目錄
- 1. 在Python中使用中文
- 1.1 Windows控制臺
- 1.2 Windows IDLE(在Shell上運行)
- 1.3 在IDLE上運行代碼
- 1.4 Windows Eclipse
- 1.5 從文件讀取中文
- 1.6 在數據庫中使用中文
- 1.7 在XML中使用中文
1. 在Python中使用中文
在Python中有兩種默認的字符串:str和unicode����。在Python中一定要注意區分“Unicode字符串”和“unicode對象”的區別����。后面所有的“unicode字符串”指的都是python里的“unicode對象”����。
事實上在Python中并沒有“Unicode字符串”這樣的東西,只有“unicode”對象����。一個傳統意義上的unicode字符串完全可以用str對象表示����。只是這時候它僅僅是一個字節流����,除非解碼為unicode對象,沒有任何實際的意義����。
我們用“哈哈”在多個平臺上測試����,其中“哈”對應的不同編碼是:
1. UNICODE (UTF8-16), C854;
2. UTF-8����, E59388����;
3. GBK����, B9FE。
1.1 Windows控制臺
下面是在windows控制臺的運行結果:

可以看出在控制臺,中文字符的編碼是GBK而不是UTF-16����。將字符串s(GBK編碼)使用decode進行解碼后����,可以得到同等的unicode對象����。
注意:可以在控制臺打印ss并不代表它可以直接被序列化����,比如:

向文件直接輸出ss會拋出同樣的異常。在處理unicode中文字符串的時候����,必須首先對它調用encode函數����,轉換成其它編碼輸出����。這一點對各個環境都一樣。
總結:在Python中����,“str”對象就是一個字節數組����,至于里面的內容是不是一個合法的字符串����,以及這個字符串采用什么編碼(gbk, utf-8, unicode)都不重要����。這些內容需要用戶自己記錄和判斷����。這些的限制也同樣適用于“unicode”對象。要記住“unicode”對象中的內容可絕對不一定就是合法的unicode字符串,我們很快就會看到這種情況����。
總結:在windows的控制臺上,支持gbk編碼的str對象和unicode編碼的unicode對象����。
1.2 Windows IDLE(在Shell上運行)
在windows下的IDLE中����,運行效果和windows控制臺不完全一致:

可以看出����,對于不使用“u”作標識的字符串,IDLE把其中的中文字符進行GBK編碼����。但是對于使用“u”的unicode字符串����,IDLE居然一樣是用了GBK編碼����,不同的是,這時候每一個字符都是unicode(對象)字符?���?���!此時len(ss) = 4����。
這樣產生了一個神奇的問題,現在的ss無法在IDLE中正常顯示����。而且我也沒有辦法把ss轉換成正常的編碼!比如采用下面的方法:

這有可能是因為IDLE本地化做得不夠好����,對中文的支持有問題����。建議在IDLE的SHELL中����,不要使用u“中文”這種方式,因為這樣得到的并不是你想要的東西。
這同時說明IDLE的Shell支持兩種格式的中文字符串:GBK編碼的“str”對象����,和UNICODE編碼的unicode對象����。
1.3 在IDLE上運行代碼
在IDLE的SHELL上運行文件����,得到的又是不同的結果。文件的內容是:

直接運行的結果是:

毫無瑕疵����,相當令人滿意����。我沒有試過其它編碼的文件是否能正常運行����,但想來應該是不錯的����。
同樣的代碼在windows的控制臺試演過����,也沒有任何問題����。
1.4 Windows Eclipse
在Eclipse中處理中文更加困難,因為在Eclipse中,編寫代碼和運行代碼屬于不同的窗口,而且他們可以有不同的默認編碼。對于如下代碼:
#!/usr/bin/python
# -*- coding: utf-8 -*-
s = "哈哈"
ss = u'哈哈'
print repr(s)
print repr(ss)
print s.decode('utf-8').encode('gbk')
print ss.encode('gbk')
print s.decode('utf-8')
print ss
前四個print運行正常����,最后兩個print都會拋出異常:
'/xe5/x93/x88/xe5/x93/x88'
u'/u54c8/u54c8'
哈哈
哈哈
Traceback (most recent call last):
File "E:/Workspace/Eclipse/TestPython/Test/test_encoding_2.py", line 13, in module>
print s.decode('utf-8')
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
也就是說����,GBK編碼的str對象可以正常打印����,但是不能打印UNICODE編碼的unicode對象。在源文件上點擊“Run as”“Run”,然后在彈出對話框中選擇“Common”:
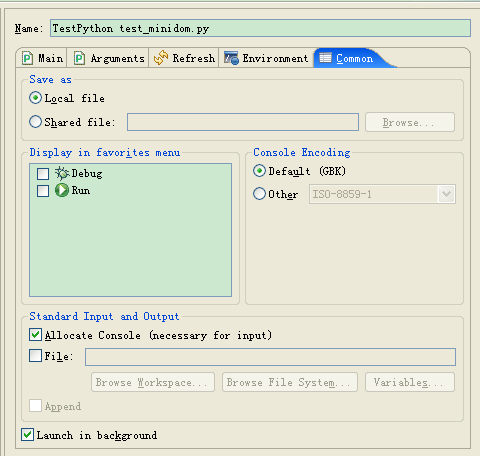
可以看出Eclipse控制臺的缺省編碼方式是GBK����;所以不支持UNICODE也在情理之中����。如果把文件中的coding修改成GBK����,則可以直接打印GBK編碼的str對象,比如s。
如果把源文件的編碼設置成“UTF-8”����,把控制臺的編碼也設置成“UTF-8”,按道理說打印的時候應該沒有問題����。但是實驗表明����,在打印UTF-8編碼的str對象時����,中文的最后一個字符會顯示成亂碼,無法正常閱讀����。不過我已經很滿足了����,至少人家沒有拋異常不是:)
BTW: 使用的Eclipse版本是3.2.1����。
1.5 從文件讀取中文
在window下面用記事本編輯文件的時候,如果保存為UNICODE或UTF-8����,分別會在文件的開頭加上兩個字節 “/xFF/xFE” 和三個字節“/xEF/xBB/xBF”����。在讀取的時候就可能會遇到問題����,但是不同的環境對這幾個多于字符的處理也不一樣。
以windows下的控制臺為例����,用記事本保存三個不同版本的“哈哈”。
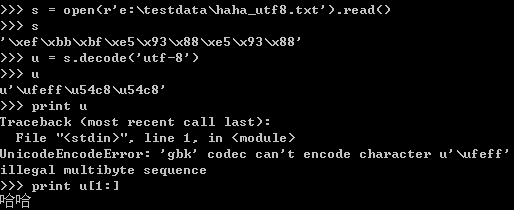
打開utf-8格式的文件并讀取utf-8字符串后,解碼變成unicode對象����。但是會把附加的三個字符同樣進行轉換����,變成一個unicode字符,字符的數據值為“/xFF/xFE”����。這個字符不能被打印����。編碼的時候需要跳過這個字符����。

打開unicode格式的文件后,得到的字符串正確����。這時候適用utf-16解碼����,能得到正確的unicdoe對象����,可以直接使用。多余的那個填充字符在進行轉換時會被過濾掉����。

打開ansi格式的文件后����,沒有填充字符����,可以直接使用����。
結論:讀寫使用python生成的文件沒有任何問題,但是在處理由notepad生成的文本文件時����,如果該文件可能是非ansi編碼����,需要考慮如何處理填充字符����。
1.6 在數據庫中使用中文
剛剛接觸Python,我用的數據庫是mysql。在執行插入、查找等操作時����,如果運行環境使用的字符編碼和mysql不一致����,就可能導致運行時的錯誤����。當然,和上面看到的情況一樣,運行環境并不是關鍵因素,關鍵是查詢語句的編碼方式。如果在每次執行查詢操作時都把查詢字符串做一次編碼轉換,轉變成mysql的默認字符編碼����,一樣不會遇到問題����。但是這樣寫代碼也太痛苦了吧����。
使用如下代碼連接數據庫:
self.conn = MySQLdb.connect(use_unicode = 1, charset='utf8', **server)
我不能理解的是既然數據庫用的默認編碼是UTF-8����,我連接的時候也用的是UTF-8����,為什么查詢得到的文本內容卻是UNICODE編碼(unicode對象)����?這是MySQLdb庫的設置么?
1.7 在XML中使用中文
使用xml.dom.minidom和MySQLdb類似,對生成的dom對象調用toxml方法得到的是unicode對象����。如果希望輸出utf-8文本����,有兩種方法:
1.使用系統函數
在輸出xml文檔的時候進行編碼����,這是我覺得最好的方法。
xmldoc.toxml(encoding='utf-8')
xmldoc.writexml(outfile, encoding = ‘utf-8')
2.自己編碼生成
在使用toxml之后可以調用encode方法對文檔進行編碼。但這種方法無法得到合適的xml declaration(xml文檔第一行中的encoding部分)����。
不要嘗試通過xmldoc.createProcessingInstruction來創建一個processing instraction:
?xml version='1.0' encoding='utf-8'?>
xml declaration雖然看起來像是����,但是事實上并不是一個processing instraction����?���?梢酝ㄏ旅娴姆椒ǖ玫揭粋€滿意的xml文件:
print >> outfile, “?xml version='1.0' encoding='utf-8'?>”
print >> outfile, xmldoc.toxml().encode(‘utf-8')[22:]
其中第二行需要過濾掉在調用xmldoc.toxml時生成的“?xml version='1.0' ?>”,它的長度是22����。
相面是兩種方法的用法比較:

另外����,在IDLE的shell中����,不要用 u'中文' 對屬性進行賦值。上面討論過����,這樣得到的unicode字符串不正確����。
到此這篇關于python中文編碼問題的文章就介紹到這了,更多相關中文編碼內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家����!
您可能感興趣的文章:- 用基于python的appium爬取b站直播消費記錄
- 女友半夜加班發自拍 python男友用30行代碼發現驚天秘密
- 前女友發來加密的"520快樂.pdf",我用python破解開之后,卻發現...
- 在前女友婚禮上用python把婚禮現場的WIFI名稱改成了
