目錄
- 一、環(huán)境準(zhǔn)備
- 二、決策樹是什么
- 三、快速入門分類樹
- 四、詳細(xì)分析入門案例
- 五、分類樹參數(shù)解釋
- 5.1、criterion
- 5.2、random_state splitter
- 5.3、剪枝參數(shù)
- 5.4、目標(biāo)權(quán)重參數(shù):class_weight min_weight_fraction_leaf
一、環(huán)境準(zhǔn)備
在開始學(xué)習(xí)前,需要準(zhǔn)備好相應(yīng)的環(huán)境配置。這里我選擇了anaconda,創(chuàng)建了一個專門的虛擬環(huán)境來學(xué)習(xí)機(jī)器學(xué)習(xí)。這里關(guān)于anaconda的安裝等就不贅述了,沒有難度。
二、決策樹是什么
通俗的說,有督促學(xué)習(xí)方法就是需要一個標(biāo)簽,即在知道答案的基礎(chǔ)上進(jìn)行模型訓(xùn)練。決策樹就是從數(shù)據(jù)中讀取出特定的特征,根據(jù)這些特征總結(jié)出決策規(guī),然后使用樹結(jié)構(gòu)來呈現(xiàn)。
三、快速入門分類樹
得益于強(qiáng)大的sklearn庫,讓我們使用決策樹的算法十分簡單:
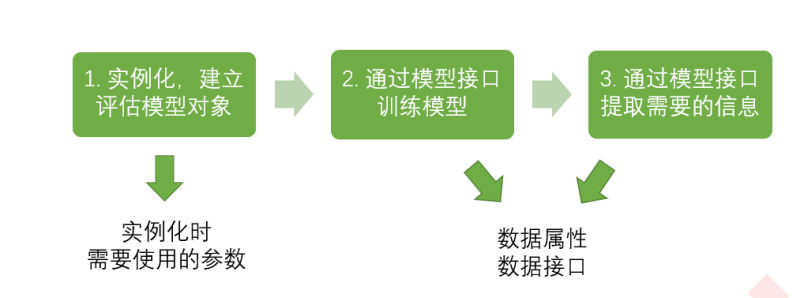
在這里,我們引入紅酒數(shù)據(jù)集,這是一個很小的數(shù)據(jù)集。
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
wine = load_wine()
然后我們就可以看看數(shù)據(jù)集長啥樣了:
wine.data.shape
(178, 13)
wine.target
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2])
但這么看似乎不是很直觀。我們使用pandas轉(zhuǎn)換成表格格式:
import pandas as pd
pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1)
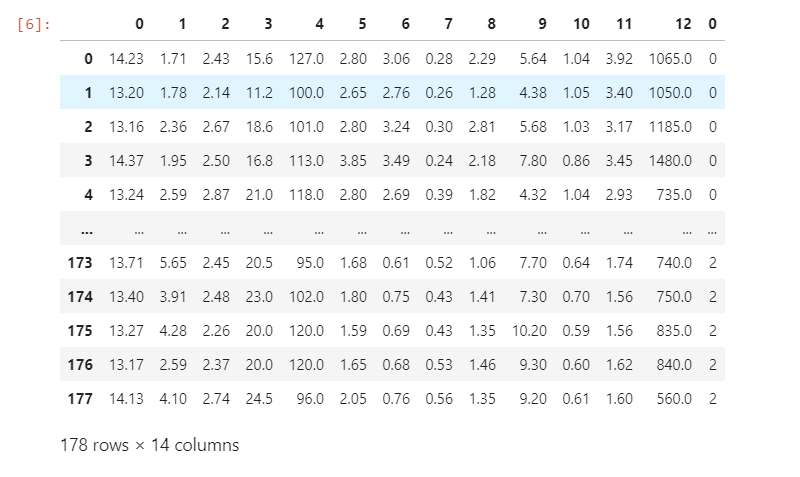
可以看到,這個數(shù)據(jù)集只有178行,14列。數(shù)據(jù)量還是很小的。最后一列是我們的標(biāo)簽,每個數(shù)字對應(yīng)一個具體的分類。
wine.feature_names
['alcohol',
'malic_acid',
'ash',
'alcalinity_of_ash',
'magnesium',
'total_phenols',
'flavanoids',
'nonflavanoid_phenols',
'proanthocyanins',
'color_intensity',
'hue',
'od280/od315_of_diluted_wines',
'proline']
可以看到,每個列對應(yīng)一個特征,如0號列對應(yīng)的就是alcohol,即酒精含量。其他的以此類推。
在看完數(shù)據(jù)集后,我們直接上手訓(xùn)練模型唄!
x_train,x_test,y_train,y_test = train_test_split(wine.data,wine.target,test_size=0.3)
clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(x_train,y_train)
score = clf.score(x_test,y_test) # 返回預(yù)測的準(zhǔn)確度accuracy
先分測試集,即第一行代碼。然后我們調(diào)用函數(shù),使用fit來訓(xùn)練,score來打分。運(yùn)行這段代碼,我們看看得了多少分:

百分之九十的準(zhǔn)確率,還是十分高的。
但這么看,似乎不是很直觀啊。我們可以把這棵樹畫出來:
feature_name = ['酒精','蘋果酸','灰','灰的堿性','鎂','總酚','類黃酮','非黃烷類酚類','花青素','顏色強(qiáng)度','色調(diào)','od280/od315稀釋葡萄酒','脯氨酸']
import graphviz
# filled 顏色 rounded 圓角
dot_data = tree.export_graphviz(clf
,feature_names=feature_name
,class_names=["琴酒","雪莉","貝爾摩德"]
,filled=True
,rounded=True
)
graph = graphviz.Source(dot_data)
graph
這里我們引入了graphviz包,畫出了我們剛才的決策樹:
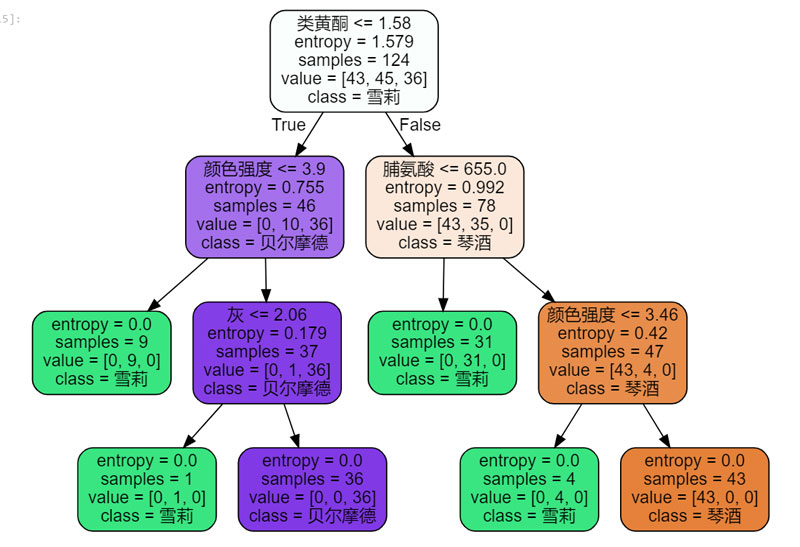
這里的class是隨便寫的,你也可以寫別的。
四、詳細(xì)分析入門案例
可以看到,我們這棵樹中并沒有使用所有的特征,可能只使用了四五個的樣子。我們可以使用一個函數(shù)來看看每個特征的百分比:
clf.feature_importances_
array([0. , 0. , 0.03388406, 0. , 0. ,
0. , 0.42702463, 0. , 0. , 0.24446215,
0. , 0. , 0.29462916])
可以看到,我們只用了4個特征,得出了一顆樹。這么看似乎不是很直觀,我們用zip函數(shù)和對應(yīng)的特征聯(lián)一下:
[*zip(feature_name,clf.feature_importances_)]
[('酒精', 0.0),
('蘋果酸', 0.0),
('灰', 0.03388405728736582),
('灰的堿性', 0.0),
('鎂', 0.0),
('總酚', 0.0),
('類黃酮', 0.42702463433869187),
('非黃烷類酚類', 0.0),
('花青素', 0.0),
('顏色強(qiáng)度', 0.24446214572197708),
('色調(diào)', 0.0),
('od280/od315稀釋葡萄酒', 0.0),
('脯氨酸', 0.29462916265196526)]
這樣我們就會發(fā)現(xiàn),占比最大的就構(gòu)成了決策樹的根節(jié)點(diǎn),然后以此類推。
五、分類樹參數(shù)解釋
5.1、criterion
為了要將表格轉(zhuǎn)化為一棵樹,決策樹需要找出最佳節(jié)點(diǎn)和最佳的分枝方法,對分類樹來說,衡量這個“最佳”的指標(biāo)叫做“不純度”。通常來說,不純度越低,決策樹對訓(xùn)練集的擬合越好。現(xiàn)在使用的決策樹算法在分枝方法上的核心大多是圍繞在對某個不純度相關(guān)指標(biāo)的最優(yōu)化上。
暫且不去理解所謂不純度的概念,這個參數(shù)我們有兩種取值:entropy與gini。那么這兩種算法有什么區(qū)別呢?
比起基尼系數(shù),信息熵對不純度更加敏感,對不純度的懲罰最強(qiáng)。但是在實(shí)際使用中,信息熵和基尼系數(shù)的效果基本相同。信息熵的計算比基尼系數(shù)緩慢一些,因?yàn)榛嵯禂?shù)的計算不涉及對數(shù)。另外,因?yàn)樾畔㈧貙Σ患兌雀用舾校孕畔㈧刈鳛橹笜?biāo)時,決策樹的生長會更加“精細(xì)”,因此對于高維數(shù)據(jù)或者噪音過多的數(shù)據(jù),信息熵很容易過擬合,基尼系數(shù)在這種情況下效果往往比較好。當(dāng)模型擬合程度不足的時候,即當(dāng)模型在訓(xùn)練集和測試集上都表現(xiàn)不太好的時候,使用信息熵。當(dāng)然,這些不是絕對的。
簡單來說,我們在調(diào)參時可以兩個都試試,默認(rèn)是gini。因?yàn)檫@兩個算法其實(shí)并沒有絕對說用哪個。
5.2、random_state splitter
random_state用來設(shè)置分枝中的隨機(jī)模式的參數(shù),默認(rèn)None,在高維度時隨機(jī)性會表現(xiàn)更明顯,低維度的數(shù)據(jù)(比如鳶尾花數(shù)據(jù)集),隨機(jī)性幾乎不會顯現(xiàn)。輸入任意整數(shù),會一直長出同一棵樹,讓模型穩(wěn)定下來。
splitter也是用來控制決策樹中的隨機(jī)選項的,有兩種輸入值,輸入”best",決策樹在分枝時雖然隨機(jī),但是還是會優(yōu)先選擇更重要的特征進(jìn)行分枝(重要性可以通過屬性feature_importances_查看),輸入“random",決策樹在分枝時會更加隨機(jī),樹會因?yàn)楹懈嗟牟槐匾畔⒍罡螅⒁蜻@些不必要信息而降低對訓(xùn)練集的擬合。這也是防止過擬合的一種方式。
這兩個參數(shù)可以讓樹的模型穩(wěn)定,并且更好的使用模型。
clf = tree.DecisionTreeClassifier(criterion="entropy"
,random_state=0
,splitter="random"
)
clf = clf.fit(x_train, y_train)
score = clf.score(x_test, y_test)
score
比如我們添加了一些參數(shù)后,再次運(yùn)行:
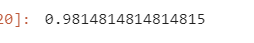
可以發(fā)現(xiàn)準(zhǔn)確率飛到了98%,這說明我們參數(shù)的調(diào)整還是很有用的。
5.3、剪枝參數(shù)
在不加限制的情況下,一棵決策樹會生長到衡量不純度的指標(biāo)最優(yōu),或者沒有更多的特征可用為止。這樣的決策樹往往會過擬合,這就是說,它會在訓(xùn)練集上表現(xiàn)很好,在測試集上卻表現(xiàn)糟糕。我們收集的樣本數(shù)據(jù)不可能和整體的狀況完全一致,因此當(dāng)一棵決策樹對訓(xùn)練數(shù)據(jù)有了過于優(yōu)秀的解釋性,它找出的規(guī)則必然包含了訓(xùn)練樣本中的噪聲,并使它對未知數(shù)據(jù)的擬合程度不足。
簡單的說,我們需要對決策樹進(jìn)行限制,不能讓他無限制的增長下去,不然只會讓模型過擬合。
max_depth:
限制樹的最大深度,超過設(shè)定深度的樹枝全部剪掉。這是使用的最廣泛的剪枝參數(shù),實(shí)際使用建議從3開始嘗試。
min_samples_leaf min_samples_split:
min_samples_leaf限定,一個節(jié)點(diǎn)在分枝后的每個子節(jié)點(diǎn)都必須包含至少min_samples_leaf個訓(xùn)練樣本,否則分枝就不會發(fā)生,或者,分枝會朝著滿足每個子節(jié)點(diǎn)都包含min_samples_leaf個樣本的方向去發(fā)生。
min_samples_split限定,一個節(jié)點(diǎn)必須要包含至少min_samples_split個訓(xùn)練樣本,這個節(jié)點(diǎn)才允許被分枝,否則分枝就不會發(fā)生。
這段話看起來很繞口,我們結(jié)合代碼:
clf = tree.DecisionTreeClassifier(criterion="entropy"
,random_state=30
,splitter="random"
,max_depth=4
#,min_samples_leaf=12
#,min_samples_split=10
,
)
clf = clf.fit(x_train, y_train)
dot_data = tree.export_graphviz(clf
,feature_names= feature_name
,class_names=["琴酒","雪莉","貝爾摩德"]
,filled=True
,rounded=True
)
graph = graphviz.Source(dot_data)
graph
可以自己去跑一下理解一下。
max_features min_impurity_decrease:
max_features限制分枝時考慮的特征個數(shù),超過限制個數(shù)的特征都會被舍棄。和max_depth異曲同工,max_features是用來限制高維度數(shù)據(jù)的過擬合的剪枝參數(shù),但其方法比較暴力,是直接限制可以使用的特征數(shù)量而強(qiáng)行使決策樹停下的參數(shù),在不知道決策樹中的各個特征的重要性的情況下,強(qiáng)行設(shè)定這個參數(shù)可能會導(dǎo)致模型學(xué)習(xí)不足。如果希望通過降維的方式防止過擬合,建議使用PCA,ICA或者特征選擇模塊中的降維算法。
但我們怎么確定一個參數(shù)是最優(yōu)的呢?我們可以通過畫圖的方式來查看:
import matplotlib.pyplot as plt
from matplotlib.pyplot import MultipleLocator
test = []
for i in range(50):
clf = tree.DecisionTreeClassifier(max_depth=4
,criterion="entropy"
,random_state=30
,splitter="random"
,min_samples_leaf=i+5
)
clf = clf.fit(x_train, y_train)
score = clf.score(x_test, y_test)
test.append(score)
x_major_locator=MultipleLocator(2)
plt.plot(range(1,51),test,color="green",label="min_samples_leaf")
ax=plt.gca()
ax.xaxis.set_major_locator(x_major_locator)
plt.legend()
plt.show()

我們就可以清晰的看到了最高點(diǎn)出現(xiàn)在什么地方,進(jìn)而更好的調(diào)參。
5.4、目標(biāo)權(quán)重參數(shù):class_weight min_weight_fraction_leaf
完成樣本標(biāo)簽平衡的參數(shù)。樣本不平衡是指在一組數(shù)據(jù)集中,標(biāo)簽的一類天生占有很大的比例。比如說,在銀行要判斷“一個辦了信用卡的人是否會違約”,就是是vs否(1%:99%)的比例。這種分類狀況下,即便模型什么也不做,全把結(jié)果預(yù)測成“否”,正確率也能有99%。因此我們要使用class_weight參數(shù)對樣本標(biāo)簽進(jìn)行一定的均衡,給少量的標(biāo)簽更多的權(quán)重,讓模型更偏向少數(shù)類,向捕獲少數(shù)類的方向建模。該參數(shù)默認(rèn)None,此模式表示自動給與數(shù)據(jù)集中的所有標(biāo)簽相同的權(quán)重。
有了權(quán)重之后,樣本量就不再是單純地記錄數(shù)目,而是受輸入的權(quán)重影響了,因此這時候剪枝,就需要搭配min_weight_fraction_leaf這個基于權(quán)重的剪枝參數(shù)來使用。另請注意,基于權(quán)重的剪枝參數(shù)(例如min_weight_fraction_leaf)將比不知道樣本權(quán)重的標(biāo)準(zhǔn)(比如min_samples_leaf)更少偏向主導(dǎo)類。如果樣本是加權(quán)的,則使用基于權(quán)重的預(yù)修剪標(biāo)準(zhǔn)來更容易優(yōu)化樹結(jié)構(gòu),這確保葉節(jié)點(diǎn)至少包含樣本權(quán)重的總和的一小部分。
以上就是分析機(jī)器學(xué)習(xí)之決策樹Python實(shí)現(xiàn)的詳細(xì)內(nèi)容,更多關(guān)于Python實(shí)現(xiàn)決策樹的資料請關(guān)注腳本之家其它相關(guān)文章!
您可能感興趣的文章:- Python機(jī)器學(xué)習(xí)算法之決策樹算法的實(shí)現(xiàn)與優(yōu)缺點(diǎn)
- Python機(jī)器學(xué)習(xí)之決策樹
- python機(jī)器學(xué)習(xí)實(shí)現(xiàn)決策樹
- Python機(jī)器學(xué)習(xí)算法庫scikit-learn學(xué)習(xí)之決策樹實(shí)現(xiàn)方法詳解
- python機(jī)器學(xué)習(xí)理論與實(shí)戰(zhàn)(二)決策樹
- Python機(jī)器學(xué)習(xí)之決策樹算法
- python機(jī)器學(xué)習(xí)之決策樹分類詳解
- Python機(jī)器學(xué)習(xí)之決策樹算法實(shí)例詳解
- 機(jī)器學(xué)習(xí)python實(shí)戰(zhàn)之決策樹
