| Level | 說明 |
|---|---|
| DEBUG | 輸出詳細的運行信息,主要用于調試,追蹤問題時使用 |
| INFO | 輸出正常的運行的信息,一切按預期進行的情況 |
| WARNING | 一些意想不到的或即將會發生的情況,比如警告:內存空間不足,但不影響程序運行 |
| ERROR | 由于某些問題,程序的一些功能會受到影響,還可以繼續運行 |
| CRITICAL | 一個嚴重的錯誤,表明程序本身可能無法繼續運行 |
這些等級的日志中低包含高,比如INFO,會收集INFO及以上等級的日志,DEBUG等級的日志將不進行收集。下面我們來輸出這5個等級的日志:
import logging
"""
logging模塊默認收集的日志是warning以上等級的
"""
a = 100
logging.debug(a)
logging.info('這是INFO等級的信息')
logging.warning('這是WARNING等級的信息')
logging.error('這是ERROR等級的信息')
logging.critical('這是CRITICAL等級的信息')
輸出結果:
C:\software\python\python.exe D:/learn/test.py
WARNING:root:這是WARNING等級的信息
ERROR:root:這是ERROR等級的信息
CRITICAL:root:這是CRITICAL等級的信息
Process finished with exit code 0
日志是怎么被收集和輸出的呢?答案就是日志收集器,設置一個收集器,把指等級的日志信息輸出到指定的地方,控制臺或文件等,其工作過程大致如下:
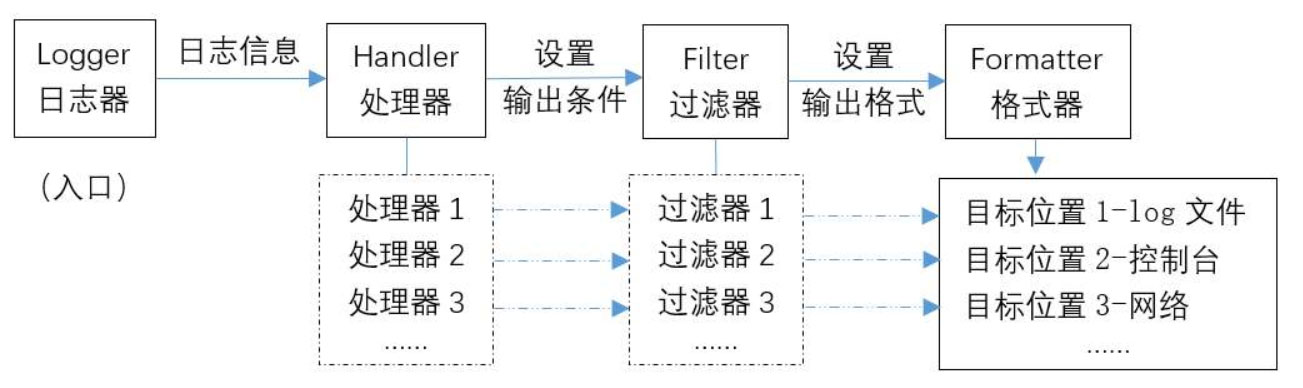
logging中默認的日志收集器是root,收集等級默認是WARNING,我們可以通過setLevel來改變它的收集等級。
# 獲取默認的日志收集器root
my_log = logging.getLogger()
# 設置默認的日志收集器等級
my_log.setLevel("DEBUG") # 日志將全部被收集
a = 100
logging.debug(a)
logging.info('這是INFO等級的信息')
logging.warning('這是WARNING等級的信息')
logging.error('這是ERROR等級的信息')
logging.critical('這是CRITICAL等級的信息')
輸出結果:
C:\software\python\python.exe D:/learn/test.py
DEBUG:root:100
INFO:root:這是INFO等級的信息
WARNING:root:這是WARNING等級的信息
ERROR:root:這是ERROR等級的信息
CRITICAL:root:這是CRITICAL等級的信息
Process finished with exit code 0
除了使用默認的日志收集器,我們也可以自己創建一個收集器logging.getLogger,如下:
import logging
my_logger = logging.getLogger('my_logger') # 創建logging對象
my_logger.setLevel('INFO') # 設置日志收集等級
a = 100
logging.debug(a)
logging.info('這是INFO等級的信息')
logging.warning('這是WARNING等級的信息')
logging.error('這是ERROR等級的信息')
logging.critical('這是CRITICAL等級的信息')
輸出結果:
C:\software\python\python.exe D:/learn/test.py
WARNING:root:這是WARNING等級的信息
ERROR:root:這是ERROR等級的信息
CRITICAL:root:這是CRITICAL等級的信息
Process finished with exit code 0
上面例子中設置的收集器都是輸出到控制臺,除此我們還可以輸出到文件中。
Handlers(處理器)的作用就是將logger發過來的信息進行準確地分配,送往正確的地方。比如,送往控制臺、文件或者是兩者。它決定了每個日志收集器的行為,是創建收集器之后需要配置的重點區域。每個Handler同樣有一個日志級別,一個logger可以擁有多個handler也就是說logger可以根據不同的日志級別將日志傳遞給不同的handler。當然也可以相同的級別傳遞給多個handler,這就根據需求來靈活的配置了。
下面實例中設置了兩個handler,一個是輸出到控制臺,一個是輸出到文件中。關鍵代碼:
logging.StreamHandler:輸出到控制臺的處理器logging.FileHandler:輸出到文件的處理器addHandler:添加處理器removeHandler:移除處理器
import logging
my_logger = logging.getLogger('my_logger')
my_logger.setLevel('INFO')
# 創建一個輸出到控制臺的處理器
sh = logging.StreamHandler()
sh.setLevel("ERROR") # 設置處理器的輸出等級
my_logger.addHandler(sh) # 將處理器綁定到日志收集器上
# 創建一個輸出到文件的處理器
fh = logging.FileHandler("logs.logs", encoding="utf8")
fh.setLevel("INFO")
my_logger.addHandler(fh)
# my_logger.removeHandler(fh) # 移除處理器
a = 100
my_logger.debug(a)
my_logger.info('這是INFO等級的信息')
my_logger.warning('這是WARNING等級的信息')
my_logger.error('這是ERROR等級的信息')
my_logger.critical('這是CRITICAL等級的信息')
運行結果:
C:\software\python\python.exe D:/learn/test.py
這是ERROR等級的信息
這是CRITICAL等級的信息
Process finished with exit code 0

Filters可以實現比level更復雜的過濾功能,限制只有滿足過濾規則的日志才會被輸出。比如我們定義了filter = logging.Filter('A.B'),并將這個Filter添加到了一個Handler上,則使用該Handler的Logger中只有名字帶A.B前綴的Logger才能輸出其日志。下面是一個簡單實例:
import logging
# 這是logger1
my_logger = logging.getLogger('A.C,B')
my_logger.setLevel('INFO')
# 這是logger2
my_logger2 = logging.getLogger('A.B')
my_logger2.setLevel('INFO')
# 創建一個處理器,兩個logger都使用這個處理器
sh = logging.StreamHandler()
sh.setLevel("ERROR")
my_logger.addHandler(sh)
my_logger2.addHandler(sh)
# 創建一個過濾器綁到處理器上
my_filter = logging.Filter(name='A.B')
sh.addFilter(my_filter) # 把過濾器添加到處理器上
# sh2.removeFilter(my_filter) # 移除過濾器
my_logger.debug('這是logger1-DEBUG等級的信息')
my_logger.info('這是logger1-INFO等級的信息')
my_logger.warning('這是logger1-WARNING等級的信息')
my_logger.error('這是logger1-ERROR等級的信息')
my_logger.critical('這是logger1-CRITICAL等級的信息')
my_logger2.debug('這是logger2-DEBUG等級的信息')
my_logger2.info('這是logger2-INFO等級的信息')
my_logger2.warning('這是logger2-WARNING等級的信息')
my_logger2.error('這是logger2-ERROR等級的信息')
my_logger2.critical('這是logger2-CRITICAL等級的信息')
因為只有logger2滿足過濾器的條件,因此只會輸出logger2的日志,運行結果如下:
C:\software\python\python.exe D:/learn/test.py
這是logger2-ERROR等級的信息
這是logger2-CRITICAL等級的信息
Process finished with exit code 0
filter方法用于具體控制傳遞的record記錄是否能通過過濾,如果該方法返回值為0表示不能通過過濾,非0表示可以通過過濾。
顧名思義,對日志進行格式化,因為常規的日志輸出并不直觀美觀,通過美化日志的輸出格式,可以讓我們閱讀起來更加舒服。
format常用格式如下:
%(name)s: 打印收集器名稱%(levelno)s: 打印日志級別的數值%(levelname)s: 打印日志級別名稱%(pathname)s: 打印當前執行程序的路徑,其實就是sys.argv[0]%(filename)s: 打印當前執行程序名%(funcName)s: 打印日志的當前函數%(lineno)d: 打印日志的當前行號%(asctime)s: 打印日志的時間%(thread)d: 打印線程ID%(threadName)s: 打印線程名稱%(process)d: 打印進程ID%(message)s: 打印日志信息
import logging
my_logger = logging.getLogger('A.C,B')
my_logger.setLevel('INFO')
# 創建一個處理器
sh = logging.StreamHandler()
sh.setLevel("ERROR")
my_logger.addHandler(sh)
# 設置一個格式,并設置到處理器上
formatter = logging.Formatter('%(asctime)s - [%(filename)s-->line:%(lineno)d] - %(levelname)s: %(message)s')
sh.setFormatter(formatter)
my_logger.debug('這是logger1-DEBUG等級的信息')
my_logger.info('這是logger1-INFO等級的信息')
my_logger.warning('這是logger1-WARNING等級的信息')
my_logger.error('這是logger1-ERROR等級的信息')
my_logger.critical('這是logger1-CRITICAL等級的信息')
運行結果:
C:\software\python\python.exe D:/learn/test.py
2020-08-01 18:28:43,645 - [test.py-->line:17] - ERROR: 這是logger1-ERROR等級的信息
2020-08-01 18:28:43,645 - [test.py-->line:18] - CRITICAL: 這是logger1-CRITICAL等級的信息
Process finished with exit code 0
如果你用 FileHandler 存儲日志,文件的大小會隨著時間推移而不斷增大,最終有一天它會占滿你所有的磁盤空間。Python 的 logging 模塊提供了兩個支持日志滾動的 FileHandler 類,分別是 RotatingFileHandler 和 TimedRotatingFileHandler,它就可以解決這個尷尬的問題。
在實際應用中,我們通常會根據時間進行滾動,以下實例也以時間滾動為例,按大小滾動的同理:
import logging
from logging.handlers import TimedRotatingFileHandler
my_logger = logging.getLogger('A.C,B')
my_logger.setLevel('INFO')
# 創建一個處理器,使用時間滾動的文件處理器
log_file_handler = TimedRotatingFileHandler(filename='log.log', when='D', interval=1, backupCount=10)
# log_file_handler.suffix = "%Y-%m-%d"
# log_file_handler.extMatch = re.compile(r"^\d{4}-\d{2}-\d{2}.log$")
log_file_handler.setLevel("ERROR")
my_logger.addHandler(log_file_handler)
# 設置一個格式,并設置到處理器上
formatter = logging.Formatter('%(asctime)s - [%(filename)s-->line:%(lineno)d] - %(levelname)s: %(message)s')
log_file_handler.setFormatter(formatter)
my_logger.debug('這是logger1-DEBUG等級的信息')
my_logger.info('這是logger1-INFO等級的信息')
my_logger.warning('這是logger1-WARNING等級的信息')
my_logger.error('這是logger1-ERROR等級的信息')
my_logger.critical('這是logger1-CRITICAL等級的信息')
參數說明:
filename:日志文件名;
when:是一個字符串,用于描述滾動周期的基本單位,字符串的值及意義如下:
interval: 滾動周期,單位由when指定,比如:when='D',interval=1,表示每天產生一個日志文件;
backupCount: 表示日志文件的保留個數;
除了上述參數之外,TimedRotatingFileHandler還有兩個比較重要的成員變量,它們分別是suffix和extMatch。suffix是指日志文件名的后綴,suffix中通常帶有格式化的時間字符串,filename和suffix由“.”連接構成文件名(例如:filename="test", suffix="%Y-%m-%d.log",生成的文件名為test.2020-08-01.log。extMatch是一個編譯好的正則表達式,用于匹配日志文件名的后綴,它必須和suffix是匹配的,如果suffix和extMatch匹配不上的話,過期的日志是不會被刪除的。比如,suffix=“%Y-%m-%d.log”, extMatch的只能是re.compile(r"^\d{4}-\d{2}-\d{2}.log$")。默認情況下,在TimedRotatingFileHandler對象初始化時,suffxi和extMatch會根據when的值進行初始化:
S:suffix="%Y-%m-%d_%H-%M-%S",extMatch=r"\^d{4}-\d{2}-\d{2}_\d{2}-\d{2}-\d{2}";
M:suffix="%Y-%m-%d_%H-%M",extMatch=r"^\d{4}-\d{2}-\d{2}_\d{2}-\d{2}";
H:suffix="%Y-%m-%d_%H",extMatch=r"^\d{4}-\d{2}-\d{2}_\d{2}";
D:suffxi="%Y-%m-%d",extMatch=r"^\d{4}-\d{2}-\d{2}";
MIDNIGHT:"%Y-%m-%d",extMatch=r"^\d{4}-\d{2}-\d{2}";
W:"%Y-%m-%d",extMatch=r"^\d{4}-\d{2}-\d{2}";
如果對日志文件名沒有特殊要求的話,可以不用設置suffix和extMatch,如果需要,一定要讓它們匹配上。
一次封裝,一勞永逸,之后直接調用即可,封裝內容按需。
import logging
from logging.handlers import TimedRotatingFileHandler
class MyLogger(object):
@staticmethod
def create_logger():
my_logger = logging.getLogger("my_logger")
my_logger.setLevel("DEBUG")
# 控制臺處理器
stream_handler = logging.StreamHandler()
stream_handler.setLevel("ERROR")
my_logger.addHandler(stream_handler)
# 使用時間滾動的文件處理器
log_file_handler = TimedRotatingFileHandler(filename='log.log', when='D', interval=1, backupCount=10)
log_file_handler.setLevel("INFO")
my_logger.addHandler(log_file_handler)
formatter = logging.Formatter('%(asctime)s - [%(filename)s-->line:%(lineno)d] - %(levelname)s: %(message)s')
stream_handler.setFormatter(formatter)
log_file_handler.setFormatter(formatter)
return my_logger
以上就是如何理解python接口自動化之logging日志模塊的詳細內容,更多關于python 接口自動化 logging日志模塊的資料請關注腳本之家其它相關文章!
