0 背景
由于工作需要,利用spark完成機器學習。因此需要對spark集群進行操作。所以利用pycharm和pyspark遠程連接spark集群。這里記錄下遇到的問題及方法。
主要是參照下面的文獻完成相應的內(nèi)容,但是具體問題要具體分析。
1 方法
1.1 軟件配置
spark2.3.3, hadoop2.6, python3
1.2 spark配置
Spark集群的每個節(jié)點的Python版本必須保持一致。在每個節(jié)點的$SPARK_HOME/conf/spark-env.sh中添加一行:具體看你的安裝目錄。
export PYSPARK_PYTHON=/home/hadoop/anaconda2/bin/python3
此步驟就是將python添加到spark的配置中。
此時,在服務器命令行輸入pyspark時,可以正常進入spark。
1.3本地配置
1.3.1 首先將spark2.3.3從服務器拷貝到本地。
注意: 由于我集群安裝的是spark-2.3.3-bin-without-hadoop。但是拷貝到本地后,總是報錯Java gateway process… 。同時我將hadoop2.6,的包也從服務器拷貝到本地加載到程序中,同樣報錯。
最后,直接從spark的官網(wǎng)中,下載了spark-2.3.3-bin-hadoop2.6,這回就可以了。
pyspark的版本與spark的版本最好對應。比如pyspark2.3.3,spark2.3.3
# os.environ['SPARK_HOME'] = r"F:\big_data\spark-2.3.3-bin-without-hadoop"(無用)
os.environ['SPARK_HOME'] = r"F:\big_data\spark-2.3.3-bin-hadoop2.6"(有用)
# os.environ["HADOOP_HOME"] = r"F:\big_data\hadoop-2.6.5"(無用)
# os.environ['JAVA_HOME'] = r"F:\Java\jdk1.8.0_144"(無用)
1.3.2
C:\Windows\System32….\hosts(Windows機器)中加入Spark集群Master節(jié)點的IP與主機名的映射。需要管理員權(quán)限修改。

其中的spark_cluster就是對于Master的IP的映射名。(直接寫IP一樣可以,映射名是為了方便)
1.3.3
添加剛剛下載解壓好的spark的python目錄到pycharm的project structure
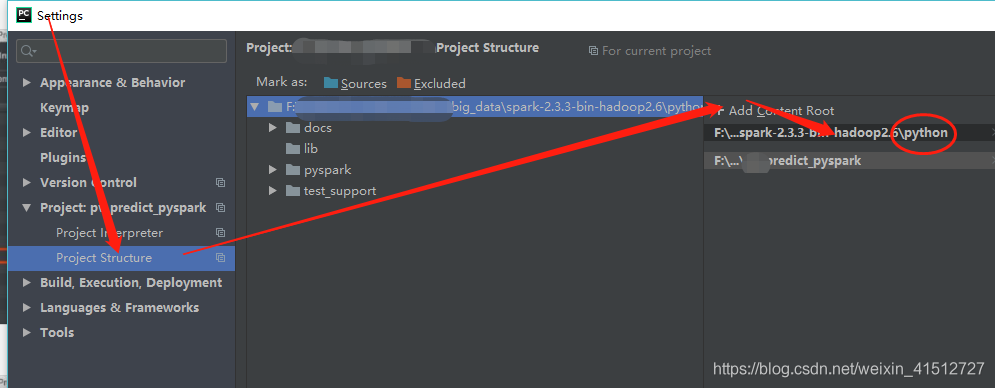
1.3.4
新建py文件,編輯Edit Configurations添加SPARK_HOME變量
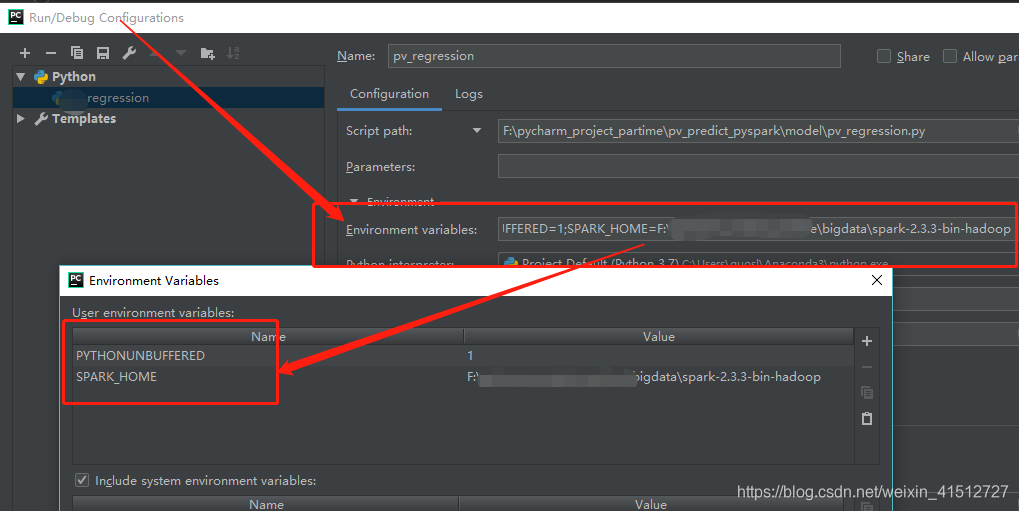
注意: 在實際中,這個不添加好像也可以。只需要在程序中加載了spark_home.比如os.envion(…spark…)
2 測試
import os
from pyspark import SparkContext
from pyspark import SparkConf
# os.environ['SPARK_HOME'] = r"F:\big_data\spark-2.3.3-bin-without-hadoop"
os.environ['SPARK_HOME'] = r"F:\big_data\spark-2.3.3-bin-hadoop2.6"
# os.environ["HADOOP_HOME"] = r"F:\big_data\hadoop-2.6.5"
# os.environ['JAVA_HOME'] = r"F:\Java\jdk1.8.0_144"
print(0)
conf = SparkConf().setMaster("spark://spark_cluster:7077").setAppName("test")
sc = SparkContext(conf=conf)
print(1)
logData = sc.textFile("file:///opt/spark-2.3.3-bin-without-hadoop/README.md").cache()
print(2)
print("num of a",logData)
sc.stop()

3 參考
PyCharm+PySpark遠程調(diào)試的環(huán)境配置的方法
Spark下:Java gateway process exited before sending the driver its port number等問題
估計每個人遇到的問題不一樣,但是大同小異,具體問題具體分析。
到此這篇關于pycharm利用pyspark遠程連接spark集群的實現(xiàn)的文章就介紹到這了,更多相關pyspark遠程連接spark集群內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- pyspark 讀取csv文件創(chuàng)建DataFrame的兩種方法
- pyspark.sql.DataFrame與pandas.DataFrame之間的相互轉(zhuǎn)換實例
- pyspark給dataframe增加新的一列的實現(xiàn)示例
- PyCharm搭建Spark開發(fā)環(huán)境實現(xiàn)第一個pyspark程序
- Linux下遠程連接Jupyter+pyspark部署教程
- pycharm編寫spark程序,導入pyspark包的3中實現(xiàn)方法
- 如何將PySpark導入Python的放實現(xiàn)(2種)
- pyspark對Mysql數(shù)據(jù)庫進行讀寫的實現(xiàn)
- pyspark創(chuàng)建DataFrame的幾種方法
- windowns使用PySpark環(huán)境配置和基本操作
