1. 新建項目
在命令行窗口下輸入scrapy startproject scrapytest, 如下
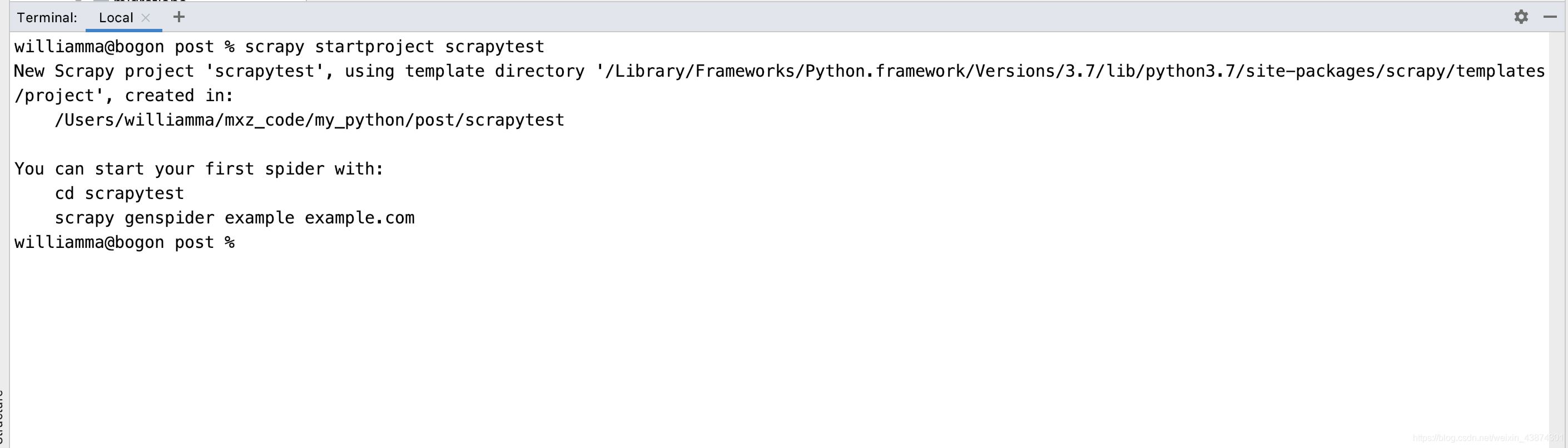
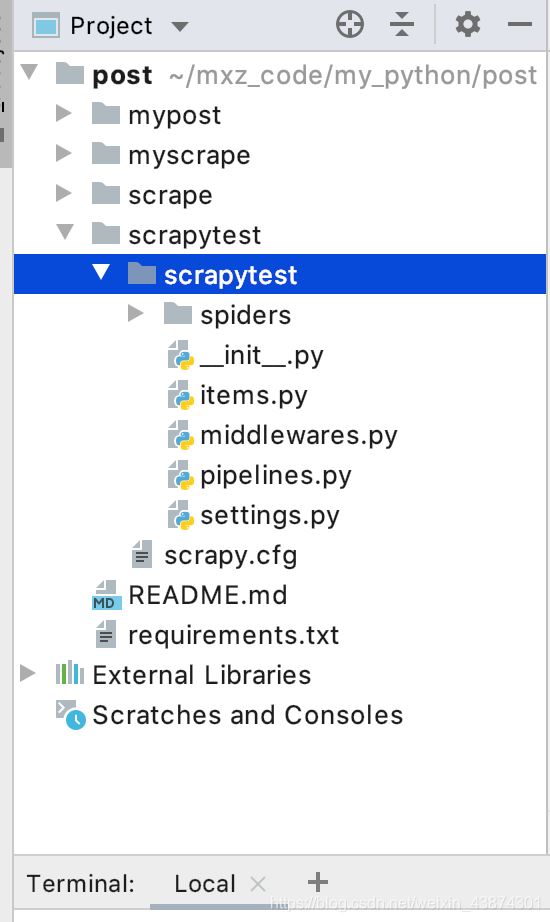
然后就自動創建了相應的文件,如下
2. 修改itmes.py文件
打開scrapy框架自動創建的items.py文件,如下
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ScrapytestItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
編寫里面的代碼,確定我要獲取的信息,比如新聞標題,url,時間,來源,來源的url,新聞的內容等
class ScrapytestItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
timestamp = scrapy.Field()
category = scrapy.Field()
content = scrapy.Field()
url = scrapy.Field()
pass
3. 定義spider,創建一個爬蟲模板
3.1 創建crawl爬蟲模板
在命令行窗口下面 創建一個crawl爬蟲模板(注意在文件的根目錄下面,指令檢查別輸入錯誤,-t 表示使用后面的crawl模板),會在spider文件夾生成一個news163.py文件
scrapy genspider -t crawl codingce news.163.com
然后看一下這個‘crawl'模板和一般的模板有什么區別,多了鏈接提取器還有一些爬蟲規則,這樣就有利于我們做一些深度信息的爬取
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class CodingceSpider(CrawlSpider):
name = 'codingce'
allowed_domains = ['163.com']
start_urls = ['http://news.163.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = {}
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
return item
3.2 補充知識:selectors選擇器
支持xpath和css,xpath語法如下
/html/head/title
/html/head/title/text()
//td (深度提取的話就是兩個/)
//div[@class=‘mine']
3.3. 分析網頁內容
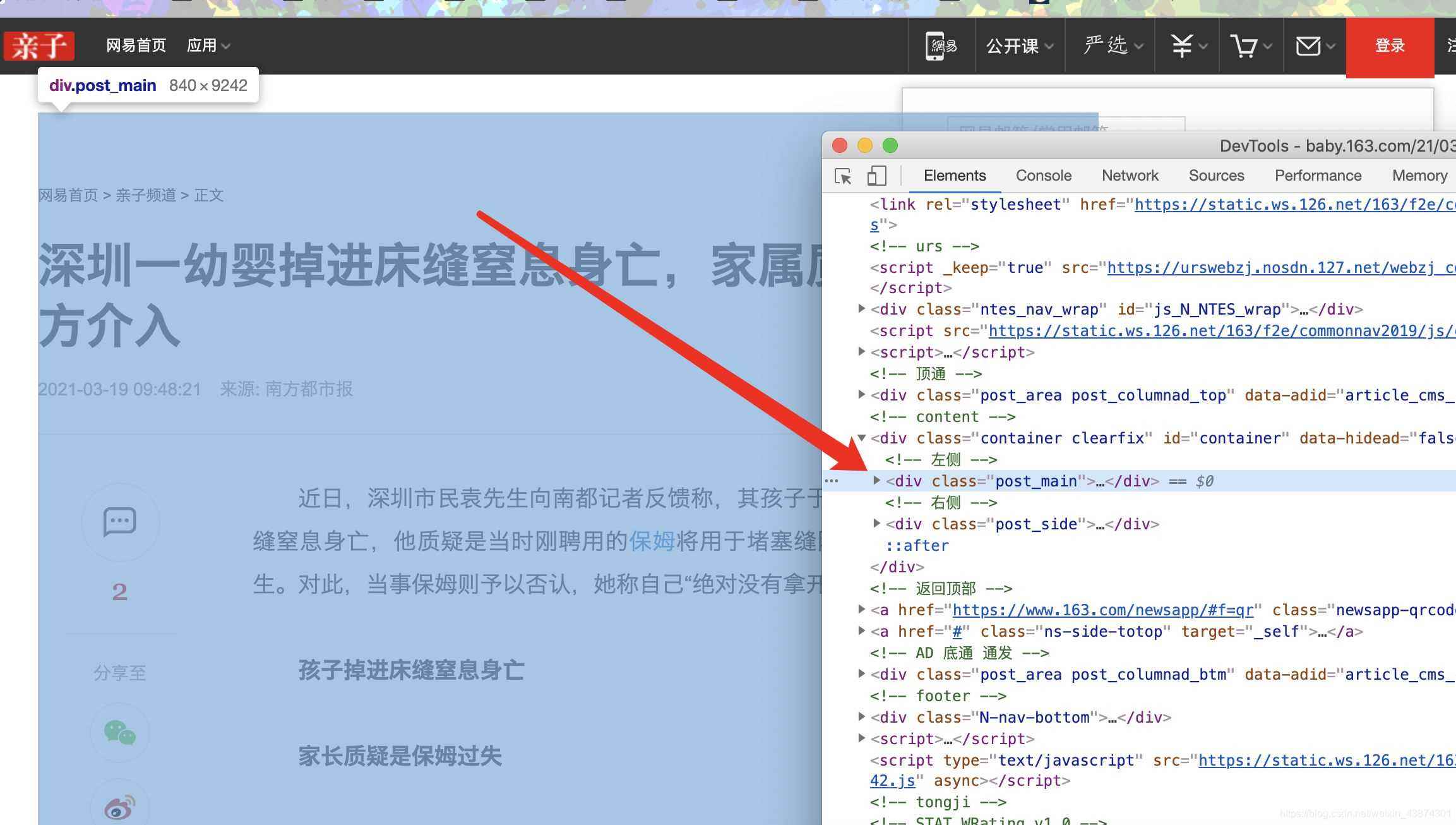
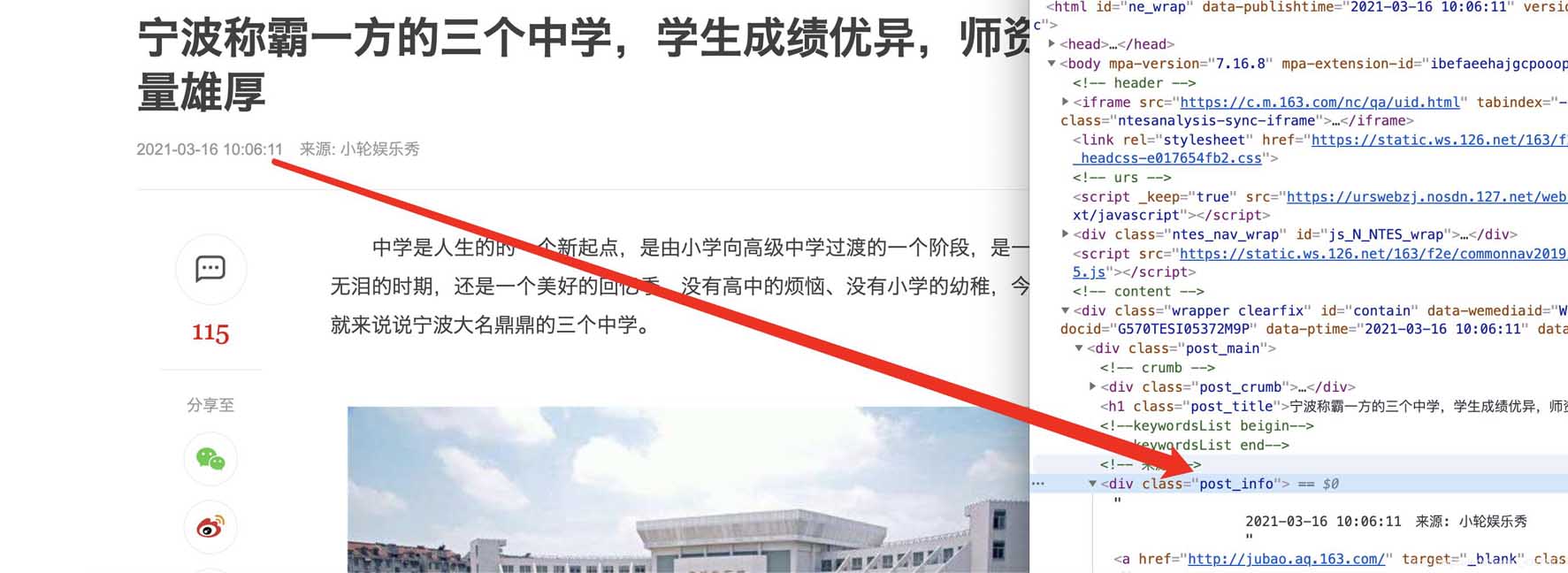
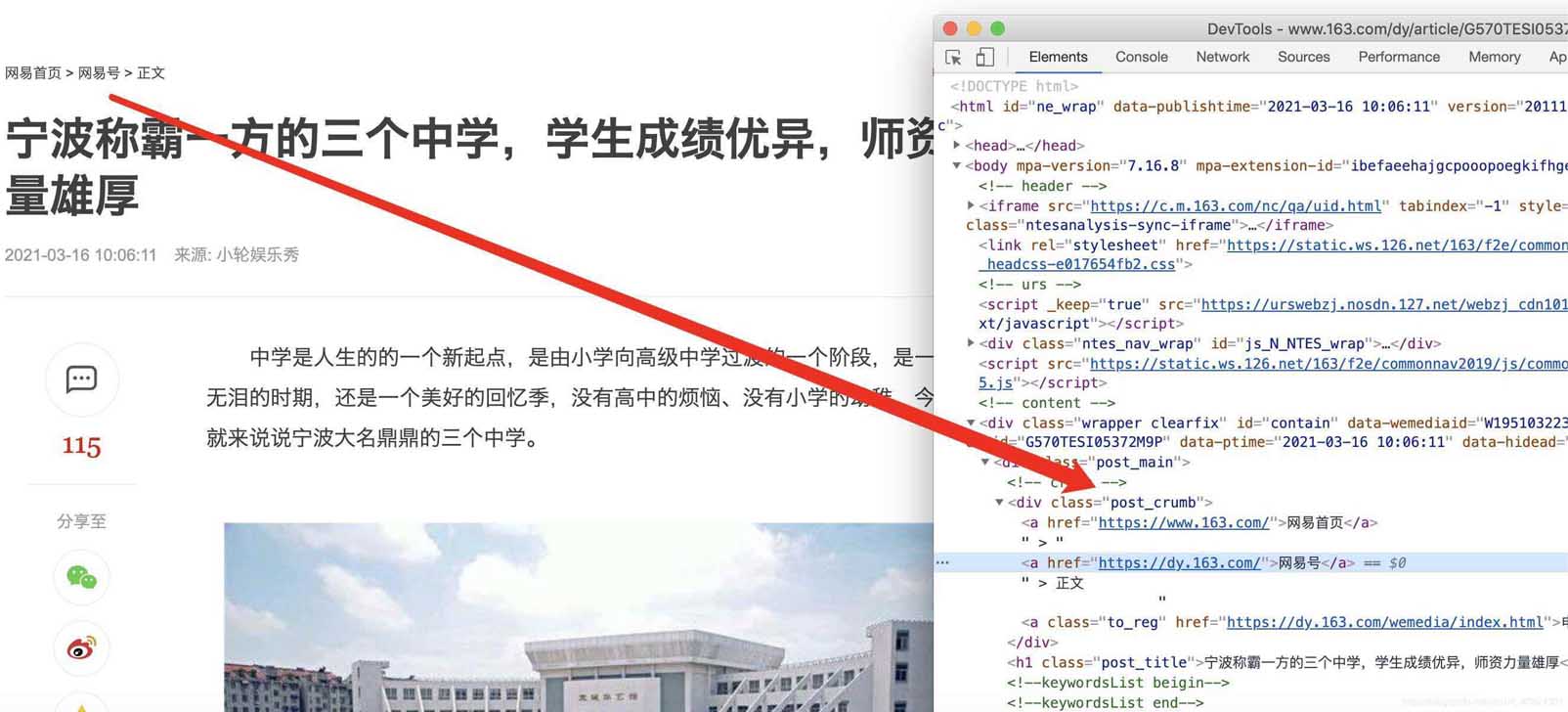
在谷歌chrome瀏覽器下,打在網頁新聞的網站,選擇查看源代碼,確認我們可以獲取到itmes.py文件的內容(其實那里面的要獲取的就是查看了網頁源代碼之后確定可以獲取的)
確認標題、時間、url、來源url和內容可以通過檢查和標簽對應上,比如正文部分
主體
標題
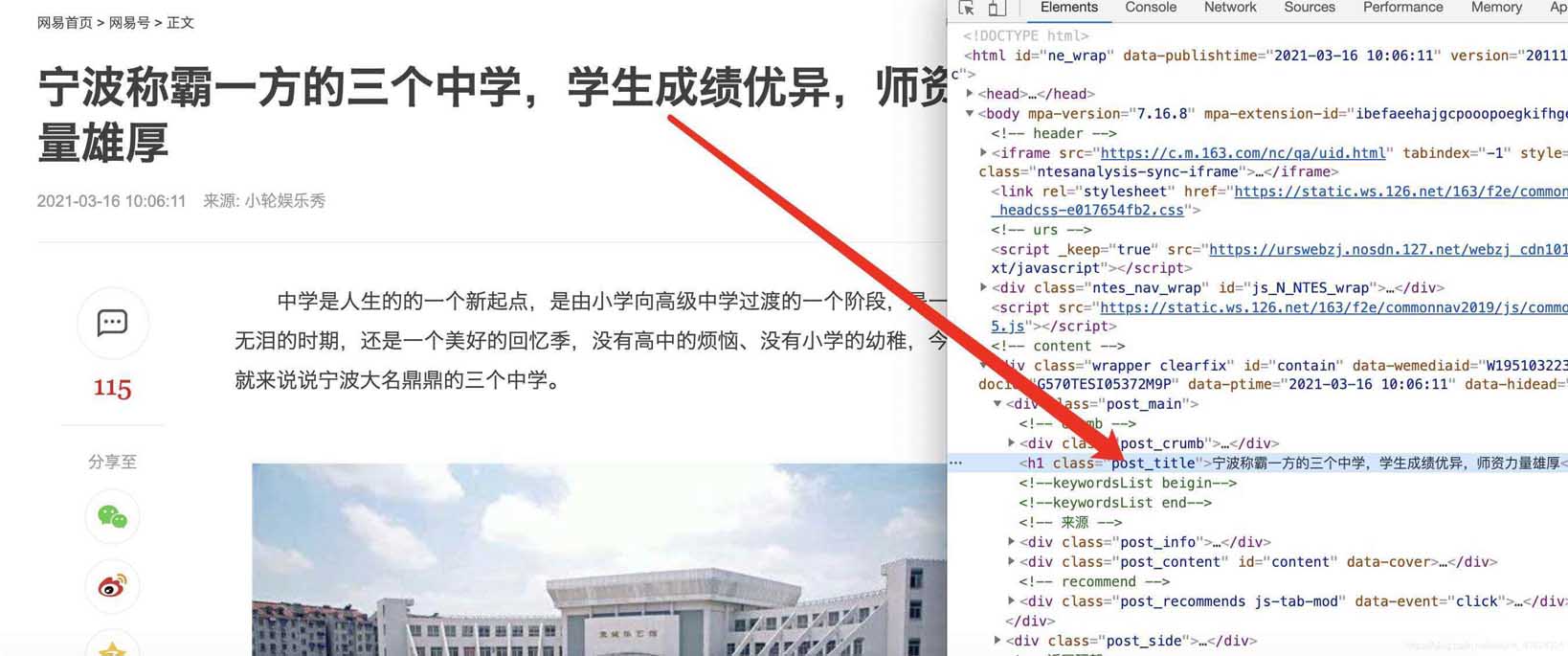
時間
分類
4. 修改spider下創建的爬蟲文件
4.1 導入包
打開創建的爬蟲模板,進行代碼的編寫,除了導入系統自動創建的三個庫,我們還需要導入news.items(這里就涉及到了包的概念了,最開始說的–init–.py文件存在說明這個文件夾就是一個包可以直接導入,不需要安裝)
注意:使用的類ExampleSpider一定要繼承自CrawlSpider,因為最開始我們創建的就是一個‘crawl'的爬蟲模板,對應上
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapytest.items import ScrapytestItem
class CodingceSpider(CrawlSpider):
name = 'codingce'
allowed_domains = ['163.com']
start_urls = ['http://news.163.com/']
rules = (
Rule(LinkExtractor(allow=r'.*\.163\.com/\d{2}/\d{4}/\d{2}/.*\.html'), callback='parse', follow=True),
)
def parse(self, response):
item = {}
content = 'br>'.join(response.css('.post_content p::text').getall())
if len(content) 100:
return
return item
Rule(LinkExtractor(allow=r'..163.com/\d{2}/\d{4}/\d{2}/..html'), callback=‘parse', follow=True), 其中第一個allow里面是書寫正則表達式的(也是我們核心要輸入的內容),第二個是回調函數,第三個表示是否允許深入
最終代碼
from datetime import datetime
import re
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapytest.items import ScrapytestItem
class CodingceSpider(CrawlSpider):
name = 'codingce'
allowed_domains = ['163.com']
start_urls = ['http://news.163.com/']
rules = (
Rule(LinkExtractor(allow=r'.*\.163\.com/\d{2}/\d{4}/\d{2}/.*\.html'), callback='parse', follow=True),
)
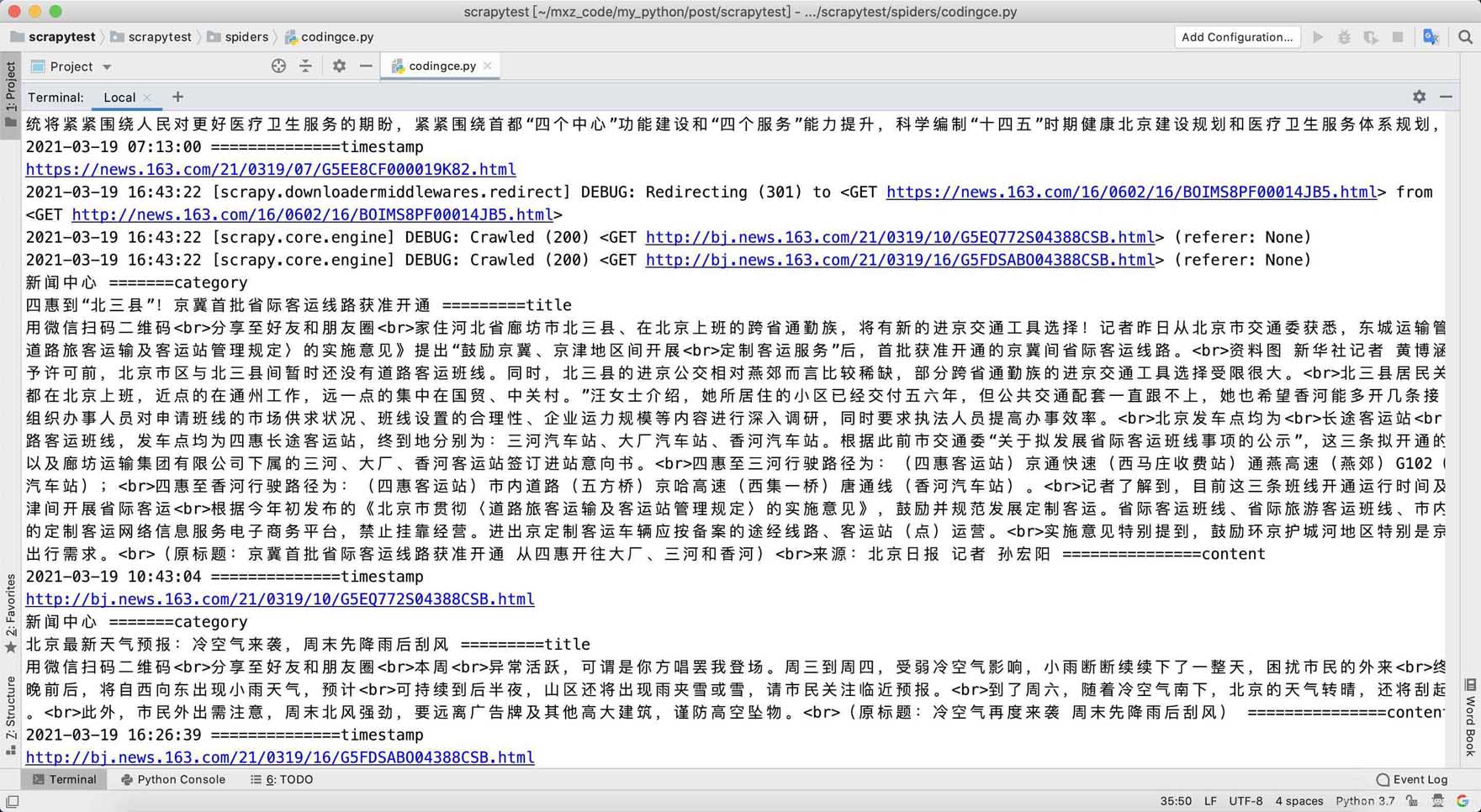
def parse(self, response):
item = {}
content = 'br>'.join(response.css('.post_content p::text').getall())
if len(content) 100:
return
title = response.css('h1::text').get()
category = response.css('.post_crumb a::text').getall()[-1]
print(category, "=======category")
time_text = response.css('.post_info::text').get()
timestamp_text = re.search(r'\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}', time_text).group()
timestamp = datetime.fromisoformat(timestamp_text)
print(title, "=========title")
print(content, "===============content")
print(timestamp, "==============timestamp")
print(response.url)
return item
到此這篇關于python實現Scrapy爬取網易新聞的文章就介紹到這了,更多相關python Scrapy爬取網易新聞內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Python爬蟲之教你利用Scrapy爬取圖片
- python基于scrapy爬取京東筆記本電腦數據并進行簡單處理和分析
- Scrapy+Selenium自動獲取cookie爬取網易云音樂個人喜愛歌單
- 如何在scrapy中集成selenium爬取網頁的方法
- 使用scrapy ImagesPipeline爬取圖片資源的示例代碼
- scrapy與selenium結合爬取數據(爬取動態網站)的示例代碼
- Python利用Scrapy框架爬取豆瓣電影示例
- Python scrapy增量爬取實例及實現過程解析
- Python爬蟲實戰之使用Scrapy爬取豆瓣圖片
