一直以來,語音分離在音視頻領域都是一個重要的課題,近年來深度學習的快速發(fā)展為解決單通道語音分離提供了一個新的思路。在LiveVideoStackCon2019上海音視頻技術大會上,大象聲科高級音頻算法工程師閆永杰以降噪場景為例,詳細介紹了深度學習在單通道語音分離中的應用。
大家好,我是來自大象聲科的閆永杰,接下來我會從以下六個方面為大家介紹深度學習在單通道語音分離中的應用:
1、單通道語音分離問題的引入
2、借助深度學習來解決單通道語音分離
3、工程實踐中的挑戰(zhàn)及解決方案
4、思考
5、總結
一、單通道語音分離問題的引入
在第一部分,我會簡單介紹單通道語音分離問題的引入。首先,存在一個問題就是到底什么是單通道語音分離呢?對于做與語音相關工作的工作者來說,單通道語音分離是大家比較熟悉的一個問題,那么我就先從音頻采集的方式開始來為大家介紹。
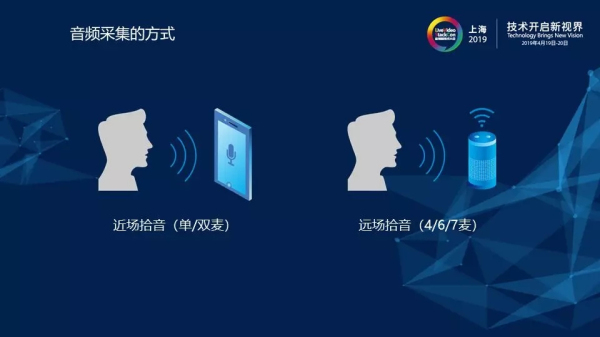
1)音頻采集的方式
目前主流的音頻采集方式主要包括兩種場景:近場拾音和遠場拾音。對于近場拾音,在我們生活中是很常見的,例如我們在使用手機打電話時手持或者開啟免提。對于遠場拾音,我們同樣也不會陌生,像現(xiàn)在非常火的麥克風陣列技術就是采用的遠程拾音,例如小愛同學、天貓精靈等,它們都可以做到在相隔三到五米的情況下實現(xiàn)遠距離拾音。那么,就近場拾音和遠場拾音的區(qū)別所在,首先是使用場景的不同,再就是麥克風數(shù)量的不同。遠場拾音采用的麥克風數(shù)量通常為多個,有兩麥、四麥、六麥、七麥,甚至還包括更加非常復雜的情況。而對于近場拾音,以手機通話來舉例,通常情況下使用的是單麥或者雙麥。當我們手持手機時,如果仔細觀察手機可以發(fā)現(xiàn)手機實際上是有兩個麥克風的,其中位于底部的是主麥,位于頂部的是副麥,在業(yè)界副麥也常會被叫做降噪麥克風。本次為大家介紹的單通道語音,主要討論的是單麥克風近場拾音的場景。
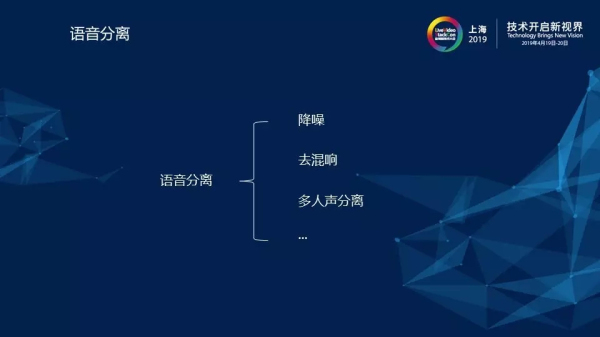
2)語音分離
首先,我們需要來界定一下,到底什么是語音分離?實際上,我們經常所講的降噪、去混響、多人聲分離等等的過程都屬于語音分離的過程。其中,降噪指的就是語音與噪音的分離,去混響指的就是語音與混響的分離,而多人聲分離的場景則相對復雜一些,在這里包含有目標人聲和其它的干擾人聲。其實對于以上幾種語音分離的場景,它們的最終目標是相同的,即將目標人聲與其它非目標人聲的語音進行分離。下面就以降噪為例,為大家介紹語音分離的過程。
3)降噪
在我們的現(xiàn)實生活中,噪音的種類是形形色色的。如上圖所示,例如在車水馬龍的街道、吵鬧的酒吧和KTV、人來人往的車站以及各種加工工廠,這些場景都是典型的充滿嘈雜的噪音的地方。形形色色的噪音對通話質量來說是一個非常大的挑戰(zhàn),特別是當下所流行的視頻通話,視頻通話雙方所處的環(huán)境各有可能,那么在嘈雜的環(huán)境中對于視頻通話的良好體驗就會產生巨大的挑戰(zhàn)。因此,在語音通話中實現(xiàn)更好的降噪已經成為了一個必不可少的課題。
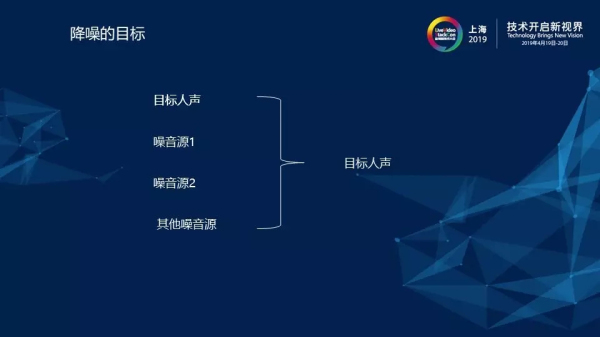
那么,降噪的最終目標是什么呢?直白的說就是將目標人聲從多種噪音源中分離出來。如上圖所示,在通話的過程中,實際輸入的語音是包含目標人聲、噪音源1、噪音源2以及其他噪音源的,其中噪音源的數(shù)量是一般都是多種,而降噪的目標就是將目標人聲從中提取出來。
現(xiàn)在已經有了降噪的目標,那么該如何實現(xiàn)這個目標,解決目標人聲和噪音源分離的問題呢?
二、借助深度學習來解決單通道語音分離
在第二部分,我將為大家詳細介紹解決單通道語音分離的方法,首先是傳統(tǒng)的單通道語音增強方法。
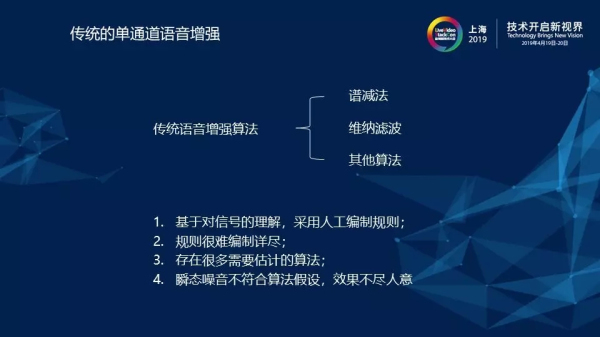
1)傳統(tǒng)的單通道語音增強
要想實現(xiàn)單通道語音分離可能存在以下難點:單通道語音一般只包含一個麥克風,這很大程度上也限制了算法的能力。如果存在有多個麥克風的話,通過一些空間信息將與主講人方向不同的噪音去除掉即可達到語音分離的目的。而單通道語音只有一個麥克風,因此就只存在一路信號,沒有方位信息,這也就為實現(xiàn)語音分離帶來了挑戰(zhàn)。傳統(tǒng)的語音增強算法包括有譜減法、維納濾波、卡爾曼濾波以及其他算法。對于譜減法,其前提是先假設噪音是穩(wěn)定的,穩(wěn)態(tài)噪音在我們生活中也是很常見的,例如冰箱發(fā)出的聲音或者是航空發(fā)動機發(fā)出的規(guī)律性噪音。譜減法先假設噪音是穩(wěn)定的,然后估計噪音,估計噪音的方法是將人不說話的時間段的噪音取平均值,估出噪音以后,當人說話的時候減去對應噪音就可以認為剩余的為純凈的語音。但是這種方法存在很明顯的弊端,它的前提是假設噪音都是穩(wěn)態(tài)的,而實際上在日常生活中,瞬態(tài)的噪音也是非常多的,例如敲擊聲、咳嗽聲、其他人播放音樂的聲音、汽笛聲等等。對于這些非穩(wěn)態(tài)的噪音,譜減法基本上是無能為力的。此外,還有一點缺陷就是譜減法假設的穩(wěn)態(tài)噪音實際上取的是平均值,這就有可能導致在做減法時出現(xiàn)負值。而當出現(xiàn)負值時,譜減法只是將負數(shù)直接用0替代了,這種做法實際上會在降噪的過程中額外帶來新的噪音。
最后,總結一下傳統(tǒng)語音增強算法的特點:1)傳統(tǒng)方法是基于對信號的理解,采用人工編制的一些規(guī)則;2)由于規(guī)則是人工編制的,這就導致存在規(guī)則很難編制詳盡的問題;3)存在很多需要估計的算法,通過對噪音調參得到適配的參數(shù)的調參過程十分考驗人對于信號的理解以及自身經驗的豐富程度;4)最后一個也是最重要的問題就是瞬態(tài)噪音,瞬態(tài)噪音不符合算法假設,傳統(tǒng)方法對它的處理結果基本上都是不盡如人意的。
下面將為大家介紹我們解決單通道語音分離的方法。
2)計算聽覺場景分析
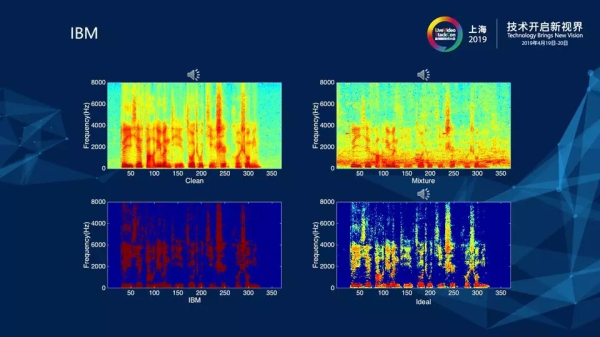
對于這一部分,首先為大家分享一個概念——計算聽覺場景分析,這套理論的主要貢獻者之一是我們的首席科學家汪德亮教授,他于2001年提出理想二值掩膜(Ideal Binary Mask,IBM),并將預測IBM作為計算聽覺場景分析解決語音分離問題的計算目標。上圖是IBM的相關計算公式,為了方便講解,我們先拋開公式,看下面的四張語音的圖。
如圖所示,可以看出與圖像信號不同的是語音信號是一維的信號,而圖像信號是二維的信號。對于語音信號利用一維的信息直接處理的難度是非常大的,因此我們將原始語音信號經過時頻變換,如:短時傅里葉變換(STFT),就會得到左上的這張圖——原始信號的幅度譜。幅度譜的顏色越深代表著能量越大,其中左上圖中的紅色部分就是語音的部分,看起來有一道一道的梳狀條紋,是語音的諧波結構,這就是語音的元音成分。左上圖是純凈語音對應的幅度譜,而右上圖則是對應帶噪語音的幅度譜,看起來有一些雜亂,語音成分被破話。右下圖就是我剛才提到的IBM,IBM的含義是理想二值掩膜。右下圖對應的是將IBM(左下圖)覆蓋到帶噪語音譜(右上圖),形成了降噪后的語音譜。而從圖中可以看出,降噪后的語音譜(右下圖)比噪聲語音譜干凈(右上圖)了許多,但與純凈語音譜相比,存在部分過壓的現(xiàn)象,聽起來實際效果就是噪音基本消除,但是會有些許失真。
接下來,我們再來看IBM的計算公式,公式里面的IBM其實就是深度學習最終預測的目標,IBM計算所得的值為0和1,即可認為把最終結果分類成0和1,那么如何去界定0和1呢?界定條件如下:如果語音的能量s減去噪音的能量n大于一個θ值,θ一般取值為0,此時IBM的值為1,即我們認為語音比噪音大的地方,IBM是1;同樣地,我們認為語音比噪音小的地方,IBM是0,即認為是噪音。這解釋了為何將在之前圖中第二層從左到右的第一張圖譜覆蓋到第一層從左到右的第二張圖譜上所得的信號與純凈語音是有差距的。而這樣做的好處就是成功將一個回歸問題改變?yōu)榉诸悊栴},只需要預測它是0或者1就可以了,這就使得學習難度變小,更容易預測。但不好的地方就是聽上去語音會有些許失真。但在2013年,當時這個方法所取得的效果已經算是非常好的。在此之后,陸續(xù)又有人提出了其他的一些計算目標,如TBM、IRM等,而這些目標其實都與IBM是相似的,只是進行了一些修正改進,例如IRM的值不僅僅只是0和1了,當我們認為它有一半的部分是語音,那么我們的目標值就是0.5.當前我們所采用的計算目標大多數(shù)是IRM。
3)深度學習
首先,大家可能也曾思考過深度學習方法到底是什么或者深度學習方法到底要做什么事情。簡單來講,深度學習方法的本質就是通過構建模型,來擬合一個函數(shù)映射,即我們提供一個輸入并告訴應該輸出什么,然后通過輸入大量數(shù)據(jù),不斷學習數(shù)據(jù)之間的潛在對應關系,找到一個模型去模擬這個函數(shù)映射關系。構建模型有很多方法,例如高斯混合模型、支持向量機、多層感知機以及深度神經網絡(DNN),它們的目的就是去找到一個模型能夠通過輸入來預測出一個目標值。在上面的函數(shù)中,剛才講到的IBM就是對應里面的y,也就是說我們要預測的目標就是IBM,而我們輸入就是前面所講的右上圖——帶噪語音的幅度譜。這是因為我們在部署的時候,實際上只能拿到這個信息。輸入是帶噪語音的幅度譜,目標是IBM,那么這樣函數(shù)映射就建立好了。接下來就是網絡的構建了,網絡的構建可以用簡單一些的,例如全連接,卷積或者是后面發(fā)展比較好的RNN、LSTM一類的結構去構建模型。
下面,總結一下深度學習方法實現(xiàn)語音分離:1)首先要確定目標——IBM,當然我們在這里是以IBM為例來講的,如果你采用IRM;2)特征輸入——短時傅里葉變換后的幅度譜;3)訓練工具現(xiàn)在都已經十分成熟了,Tensorflow、Pytorch都很好用;4)數(shù)據(jù)驅動,最后就是需要不斷喂數(shù)據(jù),這個喂的數(shù)據(jù)就是語音。在這里,需要講一下的就是大部分環(huán)境中的噪音都是加性噪聲,因此我們可以仿真得到混合后的聲音,只需將裁好的噪音與語音加在一起即可。這樣一來,我們有了訓練的目標,純凈語音、噪聲都是已知的,只需要把這些數(shù)據(jù)喂給網絡,讓它不斷的調整參數(shù),就會得到一個比較不錯的效果。
下面將為大家介紹在工程實踐中部署時的挑戰(zhàn)和解決方案。
三、工程實踐中的挑戰(zhàn)及解決方案
在這一部分,我將為大家介紹工程實踐中遇到的問題以及我們提出的解決方案。
1)工程實踐中的挑戰(zhàn)
前面所講的原理其實都是非常簡單的,但僅僅只是學術的,而深度學習講究的是落地,而在落地的時候,深度學習所面臨的最大挑戰(zhàn)就是部署。對于ASR或者NLP來說都是可以部署在云端上的,因此可以對模型有一些容忍度,可發(fā)揮的空間也更大一點。但是,對于實現(xiàn)降噪效果的,如果運行在服務器上,它的延時、實時性都是不切實際地,所以部署的終端大多數(shù)是移動設備,例如手機、iPad,甚至是在耳機中非常弱的M4芯片上。因此,對于這些設備來說,1)功耗必須得控制好,那么計算量就不能太大;2)由于這些芯片的內存非常小,例如M4可能只有幾百K的空間,因此模型參數(shù)不能太大,否則無法部署。此外,給大家講一下我們公司最初是如何演示最終效果的,別人提供給我們一個帶噪的語音,我們在服務器上跑一下再發(fā)給人家,這樣一來的體驗效果是很差的,后來感覺太復雜了就寫了一個MATLAB的,但效果也不是實時的,這是我們當時遇到的最大的挑戰(zhàn)。
為了解決這些問題,我們做了一些相關的優(yōu)化。
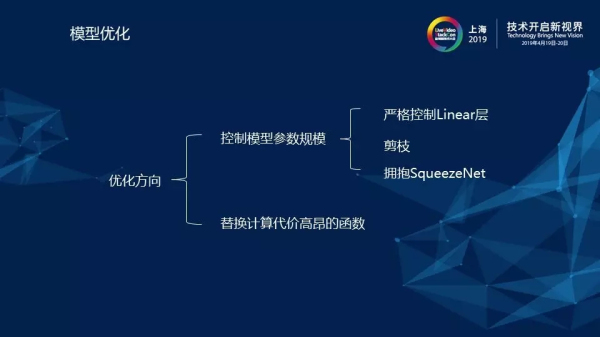
2)模型優(yōu)化
針對上述問題,我們對模型進行了優(yōu)化,優(yōu)化的方向包括控制模型參數(shù)規(guī)模和替換計算代價高昂的激活函數(shù)。首先,模型參數(shù)規(guī)模一定要降下來,模型參數(shù)最先影響的是帶寬。如果模型參數(shù)大于所要部署的嵌入式設備的內存,則不可能實現(xiàn)部署,這是一個裁模性的考量。其次,要減少計算量,參數(shù)減少以后,乘加指令自然會減少。控制模型的大小是一個非常重要的方向,例如全連接層的經典模型,我們輸入1024個節(jié)點,則輸出1024個節(jié)點,僅僅一層網絡就已經占用了4M的空間,然而設備卻只有幾百K的內存。因此,對于全連接層的使用一定要慎重,盡量選用其他結構如RNN或CNN來替代,尤其是CNN的參數(shù)共享可以帶來非常大的提升。
我們在設計網絡的時候,一定要考量DNN的輸入與輸出的大小規(guī)模,這是一個非常重要的點,盡量使用CNN或者RNN的結構去替代DNN。然后,還有最重要的一點就是選取一個好的Feature,剛才前面講的我們用的Feature選擇的是Mix語音、經過STFT后的幅度圖,這雖然是最直觀、最簡單的,但是學起來難度較大。我們也在這方面做了很多的嘗試和工作,例如將輸入Feature從幅度譜改為mel譜就可以將輸入規(guī)模大大減小。就像我在前面所講的深度學習要學的是個函數(shù)映射,可能大家會有疑問,為什么在輸入特征時不直接把時域的信號送進去,然后目標就是純凈語音的信號?其實如果這么做能成功的話,那肯定是最好的,但是如果你告訴網絡的是一個完整、沒有丟失的信息,這在它學習規(guī)律的過程中,對于深度學習來說,學習難度太大,參數(shù)量是降不下來的。因此,我們折中選取了頻域的信號,選取頻域信號以后,學習難度就會下降很多,不僅可以比較容易的能學到它的模式,而且參數(shù)量也會大大下降。所以,在裁模型的時候,一定要注意選取一個好的Feature。
最后一點也是來自工程實踐中的一個問題,例如當我們訓練好模型交給同事部署時,同事會反饋說,你用的ELU函數(shù),一個EXP指令直接占用了600個cycle。后來我們發(fā)現(xiàn)問題,工程師在訓練模型的時候,一定要與最終部署的同事溝通好,要了解到哪些函數(shù)對他們來說是很有挑戰(zhàn)的。例如將ELU換成一個簡單一些的RELU,部署所需指令可能就只有一個兩個cycle,而如果用ELU,在性能上對實驗結果來說差距是不大的,但是在部署時差距就會放大幾百倍,所以一些代價高的函數(shù)一定要慎重使用。
3)算法優(yōu)化
在做好模型優(yōu)化后,一個比較小且合理的模型給到工程團隊,工程團隊在落地的時候還要做一些算法優(yōu)化。1)定點化。大家都知道,如果做圖像的話,一般會用int8去量化,這樣帶來的好處就是學習時用的float32,部署時用int8可以節(jié)省4倍的內存,這是一個很好的優(yōu)化。但是,對于語音還不能用int8,我們嘗試過,使用int8最終會導致精度太差,部署的模型預測出來的值與float32的值差距太大。這主要是因為對于語音,我們一般采樣的是16bit,在后面量化時會使用Int16去替代float32,會帶來1倍的內存帶寬的下降。2)合理排布流水線,注意不要因為頻繁地數(shù)據(jù)訪存缺頁,導致打斷了流水線使cycle數(shù)急劇增加,一定要在匯編層流程上排布好流水線。3)利用平臺并行計算指令。大多數(shù)平臺都是有這個并行指令計算的,例如ARM上的NEON或者是SIMD,在可用的情況下一定要用起來,一般會有2到4倍的加速。經過這些優(yōu)化以后,基本上就可以得到一個部署在手機上的模型。
四、思考
在這一部分,我想帶著大家一起思考,為什么深度學習會有這么好的效果呢?因為深度學習具有以下優(yōu)勢:
1)數(shù)據(jù)驅動,一定條件下,數(shù)據(jù)越多性能越好。我們只需要采集足夠多的噪音、足夠多的語音,源源不斷地喂給網絡,就能夠從中學習到語音的模式,所得的模型更加精確。為什么在這里要說一定條件下呢?一方面如果是同類噪音,采集的再多也沒什么用,這就要求我們要保證數(shù)據(jù)的豐富性。另一方面,大家可能有一個疑慮,既然說是數(shù)據(jù)驅動的,如果某種噪音并未采集過或見過,那該怎么辦呢?此時就要考量算法的泛化能力。深度學習中有一個概念就是過擬合,如果見過的數(shù)據(jù)都能擬合的非常好,而沒見過的數(shù)據(jù)就會突然表現(xiàn)非常差,說明模型過擬合了,這是不可接受的。所以,在做音頻降噪的時候,一定要考慮模型的泛化能力,同等條件下,如果模型越小,學習過程中最后的loss值跟大模型基本一致,那就說明模型泛化能力強。也就是說參數(shù)越少,泛化能力一定程度上越好,所以前面所講的我們做的裁減模型的工作對泛化能力也是有很大的提高的。這樣一來,在部署的時候,對于沒見過噪聲,預測的結果也不會太差。
2)相比傳統(tǒng)算法手工統(tǒng)計的模式,深度學習可以學到更加魯棒的模式。對于傳統(tǒng)算法的調參是十分麻煩的,例如我們看過的有一些競品算法公司調參,參數(shù)大概有幾百個,在對接廠商的時候需要將參數(shù)逐一調整,以實現(xiàn)不錯的效果,這中間的工作量非常大。但是,這幾百個參數(shù)跟深度學習相比就太少了,深度學習的參數(shù)量基本上是百萬規(guī)模的,甚至是千萬規(guī)模的。因此,手工統(tǒng)計的那些參數(shù)所包含的信息,它所擬合的模型的建模能力跟深度學習是不可比擬的,因此深度學習相比于傳統(tǒng)算法,它學到的模式更加魯棒。3)深度學習有記憶的能力。對于深度學習來說,一定程度上,見過的數(shù)據(jù)越豐富,效果越好。
在這里,說一個我們的首席科學家汪老師給我們講的故事,他在俄亥俄州作教授,有一個老同事得了海默森綜合癥,記憶力會減退。有一天,這個老同事回到學校去看望汪老師,他知道汪老師是做人工智能研究,根據(jù)自己的親身感受,當時就說了一句話,No Intelligence Without Memory!這句話的意思是沒有記憶就沒有智能。所以說,記憶對于智能來說非常重要,深度學習有非常多的參數(shù),它會通過記憶非常多的模式來記住語音的分布以及噪音是長什么樣子的。當然,對于降噪來說,更多記憶的是語音的一種模式,因為噪音實在是太復雜了,記錄噪音的難度太大了。
五、總結
最后,就是本次的總結部分了。本次演講內容首先是介紹了單通道語音分離的定義,其中語音分離方法我們介紹了三種,主要是以降噪為例去講的,因為降噪是比較關鍵的,再就是介紹了在單通道語音分離里面遇到的一些挑戰(zhàn),以及我們是如何去解決所遇到的困難的。