optim 的基本使用
for do:
1. 計算loss
2. 清空梯度
3. 反傳梯度
4. 更新參數
optim的完整流程
cifiron = nn.MSELoss()
optimiter = torch.optim.SGD(net.parameters(),lr=0.01,momentum=0.9)
for i in range(iters):
out = net(inputs)
loss = cifiron(out,label)
optimiter.zero_grad() # 清空之前保留的梯度信息
loss.backward() # 將mini_batch 的loss 信息反傳回去
optimiter.step() # 根據 optim參數 和 梯度 更新參數 w.data -= w.grad*lr
網絡參數 默認使用統一的 優化器參數
如下設置 網絡全局參數 使用統一的優化器參數
optimiter = torch.optim.Adam(net.parameters(),lr=0.01,momentum=0.9)
如下設置將optimizer的可更新參數分為不同的三組,每組使用不同的策略
optimizer = torch.optim.SGD([
{'params': other_params},
{'params': first_params, 'lr': 0.01*args.learning_rate},
{'params': second_params, 'weight_decay': args.weight_decay}],
lr=args.learning_rate,
momentum=args.momentum,
)
我們追溯一下構造Optim的過程
為了更好的看整個過程,去掉了很多 條件判斷 語句,如 >0 0
# 首先是 子類Adam 的構造函數
class Adam(Optimizer):
def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8,
weight_decay=0, amsgrad=False):
defaults = dict(lr=lr, betas=betas, eps=eps,
weight_decay=weight_decay, amsgrad=amsgrad)
'''
構造了 參數params,可以有兩種傳入格式,分別對應
1. 全局參數 net.parameters()
2. 不同參數組 [{'params': other_params},
{'params': first_params, 'lr': 0.1*lr}]
和 全局> 的默認參數字典defaults
'''
# 然后調用 父類Optimizer 的構造函數
super(Adam, self).__init__(params, defaults)
# 看一下 Optim類的構造函數 只有兩個輸入 params 和 defaults
class Optimizer(object):
def __init__(self, params, defaults):
torch._C._log_api_usage_once("python.optimizer")
self.defaults = defaults
self.state = defaultdict(dict)
self.param_groups = [] # 自身構造的參數組,每個組使用一套參數
param_groups = list(params)
if len(param_groups) == 0:
raise ValueError("optimizer got an empty parameter list")
# 如果傳入的net.parameters(),將其轉換為 字典
if not isinstance(param_groups[0], dict):
param_groups = [{'params': param_groups}]
for param_group in param_groups:
#add_param_group 這個函數,主要是處理一下每個參數組其它屬性參數(lr,eps)
self.add_param_group(param_group)
def add_param_group(self, param_group):
# 如果當前 參數組中 不存在默認參數的設置,則使用全局參數屬性進行覆蓋
'''
[{'params': other_params},
{'params': first_params, 'lr': 0.1*lr}]
如第一個參數組 只提供了參數列表,沒有其它的參數屬性,則使用全局屬性覆蓋,第二個參數組 則設置了自身的lr為全局 (0.1*lr)
'''
for name, default in self.defaults.items():
if default is required and name not in param_group:
raise ValueError("parameter group didn't specify a value of required optimization parameter " +
name)
else:
param_group.setdefault(name, default)
# 判斷 是否有一個參數 出現在不同的參數組中,否則會報錯
param_set = set()
for group in self.param_groups:
param_set.update(set(group['params']))
if not param_set.isdisjoint(set(param_group['params'])):
raise ValueError("some parameters appear in more than one parameter group")
# 然后 更新自身的參數組中
self.param_groups.append(param_group)
網絡更新的過程(Step)
具體實現
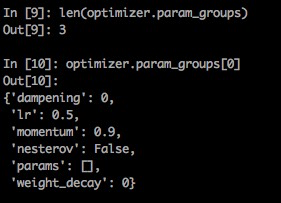
1、我們拿SGD舉例,首先看一下,optim.step 更新函數的具體操作
2、可見,for group in self.param_groups,optim中存在一個param_groups的東西,其實它就是我們傳進去的param_list,比如我們上面傳進去一個長度為3的param_list,那么 len(optimizer.param_groups)==3 , 而每一個 group 又是一個dict, 其中包含了 每組參數所需的必要參數 optimizer.param_groups:長度2的list,optimizer.param_groups[0]:長度6的字典
3、然后取回每組 所需更新的參數for p in group['params'] ,根據設置 計算其 正則化 及 動量累積,然后更新參數 w.data -= w.grad*lr
def step(self, closure=None):
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
# 本組參數更新所必需的 參數設置
weight_decay = group['weight_decay']
momentum = group['momentum']
dampening = group['dampening']
nesterov = group['nesterov']
for p in group['params']: # 本組所有需要更新的參數 params
if p.grad is None: # 如果沒有梯度 則直接下一步
continue
d_p = p.grad.data
# 正則化 及 動量累積 操作
if weight_decay != 0:
d_p.add_(weight_decay, p.data)
if momentum != 0:
param_state = self.state[p]
if 'momentum_buffer' not in param_state:
buf = param_state['momentum_buffer'] = torch.clone(d_p).detach()
else:
buf = param_state['momentum_buffer']
buf.mul_(momentum).add_(1 - dampening, d_p)
if nesterov:
d_p = d_p.add(momentum, buf)
else:
d_p = buf
# 當前組 學習參數 更新 w.data -= w.grad*lr
p.data.add_(-group['lr'], d_p)
return loss
如何獲取指定參數
1、可以使用model.named_parameters() 取回所有參數,然后設定自己的篩選規則,將參數分組
2、取回分組參數的id map(id, weight_params_list)
3、取回剩余分特殊處置參數的id other_params = list(filter(lambda p: id(p) not in params_id, all_params))
all_params = model.parameters()
weight_params = []
quant_params = []
# 根據自己的篩選規則 將所有網絡參數進行分組
for pname, p in model.named_parameters():
if any([pname.endswith(k) for k in ['cw', 'dw', 'cx', 'dx', 'lamb']]):
quant_params += [p]
elif ('conv' or 'fc' in pname and 'weight' in pname):
weight_params += [p]
# 取回分組參數的id
params_id = list(map(id, weight_params)) + list(map(id, quant_params))
# 取回剩余分特殊處置參數的id
other_params = list(filter(lambda p: id(p) not in params_id, all_params))
# 構建不同學習參數的優化器
optimizer = torch.optim.SGD([
{'params': other_params},
{'params': quant_params, 'lr': 0.1*args.learning_rate},
{'params': weight_params, 'weight_decay': args.weight_decay}],
lr=args.learning_rate,
momentum=args.momentum,
)
獲取指定層的參數id
# # 以層為單位,為不同層指定不同的學習率
# ## 提取指定層對象
special_layers = t.nn.ModuleList([net.classifiter[0], net.classifiter[3]])
# ## 獲取指定層參數id
special_layers_params = list(map(id, special_layers.parameters()))
print(special_layers_params)
# ## 獲取非指定層的參數id
base_params = filter(lambda p: id(p) not in special_layers_params, net.parameters())
optimizer = t.optim.SGD([{'params': base_params},
{'params': special_layers.parameters(), 'lr': 0.01}], lr=0.001)
補充:【pytorch】篩選凍結部分網絡層參數同時設置有參數組的時候該怎么辦?
在進行神經網絡訓練的時候,常常需要凍結部分網絡層的參數,不想讓他們回傳梯度。這個其實很簡單,其他博客里教程很多~
那如果,我想對不同的參數設置不同的學習率呢?這個其他博客也有,設置參數組就好啦,優化器就可以分別設置學習率了。
那么,如果我同時想凍結參數和設置不同的學習率呢?是不是把兩個人給合起來就好了?好的那你試試吧看看行不行。
我最近工作中需要對two-stream的其中的一只進行凍結,并且設置不同的學習率。下面記錄一下我踩的坑。
首先,我們需要篩選所需要的層。我想要把名字里含有特定符號的層給篩選出來。在這里我要強烈推薦這個利用正則表達式來進行字符串篩選的方式!
import re
str = 'assdffggggg'
word = 'a'
a = [m.start() for m in re.finditer(word, str)]
這里的a是一個列表,它里面包含的是word在字符串str中所在的位置,這里自然就是0了。
在進行網絡層參數凍結的時候,網上會有兩種for循環:
for name, p in net.named_parameters():
for p in net.parameters():
這兩種都行,但是對于需要對特定名稱的網絡層進行凍結的時候就需要選第一個啦,因為我們需要用到參數的"name"屬性。
下面就是簡單的篩選和凍結,和其他教程里面的一樣:
word1 = 'seg'
for name, p in decode_net.named_parameters():
str = name
a = [m.start() for m in re.finditer(word1, str)]
if a: #列表a不為空的話就設置回傳的標識為False
p.requires_grad = False
else:
p.requires_grad = True
#if p.requires_grad:#這個判斷可以打印出需要回傳梯度的層的名稱
#print(name)
到這里我們就完成了網絡參數的凍結。我真正想要分享的在下面這個部分!!看了四天的大坑!
凍結部分層的參數之后,我們在使用優化器的時候就需要先把不需要回傳梯度的參數給過濾掉,如果不過濾就會報錯,優化器就會抱怨你怎么把不需要優化的參數給放進去了balabala的。所以我們加一個:
optimizer = optim.SGD(
filter(lambda p: p.requires_grad, net.parameters()), # 記住一定要加上filter(),不然會報錯
lr=0.01, weight_decay=1e-5, momentum=0.9)
到這里也沒有任何的問題。但是!我做分割的encode部分是pre-trained的resnet,這部分我的學習率不想和我decode的部分一樣啊!不然我用pre-trained的有啥用??so,我劃分了一個參數組:
base_params_id = list(map(id, net.conv1.parameters())) + list(map(id,net.bn1.parameters()))+\
list(map(id,net.layer1.parameters())) + list(map(id,net.layer2.parameters())) \
+ list(map(id,net.layer3.parameters())) + list(map(id,net.layer4.parameters()))
new_params = filter(lambda p: id(p) not in base_params_id , net.parameters())
base_params = filter(lambda p: id(p) in base_params_id, net.parameters())
好了,那么這個時候,如果我先不考慮過濾的話,優化器的設置應該是這樣的:
optimizerG = optim.SGD([{'params': base_params, 'lr': 1e-4},
{'params': new_params}], lr = opt.lr, momentum = 0.9, weight_decay=0.0005)
那么,按照百度出來的教程,我下一步要加上過濾器的話是不是應該:
optimizerG = optim.SGD( filter(lambda p: p.requires_grad, net.parameters()),
[{'params': base_params, 'lr': 1e-4},
{'params': new_params}], lr = opt.lr, momentum = 0.9, weight_decay=0.0005)
好的看起來沒有任何的問題,但是運行的時候就開始報錯:

就是這里!!一個剛開始用pytorch的我!什么都不懂!然后我看了四天!!最后查閱了官方文檔才知道為什么報錯。以后看到這種提示init函數錯誤的都要記得去官方doc上看說明。

這里其實寫的很清楚了,SGD優化器每個位置都是什么參數。到這里應該已經能看出來哪里有問題了吧?
optimizerG = optim.SGD( filter(lambda p: p.requires_grad, net.parameters()),
[{'params': base_params, 'lr': 1e-4},
{'params': new_params}], lr = opt.lr, momentum = 0.9, weight_decay=0.0005)
看我的SGD函數每個參數的位置,第一個放的是過濾器,第二個是參數組,然后是lr,對比官方的定義:第一個參數,第二個是lr等等。
所以錯誤就在這里!我第一個位置放了過濾器!第二個位置是參數組!所以他把過濾器當作參數,參數組當作學習率,然后就報錯說lr接受到很多個值……
仔細去看其他博客的教程,基本是只有分參數組的優化器設置和凍結層了之后優化器的設置。沒有又分參數組又凍結部分層參數的設置。所以設置過濾器把不需要優化的參數給踢掉這個步驟還是要的,但是在現在這種情況下不應該放在SGD里!
new_params = filter(lambda p: id(p) not in base_params_id and p.requires_grad,\
netG.parameters())
base_params = filter(lambda p: id(p) in base_params_id,
netG.parameters())
應該在劃分參數組的時候就添加過濾器,將不需要回傳梯度的參數過濾掉(這里就是直接篩選p.requires_grad即可)。如此便可以順利凍結參數并且設置參數組啦!
以上為個人經驗,希望能給大家一個參考,也希望大家多多支持腳本之家。如有錯誤或未考慮完全的地方,望不吝賜教。
您可能感興趣的文章:- 在pytorch中動態調整優化器的學習率方式
- 淺談Pytorch torch.optim優化器個性化的使用
- pytorch 實現在一個優化器中設置多個網絡參數的例子
- 詳解PyTorch批訓練及優化器比較
- pytorch中的優化器optimizer.param_groups用法
