前言
反爬蟲(chóng)是網(wǎng)站為了維護(hù)自己的核心安全而采取的抑制爬蟲(chóng)的手段,反爬蟲(chóng)的手段有很多種,一般情況下除了百度等網(wǎng)站,反扒機(jī)制會(huì)常常更新以外。為了保持網(wǎng)站運(yùn)行的高效,網(wǎng)站采取的反扒機(jī)制并不是太多,今天分享幾個(gè)我在爬蟲(chóng)過(guò)程中遇到的反扒機(jī)制,并簡(jiǎn)單介紹其解決方式。
基于User-Agent反爬
簡(jiǎn)介:服務(wù)器后臺(tái)對(duì)訪問(wèn)的User_Agent進(jìn)行統(tǒng)計(jì),單位時(shí)間內(nèi)同一User_Agent訪問(wèn)的次數(shù)超過(guò)特定的閥值,則會(huì)被不同程度的封禁IP,從而造成無(wú)法進(jìn)行爬蟲(chóng)的狀況。
解決方法:
一 . 將常見(jiàn)的User-Agent放到ua_list中,以列表形式進(jìn)行隨機(jī)使用
代碼示例:

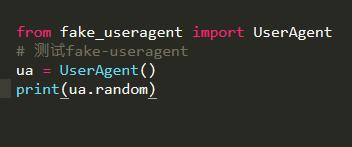
二. 加載fake_useragent庫(kù),隨機(jī)生成User-Agent添加到headers中
代碼示例:
2 基于IP反爬
簡(jiǎn)介: 爬蟲(chóng)程序可能會(huì)在短時(shí)間內(nèi)對(duì)指定的服務(wù)器發(fā)起高頻的請(qǐng)求。后臺(tái)服務(wù)器對(duì)訪問(wèn)進(jìn)行統(tǒng)計(jì),單位時(shí)間內(nèi)同一IP訪問(wèn)的次數(shù)超過(guò)一個(gè)特定的值(閥值),就會(huì)不同程度的禁封IP,導(dǎo)致無(wú)法進(jìn)行爬蟲(chóng)操作。
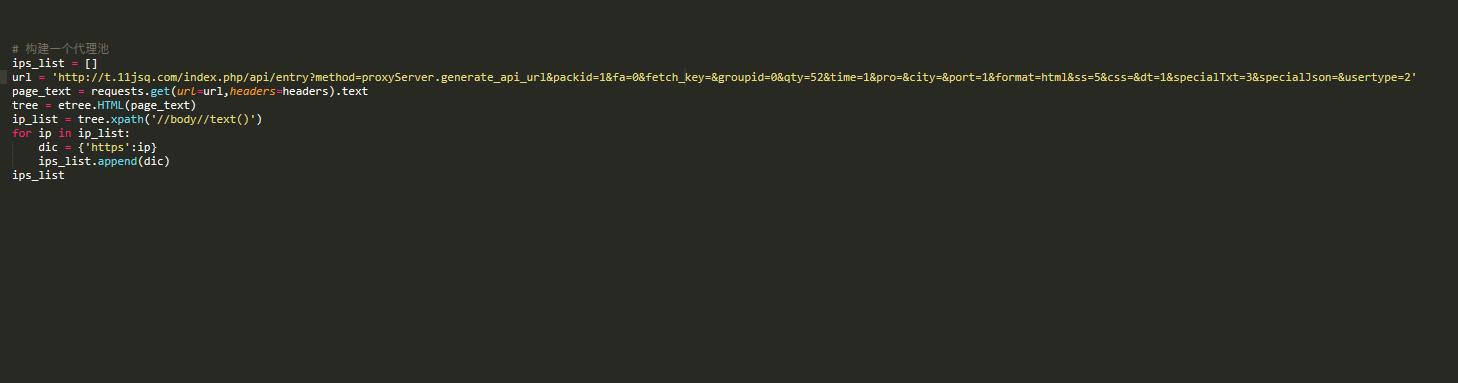
解決方法:使用代理池,并設(shè)定延遲訪問(wèn)
如何獲取代理服務(wù)器?免費(fèi):西祠代理、快代理、goubanjia 收費(fèi):代理精靈等
代碼示例:
3 基于cookie反扒
簡(jiǎn)介:網(wǎng)站會(huì)通過(guò)cookie跟蹤你的訪問(wèn)過(guò)程,如果發(fā)現(xiàn)有爬蟲(chóng)行為會(huì)立刻中斷你的訪問(wèn),比如特別快的填寫(xiě)表單,或者短時(shí)間內(nèi)瀏覽大量頁(yè)面。而正確地處理cookie,又可以避免很多采集問(wèn)題,建議在采集網(wǎng)站過(guò)程中,檢查一下這些網(wǎng)站生成的cookie,然后想想哪一個(gè)是爬蟲(chóng)需要處理的。
解決方法:
一 手動(dòng)處理
將cookie封裝到headers字典中,將該字典作用到get/post方法的headers參數(shù)中
二 自動(dòng)處理
需要兩次處理。第一次是為了捕獲和存儲(chǔ)cookie到session對(duì)象中,第二次就是用攜帶cookie的session進(jìn)行請(qǐng)求發(fā)送,這次請(qǐng)求發(fā)送就是攜帶cookie發(fā)起的請(qǐng)求。可以跟requests一樣調(diào)用get/post進(jìn)行請(qǐng)求的發(fā)送。在使用session進(jìn)行請(qǐng)求發(fā)送的過(guò)程中,如果產(chǎn)生了cookie,則cookie會(huì)被自動(dòng)存儲(chǔ)session對(duì)象中
代碼示例:
#基于session自動(dòng)處理
cookiesess = requests.Session()
#該次請(qǐng)求只是為了捕獲cookie存儲(chǔ)到sess中
sess.get(url='https://xueqiu.com/',headers=headers)
url = 'https://xueqiu.com/v4/statuses/public_timeline_by_category.json?since_id=-1max_id=20367942count=15category=-1'
json_data = sess.get(url=url,headers=headers).json()json_data
4 圖片懶加載
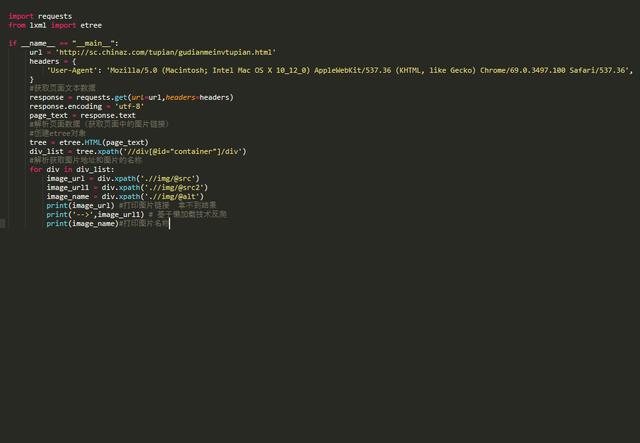
簡(jiǎn)介:圖片懶加載是一種網(wǎng)頁(yè)優(yōu)化技術(shù)。圖片作為一種網(wǎng)絡(luò)資源,在被請(qǐng)求時(shí)也與普通靜態(tài)資源一樣,將占用網(wǎng)絡(luò)資源,而一次性將整個(gè)頁(yè)面的所有圖片加載完,將大大增加頁(yè)面的首屏加載時(shí)間。為了解決這種問(wèn)題,通過(guò)前后端配合,使圖片僅在瀏覽器當(dāng)前視窗內(nèi)出現(xiàn)時(shí)才加載該圖片,達(dá)到減少首屏圖片請(qǐng)求數(shù)的技術(shù)就被稱為“圖片懶加載”。在網(wǎng)頁(yè)源碼中,在img標(biāo)簽中首先會(huì)使用一個(gè)“偽屬性”(通常使用src2,original......)去存放真正的圖片鏈接而并非是直接存放在src屬性中。當(dāng)圖片出現(xiàn)到頁(yè)面的可視化區(qū)域中,會(huì)動(dòng)態(tài)將偽屬性替換成src屬性,完成圖片的加載。
解決方法:通過(guò)細(xì)致觀察頁(yè)面的結(jié)構(gòu),發(fā)現(xiàn)圖片的鏈接真正鏈的偽屬性中,一般不在src中,而是src2中,xpath要使用該屬性
示例代碼:
5 Ajax動(dòng)態(tài)加載
簡(jiǎn)介:從網(wǎng)頁(yè)的 url 加載網(wǎng)頁(yè)的源代碼之后,會(huì)在瀏覽器里執(zhí)行JavaScript程序。這些程序會(huì)加載出更多的內(nèi)容,并把這些內(nèi)容傳輸?shù)骄W(wǎng)頁(yè)中。這就是為什么有些網(wǎng)頁(yè)直接爬它的URL時(shí)卻沒(méi)有數(shù)據(jù)的原因。現(xiàn)在這樣的網(wǎng)站也越來(lái)越多。
解決方法:使用審查元素分析”請(qǐng)求“對(duì)應(yīng)的鏈接(方法:右鍵→審查元素→Network→清空,點(diǎn)擊”加載更多“,出現(xiàn)對(duì)應(yīng)的GET鏈接尋找Type為text/html的,點(diǎn)擊,查看get參數(shù)或者復(fù)制Request URL),循環(huán)過(guò)程。如果“請(qǐng)求”之前有頁(yè)面,依據(jù)上一步的網(wǎng)址進(jìn)行分析推導(dǎo)第1頁(yè)。以此類推,抓取抓Ajax地址的數(shù)據(jù)。對(duì)返回的json使用requests中的json進(jìn)行解析,觀察動(dòng)態(tài)加載的規(guī)律,在請(qǐng)求頭中對(duì)規(guī)律進(jìn)行使用
抓包工具推薦:fiddler
到此這篇關(guān)于python反扒機(jī)制的5種解決方法的文章就介紹到這了,更多相關(guān)python反扒機(jī)制內(nèi)容請(qǐng)搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Python爬蟲(chóng)實(shí)例扒取2345天氣預(yù)報(bào)
- python解決網(wǎng)站的反爬蟲(chóng)策略總結(jié)
- python爬蟲(chóng)的一個(gè)常見(jiàn)簡(jiǎn)單js反爬詳解
- 詳解python 破解網(wǎng)站反爬蟲(chóng)的兩種簡(jiǎn)單方法
- python通過(guò)偽裝頭部數(shù)據(jù)抵抗反爬蟲(chóng)的實(shí)例
- Python反爬蟲(chóng)偽裝瀏覽器進(jìn)行爬蟲(chóng)
- Python常見(jiàn)反爬蟲(chóng)機(jī)制解決方案
- python 常見(jiàn)的反爬蟲(chóng)策略
- python中繞過(guò)反爬蟲(chóng)的方法總結(jié)
