目錄
- 常見(jiàn)的協(xié)議
- 常見(jiàn)的請(qǐng)求方式
- 常見(jiàn)的請(qǐng)求頭參數(shù):
- 常見(jiàn)的相應(yīng)狀態(tài)碼
- HTTP的請(qǐng)求相應(yīng)過(guò)程
- 使用瀏覽器進(jìn)行網(wǎng)站分析
- session 與cookie
常見(jiàn)的協(xié)議
http和https
http協(xié)議:
超文本傳輸協(xié)議,是一個(gè)發(fā)布和接受HTML頁(yè)面的方法,端口是80
https 協(xié)議:http協(xié)議的加密版本,在HTTP下加上了ssl層,端口是443
下面訪問(wèn)的是美團(tuán)的官網(wǎng):
可以看到端口是443
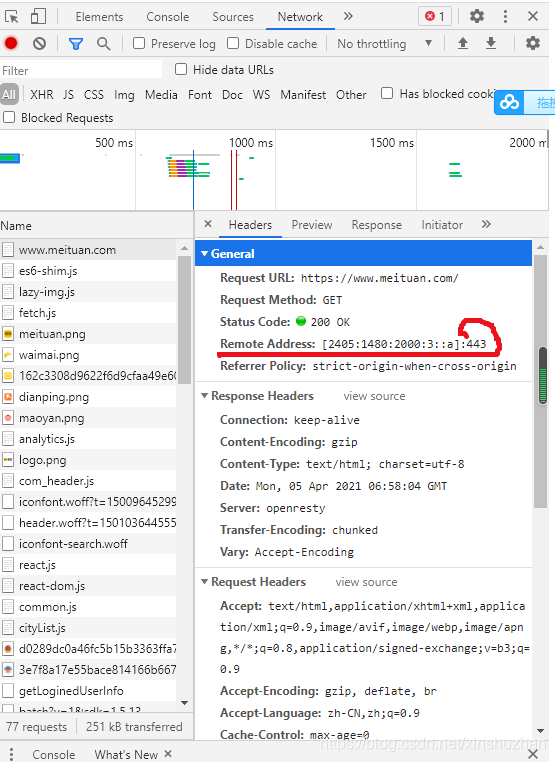
URL和RUI
常見(jiàn)的請(qǐng)求方式
http協(xié)議規(guī)定了瀏覽器與服務(wù)器進(jìn)行數(shù)據(jù)交互過(guò)程中必須要選擇一種交互方式
在http協(xié)議中定義了8中請(qǐng)求方式,常見(jiàn)的是get和post請(qǐng)求
get請(qǐng)求: 一般只從服務(wù)器獲取數(shù)據(jù)下來(lái),并不會(huì)對(duì)服務(wù)器資源產(chǎn)生任何的影響。
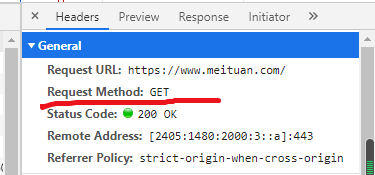
請(qǐng)求的時(shí)候關(guān)注:
url請(qǐng)求方式請(qǐng)求頭
post請(qǐng)求: 向服務(wù)器發(fā)送數(shù)據(jù)(登陸),上傳文件等,會(huì)對(duì)服務(wù)器資源產(chǎn)生影響的時(shí)候,會(huì)使用post請(qǐng)求。
不過(guò)有些網(wǎng)站做了反爬蟲(chóng)機(jī)制,你去查看信息,也是使用post請(qǐng)求,所以我們寫(xiě)爬蟲(chóng)的時(shí)候,一定要分析網(wǎng)站。
常見(jiàn)的請(qǐng)求頭參數(shù):
http協(xié)議中,向服務(wù)器發(fā)送一個(gè)請(qǐng)求,數(shù)據(jù)分為三部分:
- 把數(shù)據(jù)放在url中
- 數(shù)據(jù)放在body中,(post請(qǐng)求)
- 數(shù)據(jù)放在head中
常見(jiàn)的請(qǐng)求頭參數(shù):
- user-agent :瀏覽器名稱
- referer: 當(dāng)前這個(gè)請(qǐng)求從哪個(gè)url過(guò)來(lái)的
- cookie:http 協(xié)議是無(wú)狀態(tài)的,也就是一個(gè)人發(fā)送了兩次請(qǐng)求,服務(wù)器沒(méi)有能力知道這兩個(gè)請(qǐng)求是否來(lái)自同一個(gè)人。

常見(jiàn)的相應(yīng)狀態(tài)碼
- 200 請(qǐng)求正常,服務(wù)器正常返回?cái)?shù)據(jù)
- 301 永久重定向
- 404 請(qǐng)求的url在服務(wù)器上找不到
- 418 發(fā)送請(qǐng)求遇到服務(wù)器端的反爬蟲(chóng),服務(wù)器拒絕相應(yīng)數(shù)據(jù)
- 500 服務(wù)器內(nèi)部錯(cuò)誤,可能是服務(wù)器出現(xiàn)了bug
HTTP的請(qǐng)求相應(yīng)過(guò)程

使用瀏覽器進(jìn)行網(wǎng)站分析
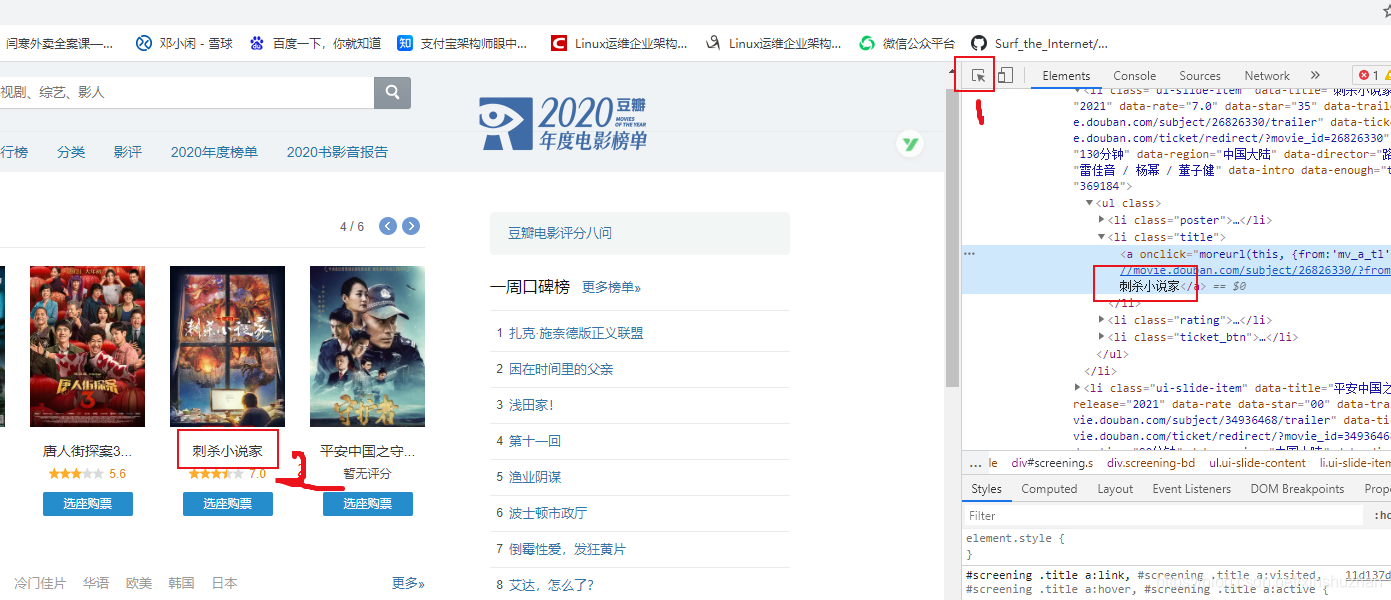
我們要分析的網(wǎng)站為: movie.douban.com

- Elements: 用于分析網(wǎng)站的結(jié)構(gòu)
在頁(yè)面上的呈現(xiàn)的內(nèi)容,在Elements都會(huì)有相應(yīng)的元素。
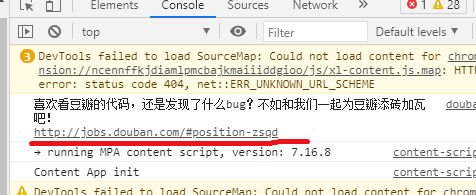
- Console: 這里會(huì)打印招聘信息,警告等等。
- Sources
- Network : 在顯示頁(yè)面的時(shí)候,產(chǎn)生的所有請(qǐng)求
headers 頭部信息
session 與cookie
session代表的是服務(wù)器和瀏覽器的一次會(huì)話過(guò)程
session 是一種服務(wù)器端的機(jī)制,用來(lái)存儲(chǔ)特定用戶的會(huì)話所需要的信息,保存在內(nèi)存,緩存,或者數(shù)據(jù)庫(kù)中。
cookie
cooke是由服務(wù)器端生成后發(fā)送給客戶端,cookie是保存在客戶端的
cookie原理:
1) 創(chuàng)建cookie
2) 設(shè)置存儲(chǔ)cookie
3) 發(fā)送cookie
4) 讀取cookie
到此這篇關(guān)于學(xué)習(xí)Python爬蟲(chóng)前,需要先掌握哪些知識(shí)內(nèi)容的文章就介紹到這了,更多相關(guān)學(xué)習(xí)Python爬蟲(chóng)掌握知識(shí)內(nèi)容請(qǐng)搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- 利用Python網(wǎng)絡(luò)爬蟲(chóng)爬取各大音樂(lè)評(píng)論的代碼
- 使用Selenium實(shí)現(xiàn)微博爬蟲(chóng)(預(yù)登錄、展開(kāi)全文、翻頁(yè))
- 一文讀懂python Scrapy爬蟲(chóng)框架
- Python爬蟲(chóng)分析微博熱搜關(guān)鍵詞的實(shí)現(xiàn)代碼
- 用python爬蟲(chóng)爬取CSDN博主信息
