目錄
- 基本思路
- 該腳本所需要的一些庫
- 獲取掃描目標(biāo)
- 對網(wǎng)頁進(jìn)行郵箱地址爬取(100條)
- 通過錨點進(jìn)入下一網(wǎng)頁繼續(xù)搜索
- 完整代碼
- 實驗………………
信息收集是進(jìn)行滲透測試的關(guān)鍵部分,掌握大量的信息對于攻擊者來說是一件非常重要的事情,比如,我們知道一個服務(wù)器的版本信息,我們就可以利用該服務(wù)器框架的相關(guān)漏洞對該服務(wù)器進(jìn)行測試。那么如果我們掌握了該服務(wù)器的管理員的郵箱地址,我們就可以展開一個釣魚攻擊。所以,對web站點進(jìn)行郵箱掃描,是進(jìn)行釣魚攻擊的一種前提條件。
下面,我們利用python腳本來實現(xiàn)一個web站點的郵箱掃描爬取。目的是在實現(xiàn)這個腳本的過程中對python進(jìn)行學(xué)習(xí)
最后有完整代碼
基本思路
- 我們向工具傳入目標(biāo)站點之后,首先要對輸入進(jìn)行一個基本的檢查和分析,因為我們會可能會傳入各種樣式的地址,比如http://www.xxxx.com/、http://www.xxxx.com/123/456/789.html等等,我們需要對其進(jìn)行簡單的拆分,以便于后面鏈接的爬取
- 通過requests庫爬取目標(biāo)地址的內(nèi)容,并且在內(nèi)容通過正則表達(dá)式中尋找郵箱地址
- 查找爬取的網(wǎng)站中的超鏈接,通過這些超鏈接我們就能進(jìn)入到該站點的另外一個頁面繼續(xù)尋找我們想要的郵箱地址。
- 開工:
該腳本所需要的一些庫
from bs4 import BeautifulSoup #BeautifulSoup最主要的功能是從網(wǎng)頁抓取數(shù)據(jù),Beautiful Soup自動將輸入文檔轉(zhuǎn)換為Unicode編碼
import requests #requests是python實現(xiàn)的最簡單易用的HTTP庫
import requests.exceptions
import urllib.parse
from collections import deque #deque 是一個雙端隊列, 如果要經(jīng)常從兩端append 的數(shù)據(jù), 選擇這個數(shù)據(jù)結(jié)構(gòu)就比較好了, 如果要實現(xiàn)隨機(jī)訪問,不建議用這個,請用列表.
import re #是一個正則表達(dá)式的庫
獲取掃描目標(biāo)
user_url=str(input('[+] Enter Target URL to Scan:'))
urls =deque([user_url]) #把目標(biāo)地址放入deque對象列表
scraped_urls= set()#set() 函數(shù)創(chuàng)建一個無序不重復(fù)元素集,可進(jìn)行關(guān)系測試,刪除重復(fù)數(shù)據(jù),還可以計算交集、差集、并集等。
emails = set()
對網(wǎng)頁進(jìn)行郵箱地址爬取(100條)
首先要對目標(biāo)地址進(jìn)行分析,拆分目標(biāo)地址的協(xié)議,域名以及路徑。然后利用requests的get方法訪問網(wǎng)頁,通過正則表達(dá)式過濾出是郵箱地址的內(nèi)容。'[a-z0-0.-+]+@[a-z0-9.-+]+.[a-z]+',符合郵箱格式的內(nèi)容就進(jìn)行收錄。
count=0
try:
while len(urls): #如果urls有長度的話進(jìn)行循環(huán)
count += 1 #添加計數(shù)器來記錄爬取鏈接的條數(shù)
if count ==101:
break
url = urls.popleft() #popleft()會刪除urls里左邊第一條數(shù)據(jù)并傳給url
scraped_urls.add(url)
parts = urllib.parse.urlsplit(url) # 打印 parts會顯示:SplitResult(scheme='http', netloc='www.baidu.com', path='', query='', fragment='')
base_url = '{0.scheme}://{0.netloc}'.format(parts)#scheme:協(xié)議;netloc:域名
path = url[:url.rfind('/')+1] if '/' in parts.path else url#提取路徑
print('[%d] Processing %s' % (count,url))
try:
head = {'User-Agent':"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11"}
response = requests.get(url,headers = head)
except(requests.exceptions.MissingSchema,requests.exceptions.ConnectionError):
continue
new_emails = set(re.findall(r'[a-z0-0\.\-+_]+@[a-z0-9\.\-+_]+\.[a-z]+', response.text ,re.I))#通過正則表達(dá)式從獲取的網(wǎng)頁中提取郵箱,re.I表示忽略大小寫
emails.update(new_emails)#將獲取的郵箱地址存在emalis中。
通過錨點進(jìn)入下一網(wǎng)頁繼續(xù)搜索
soup = BeautifulSoup(response.text, features='lxml')
for anchor in soup.find_all('a'): #尋找錨點。在html中,a>標(biāo)簽代表一個超鏈接,herf屬性就是鏈接地址
link = anchor.attrs['href'] if 'href' in anchor.attrs else '' #如果,我們找到一個超鏈接標(biāo)簽,并且該標(biāo)簽有herf屬性,那么herf后面的地址就是我們需要錨點鏈接。
if link.startswith('/'):#如果該鏈接以/開頭,那它只是一個路徑,我們就需要加上協(xié)議和域名,base_url就是剛才分離出來的協(xié)議+域名
link = base_url + link
elif not link.startswith('http'):#如果不是以/和http開頭的話,就要加上路徑。
link =path + link
if not link in urls and not link in scraped_urls:#如果該鏈接在之前沒還有被收錄的話,就把該鏈接進(jìn)行收錄。
urls.append(link)
except KeyboardInterrupt:
print('[+] Closing')
for mail in emails:
print(mail)
完整代碼
from bs4 import BeautifulSoup
import requests
import requests.exceptions
import urllib.parse
from collections import deque
import re
user_url=str(input('[+] Enter Target URL to Scan:'))
urls =deque([user_url])
scraped_urls= set()
emails = set()
count=0
try:
while len(urls):
count += 1
if count ==100:
break
url = urls.popleft()
scraped_urls.add(url)
parts = urllib.parse.urlsplit(url)
base_url = '{0.scheme}://{0.netloc}'.format(parts)
path = url[:url.rfind('/')+1] if '/' in parts.path else url
print('[%d] Processing %s' % (count,url))
try:
head = {'User-Agent':"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11"}
response = requests.get(url,headers = head)
except(requests.exceptions.MissingSchema,requests.exceptions.ConnectionError):
continue
new_emails = set(re.findall(r'[a-z0-0\.\-+_]+@[a-z0-9\.\-+_]+\.[a-z]+', response.text ,re.I))
emails.update(new_emails)
soup = BeautifulSoup(response.text, features='lxml')
for anchor in soup.find_all('a'):
link = anchor.attrs['href'] if 'href' in anchor.attrs else ''
if link.startswith('/'):
link = base_url + link
elif not link.startswith('http'):
link =path + link
if not link in urls and not link in scraped_urls:
urls.append(link)
except KeyboardInterrupt:
print('[+] Closing')
for mail in emails:
print(mail)
實驗………………
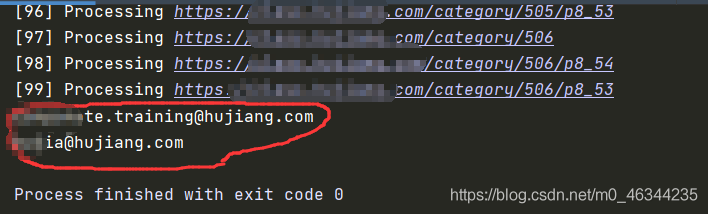
以上就是python實現(xiàn)web郵箱掃描的示例(附源碼)的詳細(xì)內(nèi)容,更多關(guān)于python web郵箱掃描的資料請關(guān)注腳本之家其它相關(guān)文章!
您可能感興趣的文章:- Python使用turtle庫繪制小豬佩奇(實例代碼)
- 啥是佩奇?使用Python自動繪畫小豬佩奇的代碼實例
- 使用python畫個小豬佩奇的示例代碼
- python 制作手機(jī)歸屬地查詢工具(附源碼)
- python matplotlib工具欄源碼探析三之添加、刪除自定義工具項的案例詳解
- python wsgiref源碼解析
- python 制作網(wǎng)站篩選工具(附源碼)
- Python黑魔法遠(yuǎn)程控制開機(jī)的實例
