本文旨在分類講述執行計劃中每一種操作的相關信息。
數據訪問操作
首先最基本的操作就是訪問數據。這既可以通過直接訪問表,也可以通過訪問索引來進行。表內數據的組織方式分為堆(Heap)和B樹,其中表中沒有建立聚集索引時數據是通過堆進行組織的,這個是無序的,表中建立聚集索引后和非聚集索引的數據都是以B樹方式進行組織,這種方式數據是有序存儲的。通常來說,非聚集索引僅僅包含整個表的部分列,對于過濾索引,還僅僅包含部分行。
除去數據的組織方式不同外,訪問數據也分為兩種方式,掃描(Scan)和查找(Seek),掃描是掃描整個結構的所有數據,而查找只是查找整個結構中的部分數據。因此可以看出,由于堆是無序的,所以不可能在堆上面進行查找(Seek)操作,而相對于B樹的有序,使得在B樹中進行查找成為可能。當針對一個以堆組織的表進行數據訪問時,就會進行堆掃描,如圖1所示。

圖1.表掃描
可以看出,表掃描的圖標很清晰的表明表掃描的性質,在一個無序組織表中從頭到尾掃描一遍。
而對于B樹結構的聚集索引和非聚集索引,同樣可以進行掃描,通常來講,為了獲取索引表中的所有數據或是獲得索引行樹占了數據大多數使得掃描的成本小于查找時,會進行聚集索引掃描。如圖2所示。

圖2.聚集索引掃描
聚集索引掃描的圖標也同樣能夠清晰的表明聚集索引掃描的性質,找到最左邊的葉子節點后,依次掃描所有葉子節點,達到掃描整個結構的作用。當然對于非聚集索引也是同樣的概念,如圖3所示。

圖3.非聚集索引的掃描
而對于僅僅選擇B樹結構中的部分數據,索引查找(Seek)使得B樹變得有意義。根據所查找的關鍵值,可以使得從僅僅從B樹根部向下走單一路徑,因此免去了掃描不必要頁的消耗,圖4是查詢計劃中的一個索引查找。

圖4.聚集索引查找
索引查找的圖標也是很傳神的,可以看到圖標那根線從根節點一路向下到葉子節點。也就是找到所求數據所在的頁,不難看出,如果我們需要查找多條數據且分散在不同的頁中,這個查找操作需要重復執行很多回,當這個次數大到一定程度時,SQL Server會選擇消耗比較低的索引掃描而不是再去重復索引查找。對于非聚集索引查找,概念是一樣的,就不再上圖片了。
書簽查找(Bookmark Lookup)
你也許會想,假如非聚集索引可以快速的找到所求的數據,但遺憾的是,非聚集索引卻不包含所有所求列時該怎么辦?這時SQL Server會面臨兩個選擇,直接訪問基本表去獲取數據或是在非聚集索引中找到數據后,再去基本表獲得非聚集索引沒有覆蓋到的所求列。這個選擇取決于所估計的行數等統計信息。查詢分析器會選擇消耗比較少的那個。
一個簡單的書簽查找如圖5所示。

圖5.一個簡單的書簽查找
從圖5可以看出,首先通過非聚集索引找到所求的行,但這個索引并不包含所有的列,因此還要額外去基本表中找到這些列,因此要進行鍵查找,如果基本表是以堆進行組織的,那么這個鍵查找(Key Lookup)就會變成RID查找(RID Lookup),鍵查找和RID查找統稱為書簽查找。
不過有時候索引查找所返回的行數過多導致書簽查找的性能遠不如直接進行掃描操作,因此SQL Server這時會選擇掃描而不是書簽查找。如圖6所示。
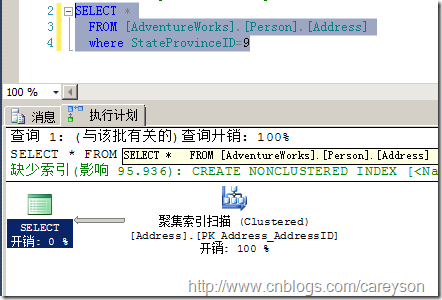
圖6.StateProvinceID列有非聚集索引,但由于返回行數過多,分析器會選擇掃描而不是書簽查找
這個估計是根據統計信息進行的,關于統計信息,可以看我之前的一篇博文:淺談SQL Server中統計對于查詢的影響
聚合操作(Aggregation)
聚合函數會導致聚合操作。聚合函數是將一個集合的數據按照某種規則匯總成1個數據,或基于分組按照規則匯總成多個數據的過程。一些聚合函數比如:avg,sum,min,另外還有distinct關鍵字都有可能導致兩類聚合操作:流聚合(Stream Aggregation)和哈希聚合(Hash Aggregation)。
流聚合(Stream Aggregation)
流聚合需要再執行聚合函數之前,被聚合的數據集合是有序的,這個有序數據既可以通過執行計劃中的Sort進行,也可以直接從聚集或是非聚集索引中直接獲得有序數據,另外,沒有Group by的聚合操作被成為標量聚合,這類操作一定是會執行流聚合。
比如,我們直接進行標量聚合,如圖7所示。
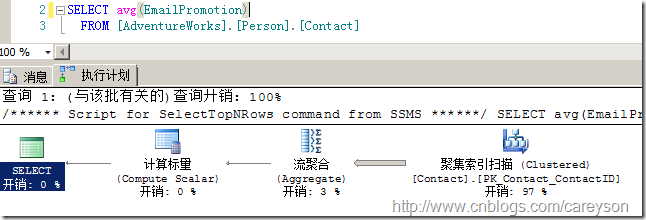
圖7.流聚合
但對于加了Group by的子句,因為需要數據按照group by 后面的列有序,就需要Sort來保證排序。注意,Sort操作是占用內存的操作,當內存不足時還會去占用tempdb。SQL Server總是會在Sort操作和散列匹配中選擇成本最低的。一個需要Sort的操作如圖8所示。
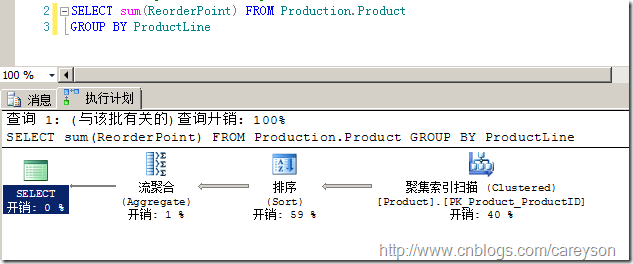
圖8.需要排序的流聚合
圖8中排序操作按照ProductLine進行排序后,然后就根據各自的分組做聚合操作了。
散列聚合(Hash aggregation)
上面的流聚合適合比較少的數據,但是對于相對大一點的表。使用散列集合成本會比排序要低。散列集合通過在內存中建立散列表來實現聚合,因此無需對數據集合進行排序。內存中所建立的散列表以Group by后面的列作為鍵值,如圖9所示。
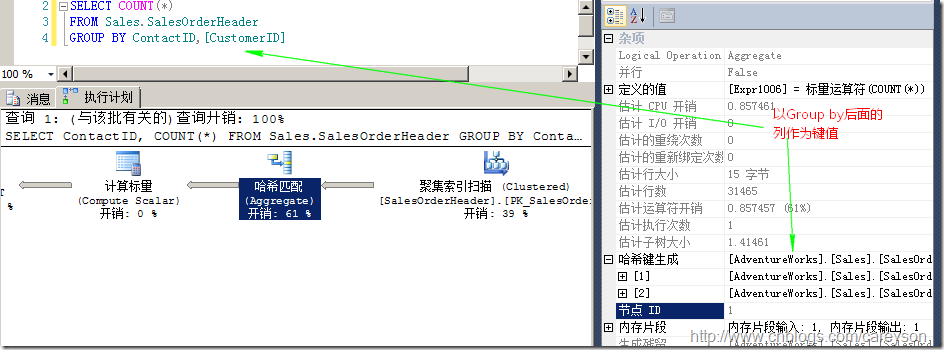
圖9.散列聚合
在內存中建立好散列表后,會按照group by后面的值作為鍵,然后依次處理集合中的每條數據,當鍵在散列表中不存在時,向散列表添加條目,當鍵已經在散列表中存在時,按照規則(規則是聚合函數,比如Sum,avg什么的)計算散列表中的值(Value)。
連接(Join)
當多表連接時(書簽查找,索引之間的連接都算),SQL Server會采用三類不同的連接方式:循環嵌套連接(Nested Loops Join),合并連接(Merge Join),散列連接(Hash Join)。這幾種連接并不是哪種會比另一種更好,而是每種連接方式都會適應特定場景。
循環嵌套連接(Nested Loops Join)
由圖10可以看到一個簡單的循環嵌套連接。
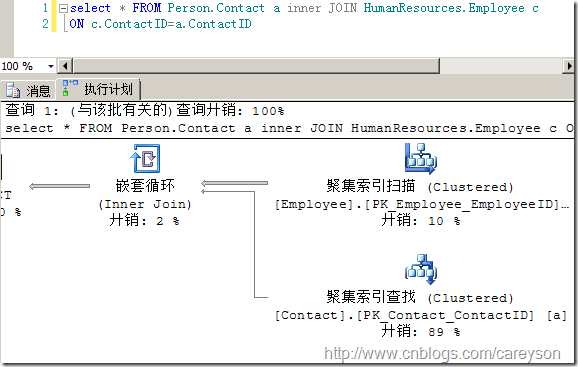
圖10.一個循環嵌套連接的實例
循環嵌套連接的圖標同樣十分傳神,處在上面的外部輸入(Outer input),這里也就是聚集索引掃描。和處在下面的內部輸入(Inner Input),這里也就是聚集索引查找。外部輸入僅僅執行一次,根據外部輸入滿足Join條件的每一行,對內部輸入進行查找。這里由于是290行,對于內部輸入執行290次。
可以通過屬性窗口看到.如圖11所示:
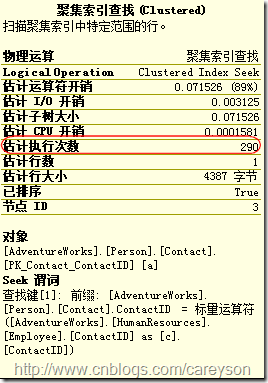
圖11.內部輸入的執行次數
根據嵌套循環的原理不難看出,由于外部輸入是掃描,內部輸入是查找,當兩個Join的表外部輸入結果集比較小,而內部輸入所查找的表非常大時,查詢優化器更傾向于選擇循環嵌套方式。
合并連接(Merge Join)
不同于循環嵌套的是,合并連接是從每個表僅僅執行一次訪問。從這個原理來看,合并連接要比循環嵌套要快了不少。下面來看一個典型的合并連接,如圖12所示。
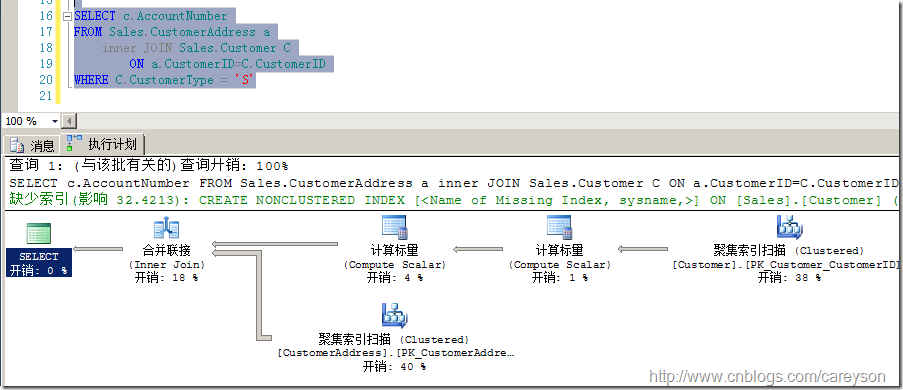
圖12.合并連接
從合并連接的原理不難想象,首先合并連接需要雙方有序.并且要求Join的條件為等于號。因為兩個輸入條件已經有序,所以從每一個輸入集合中取一行進行比較,相等的返回,不相等的舍棄,從這里也不難看出Merge join為什么只允許Join后面是等于號。從圖11的圖標中我們可以看出這個原理。
如果輸入數據的雙方無序,則查詢分析器不會選擇合并連接,我們也可以通過索引提示強制使用合并連接,為了達到這一目的,執行計劃必須加上一個排序步驟來實現有序,如圖13所示。
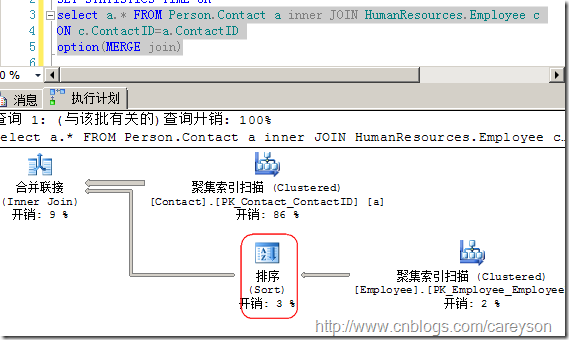
圖13.通過排序來實現Merge Join
散列連接(Hash Join)
散列連接同樣僅僅只需要只訪問1次雙方的數據。散列連接通過在內存中建立散列表實現。這比較消耗內存,如果內存不足還會占用tempdb。但并不像合并連接那樣需要雙方有序。一個典型的散列連接如圖14所示。
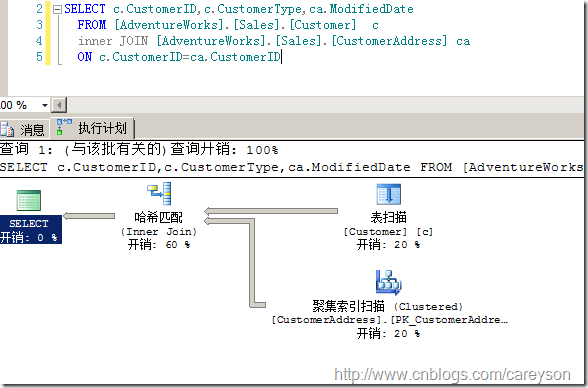
圖14.散列連接
這里我刪除了Costomer的聚集索引,否則兩個有序輸入SQL Server會選擇代價更低的合并連接。SQL Server利用兩個上面的輸入生成哈希表,下面的輸入來探測,可以在屬性窗口看到這些信息,如圖15所示。
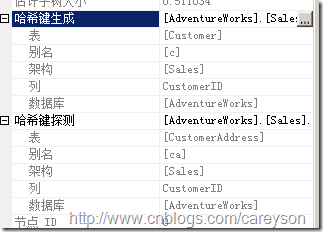
圖15.散列鍵生成和散列鍵探測
通常來說,在兩個輸入數據比較大,且所求數據在其中一方或雙方沒有排序的條件達成時,會選用散列匹配。
并行
當多個表連接時,SQL Server還允許在多CPU或多核的情況下允許查詢并行,這樣無疑提高了效率,一個并行的例子如圖16所示。
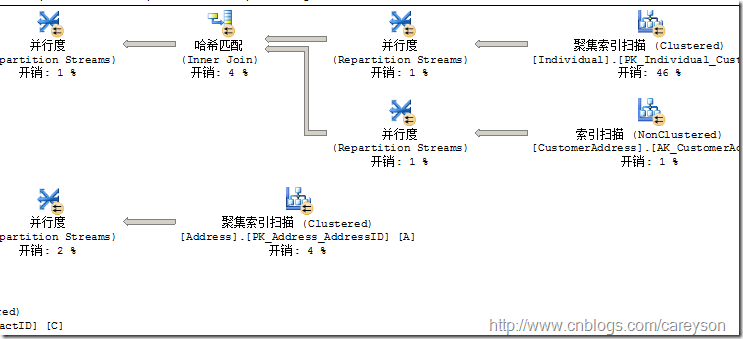
圖16.并行提高效率
總結
本文簡單介紹了SQL Server執行計劃中常見的操作極其原理,了解這些步驟和原理是優化查詢的基本功。
您可能感興趣的文章:- MySQL 常見存儲引擎的優劣
- 修改MySQL數據庫引擎為InnoDB的操作
- 關于MySQL Memory存儲引擎的相關知識
- 詳解mysql中的存儲引擎
- MySQL 選擇合適的存儲引擎
- 聊聊MySQL中的存儲引擎
- MySQL創建數據表時設定引擎MyISAM/InnoDB操作
- 簡述MySQL InnoDB存儲引擎
- 如何自己動手寫SQL執行引擎
