注代碼中的注釋部分:
import torch
import torchvision
from torchvision import datasets, transforms
# 可視化工具, SummaryWriter的作用就是,將數(shù)據(jù)以特定的格式存儲到上面得到的那個日志文件夾中
from torch.utils.tensorboard import SummaryWriter
# 第一步:實例化對象。注:不寫路徑,則默認寫入到 ./runs/ 目錄
writer = SummaryWriter()
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = datasets.MNIST('mnist_train', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
model = torchvision.models.resnet50(False)
# 讓 ResNet 模型采用灰度而不是 RGB
model.conv1 = torch.nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)
images, labels = next(iter(trainloader))
grid = torchvision.utils.make_grid(images)
# 第二步:調(diào)用對象的方法,給文件夾存數(shù)據(jù)
writer.add_image('images', grid, 0)
writer.add_graph(model, images)
writer.close()
點擊運行之后,我們就可以在文件夾下看到我們保存的數(shù)據(jù)了,然后我們就可以使用 TensorBoard 對其進行可視化,該 TensorBoard 應(yīng)該可通過以下方式運行(在命令行):
tensorboard --logdir=runs
運行結(jié)果:

把上述的地址,粘貼到瀏覽器就可以看到可視化的結(jié)果了,如下所示:
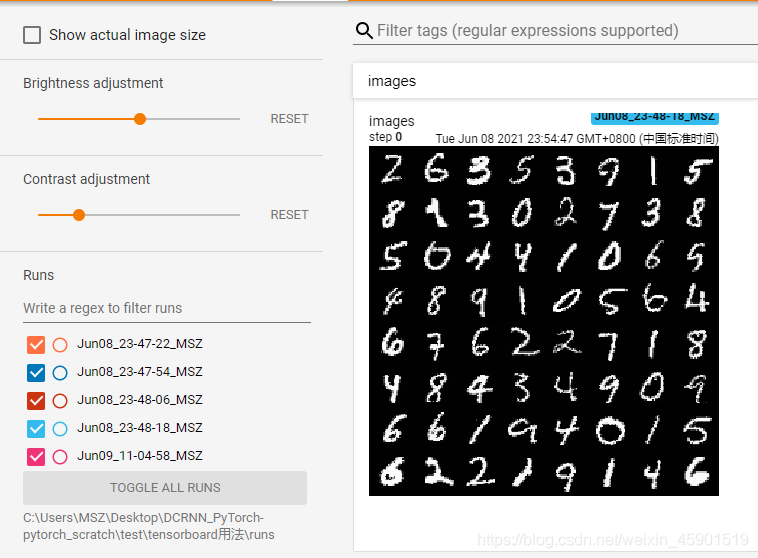
接著看:
一個實驗可以記錄很多信息。 為了避免 UI 混亂和更好地將結(jié)果聚類,我們可以通過對圖進行分層命名來對圖進行分組。 例如,“損失/訓(xùn)練”和“損失/測試”將被分組在一起,而“準確性/訓(xùn)練”和“準確性/測試”將在 TensorBoard 界面中分別分組。
我們再看一個更簡單的例子來理解上面的話:
from torch.utils.tensorboard import SummaryWriter
import numpy as np
# 第一步:實例化對象。注:不寫參數(shù)默認是 ./run/ 文件夾下
writer = SummaryWriter()
for n_iter in range(100):
# 第二步:調(diào)用對象的方法,給文件夾存數(shù)據(jù)
writer.add_scalar('Loss/train', np.random.random(), n_iter)
writer.add_scalar('Loss/test', np.random.random(), n_iter)
writer.add_scalar('Accuracy/train', np.random.random(), n_iter)
writer.add_scalar('Accuracy/test', np.random.random(), n_iter)
writer.close()
點擊運行(保存數(shù)據(jù));
在命令行輸入tensorboard --logdir=run(run是保存的數(shù)據(jù)的所在路徑)
實驗結(jié)果:
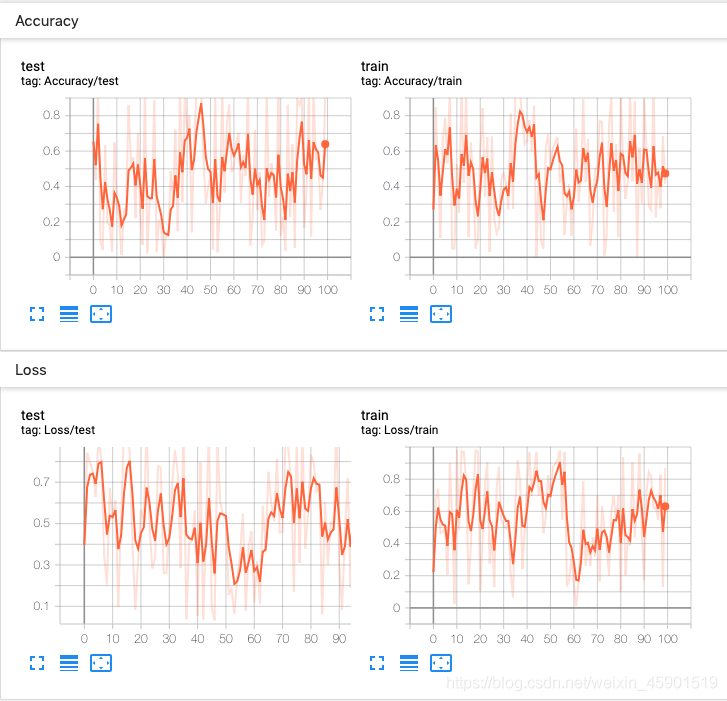
好了,現(xiàn)在你對tensorboard有了初步的認識,也知道了怎么在pytorch中 保存模型在運行過程中的一些數(shù)據(jù)了,還知道了怎么把tensorboard運行起來了。
但是,我們還沒有細講前面提到的幾個函數(shù),因此接下來我們看這幾個函數(shù)的具體使用。
二、torch.utils.tensorboard涉及的幾個函數(shù)
2.1 SummaryWriter()類
API:
class torch.utils.tensorboard.writer.SummaryWriter(log_dir=None, comment='',
purge_step=None, max_queue=10, flush_secs=120, filename_suffix='')
作用:將數(shù)據(jù)保存到 log_dir 文件夾下 以供 TensorBoard 使用。
SummaryWriter 類提供了一個高級 API,用于在給定目錄中創(chuàng)建事件文件并向其中添加摘要和事件。 該類異步更新文件內(nèi)容。 這允許訓(xùn)練程序從訓(xùn)練循環(huán)中調(diào)用直接將數(shù)據(jù)添加到文件的方法,而不會減慢訓(xùn)練速度。
下面是SummaryWriter()類的構(gòu)造函數(shù):
def __init__(log_dir=None, comment='', purge_step=None, max_queue=10, flush_secs=120,
filename_suffix='')
作用:創(chuàng)建一個 SummaryWriter 對象,它將事件和摘要寫到事件文件中。
參數(shù)說明:
log_dir (字符串):保存目錄位置。 默認值為 run/CURRENT_DATETIME_HOSTNAME ,每次運行后都會更改。 使用分層文件夾結(jié)構(gòu)可以輕松比較運行情況。 例如 為每個新實驗傳遞“ runs / exp1”,“ runs / exp2”等,以便在它們之間進行比較。comment(字符串):注釋 log_dir 后綴附加到默認值log_dir。 如果分配了log_dir,則此參數(shù)無效。purge_step (python:int ):當日志記錄在步驟 T + X T+X T+X 崩潰并在步驟 T T T 重新啟動時,將清除 global_step 大于或等于的所有事件, 隱藏在 TensorBoard 中。 請注意,崩潰的實驗和恢復(fù)的實驗應(yīng)具有相同的log_dir。max_queue (python:int ):在“添加”調(diào)用之一強行刷新到磁盤之前,未決事件和摘要的隊列大小。 默認值為十個項目。flush_secs (python:int ):將掛起的事件和摘要刷新到磁盤的頻率(以秒為單位)。 默認值為每兩分鐘一次。filename_suffix (字符串):后綴添加到 log_dir 目錄中的所有事件文件名中。 在 tensorboard.summary.writer.event_file_writer.EventFileWriter 中有關(guān)文件名構(gòu)造的更多詳細信息。
例子:
from torch.utils.tensorboard import SummaryWriter
# 使用自動生成的文件夾名稱創(chuàng)建summary writer
writer = SummaryWriter()
# folder location: runs/May04_22-14-54_s-MacBook-Pro.local/
# 使用指定的文件夾名稱創(chuàng)建summary writer
writer = SummaryWriter("my_experiment")
# folder location: my_experiment
# 創(chuàng)建一個附加注釋的 summary writer
writer = SummaryWriter(comment="LR_0.1_BATCH_16")
# folder location: runs/May04_22-14-54_s-MacBook-Pro.localLR_0.1_BATCH_16/
2.2 add_scalar()函數(shù)
API:
add_scalar(tag, scalar_value, global_step=None, walltime=None)
作用:將標量數(shù)據(jù)添加到summary
參數(shù)說明:
tag (string) : 數(shù)據(jù)標識符scalar_value (float or string/blobname) : 要保存的值global_step (int) :要記錄的全局步長值,理解成 x坐標walltime (float):可選,以事件發(fā)生后的秒數(shù)覆蓋默認的 walltime(time.time())
例子:
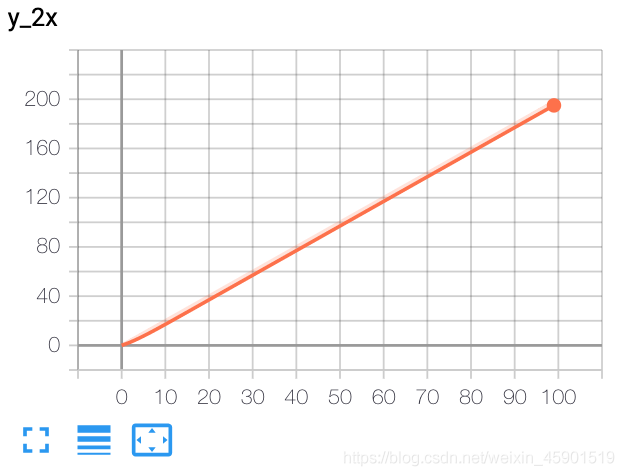
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
x = range(100)
for i in x:
writer.add_scalar('y_2x', i * 2, i)
writer.close()
結(jié)果:
2.3 add_scalars()函數(shù)
API:
add_scalars(main_tag, tag_scalar_dict, global_step=None, walltime=None)
作用:將許多標量數(shù)據(jù)添加到 summary 中。
參數(shù)說明:
main_tag (string) :標記的父名稱tag_scalar_dict (dict) :存儲標簽和對應(yīng)值的鍵值對global_step (int) :要記錄的全局步長值walltime (float) :可選的替代默認時間 Walltime(time.time())秒
例子:
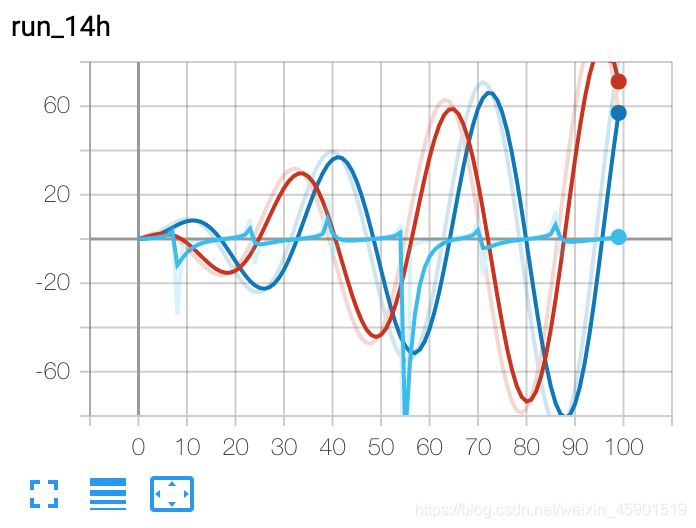
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
r = 5
for i in range(100):
writer.add_scalars('run_14h', {'xsinx':i*np.sin(i/r),
'xcosx':i*np.cos(i/r),
'tanx': np.tan(i/r)}, i)
writer.close()
# 此調(diào)用將三個值添加到帶有標記的同一個標量圖中
# 'run_14h' 在 TensorBoard 的標量部分
結(jié)果:
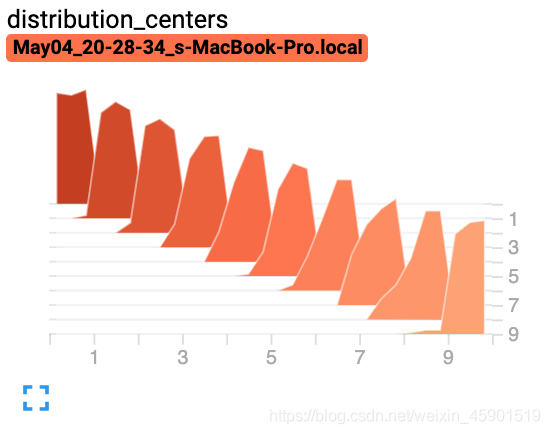
2.4 add_histogram()
add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)
作用:將直方圖添加到 summary 中。
參數(shù)說明:
tag (string): 數(shù)據(jù)標識符values (torch.Tensor, numpy.array, or string/blobname) :建立直方圖的值global_step (int) :要記錄的全局步長值bins (string) : One of {‘tensorflow','auto', ‘fd', …}. 這決定了垃圾箱的制作方式。您可以在以下位置找到其他選項:https://docs.scipy.org/doc/numpy/reference/generated/numpy.histogram.htmlwalltime (float) – Optional override default walltime (time.time()) seconds after epoch of event
例子:
from torch.utils.tensorboard import SummaryWriter
import numpy as np
writer = SummaryWriter()
for i in range(10):
x = np.random.random(1000)
writer.add_histogram('distribution centers', x + i, i)
writer.close()
結(jié)果:
我用到了上面的這些,關(guān)于更多的函數(shù)說明 ,請點擊這里查看:https://pytorch.org/docs/stable/tensorboard.html#torch-utils-tensorboard
到此這篇關(guān)于在Pytorch中簡單使用tensorboard的文章就介紹到這了,更多相關(guān)Pytorch使用tensorboard內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Pytorch中TensorBoard及torchsummary的使用詳解
- pytorch使用tensorboardX進行l(wèi)oss可視化實例
- 教你如何在Pytorch中使用TensorBoard
