目錄
- 前言
- 一、簡單靜態網頁的爬取
- 1.1 選取爬蟲策略——縮略圖
- 1.2 選取爬蟲策略——高清大圖
- 二、動態加載網站的爬取
- 2.1 選取爬蟲策略——selenium
- 2.2 選取爬蟲策略——api
- 三、selenium模擬登錄
前言
python基礎爬蟲主要針對一些反爬機制較為簡單的網站,是對爬蟲整個過程的了解與爬蟲策略的熟練過程。
爬蟲分為四個步驟:請求,解析數據,提取數據,存儲數據。本文也會從這四個角度介紹基礎爬蟲的案例。
一、簡單靜態網頁的爬取
我們要爬取的是一個壁紙網站的所有壁紙
http://www.netbian.com/dongman/
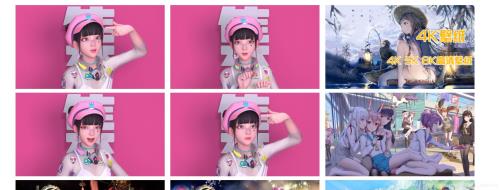
1.1 選取爬蟲策略——縮略圖
首先打開開發者模式,觀察網頁結構,找到每一張圖對應的的圖片標簽,可以發現我們只要獲取到標黃的img標簽并向它發送請求就可以得到壁紙的預覽圖了。
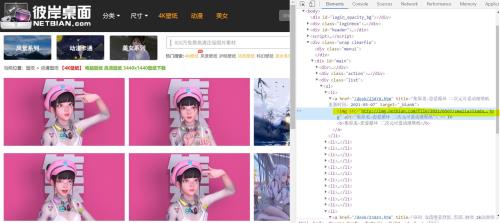
隨后注意到網站不止一頁,打開前3頁的網站觀察url有沒有規律
http://www.netbian.com/dongman/index.htm#第一頁
http://www.netbian.com/dongman/index_2.htm#第二頁
http://www.netbian.com/dongman/index_3.htm#第三頁
我們發現除了第一頁其他頁數的url都是有著固定規律的,所以先構建一個含有所有頁數url的列表
url_start = 'http://www.netbian.com/dongman/'
url_list=['http://www.netbian.com/dongman/index.htm']
if not os.path.exists('./exercise'):
os.mkdir('./exercise')
for i in range(2,133):
url = url_start+'index_'+str(i)+'.htm'
url_list.append(url)
至此我們的基本爬蟲策略就確定了。
網頁請求
for url in url_list:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
response = requests.get(url=url,headers=headers).text
解析數據
在這里我們選用etree解析數據
tree = etree.HTML(response)
提取數據
在這里我們選用xpath提取數據
leaf = tree.xpath('//div[@class="list"]//ul/li/a/img/@src')
for l in leaf:
print(l)
h = requests.get(url=l, headers=headers).content
存儲數據
i = 'exercise/' + l.split('/')[-1]
with open(i, 'wb') as fp:
fp.write(h)
完整代碼
import requests
from lxml import etree
import os
url_start = 'http://www.netbian.com/dongman/'
url_list=['http://www.netbian.com/dongman/index.htm']
#http://www.netbian.com/dongman/index_2.htm
if not os.path.exists('./exercise'):
os.mkdir('./exercise')
for i in range(2,133):
url = url_start+'index_'+str(i)+'.htm'
url_list.append(url)
print(url_list)
for url in url_list:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
response = requests.get(url=url,headers=headers).text
tree = etree.HTML(response)
leaf = tree.xpath('//div[@class="list"]//ul/li/a/img/@src')
for l in leaf:
print(l)
h = requests.get(url=l, headers=headers).content
i = 'exercise/' + l.split('/')[-1]
with open(i, 'wb') as fp:
fp.write(h)
1.2 選取爬蟲策略——高清大圖
在剛剛的爬蟲中我們爬取到的只是壁紙的縮略圖,要想爬到高清版本,就需要我們更改策略。重新打開開發者工具進行觀察,發現在原先爬取的img標簽之上還有一個href標簽,打開之后就會跳轉高清大圖。

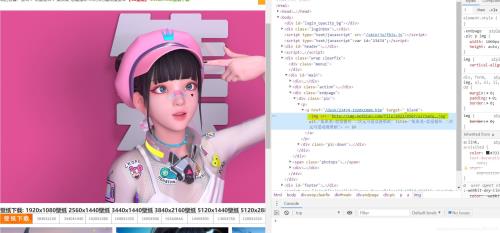
那么此時我們的爬取策略就變成了提取這個href標簽的內容,向這個標簽中的網站發送請求,隨后在該網站中找到img標簽進行再一次請求。
我們用到了正則表達式來提取href標簽的內容。正則表達式是比xpath語法更簡便的一種數據提取方法,具體有關語法可查看以下文檔
for url in url_list:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
response = requests.get(url=url,headers=headers).text
leaf = re.findall("desk/\d*.htm",response,re.S)
for l in leaf:
url = "http://www.netbian.com/"+str(l)
h = requests.get(url=url, headers=headers).text
leaf_ =re.findall('div class="pic">.*?(http://img.netbian.com/file/\d*/\d*/\w*.jpg)',h,re.S)
這樣輸出的leaf_就是我們要找的高清大圖的img標簽,此時我們只需要再次發送請求隨后再保存數據就可以了。
存儲數據
for l_ in leaf_:
print(l_)
h = requests.get(url=l_, headers=headers).content
i = 'exercise/' + l_.split('/')[-1]
with open(i, 'wb') as fp:
fp.write(h)
完整代碼
import requests
import os
import re
url_start = 'http://www.netbian.com/dongman/'
url_list=['http://www.netbian.com/dongman/index.htm']
if not os.path.exists('./exercise'):
os.mkdir('./exercise')
for i in range(2,133):
url = url_start+'index_'+str(i)+'.htm'
url_list.append(url)
print(url_list)
for url in url_list:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
response = requests.get(url=url,headers=headers).text
leaf = re.findall("desk/\d*.htm",response,re.S)
for l in leaf:
url = "http://www.netbian.com/"+str(l)
h = requests.get(url=url, headers=headers).text
leaf_ =re.findall('div class="pic">.*?(http://img.netbian.com/file/\d*/\d*/\w*.jpg)',h,re.S)
for l_ in leaf_:
print(l_)
h = requests.get(url=l_, headers=headers).content
i = 'exercise/' + l_.split('/')[-1]
with open(i, 'wb') as fp:
fp.write(h)
二、動態加載網站的爬取
我們要爬取的是另一個壁紙網站的所有壁紙
https://sucai.gaoding.com/topic/9080?

2.1 選取爬蟲策略——selenium
首先打開開發者模式,觀察網頁結構,此時我們會發現一頁上的所有壁紙并不是全部都加載出來了的,也就是說隨著我們下拉滾動條,內容會不斷實時加載出來,查看網頁元素時也能看到lazy-image這個代表動態加載的標簽。
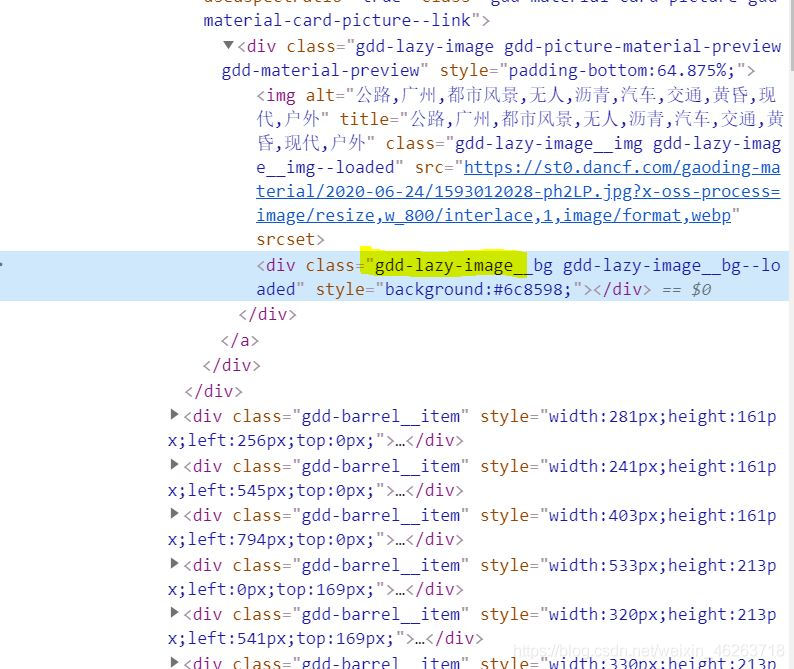
由于是動態加載,因此不能用之前的直接發送請求的辦法來爬取數據了,面對這種情況我們就需要模擬瀏覽器發送一個請求,并且下拉頁面,來實現爬取一個實時加載網頁的目的。
觀察完網頁結構之后我們又來觀察頁數,這次就不多說了,想必大家也能發現規律
url_list=[]
for i in range(1,4):
url = 'https://sucai.gaoding.com/topic/9080?p={}'.format(i)
url_list.append(url)
網頁請求
在這里我們用到了selenium這個自動化測試框架
for url in url_list:
driver = webdriver.Chrome()
driver.get(url)
driver.maximize_window()
time.sleep(2)
i=0
while i10:#下拉滾動條加載頁面
i+=1
driver.execute_script("window.scrollBy(0,500)")
driver.implicitly_wait(5)#顯式等待
解析提取數據
items = driver.find_elements_by_xpath("http://*[@class='gdd-lazy-image__img gdd-lazy-image__img--loaded']")
for item in items:
href = item.get_attribute('src')
print(href)
至于數據的存儲只需要再請求我們爬下來的href標簽的網站就可以了。
完整代碼
from selenium import webdriver
import time
import os
if not os.path.exists('./exercise'):
os.mkdir('./exercise')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.75 Safari/537.36'
}
url_list=[]
url_f_list=[]
for i in range(1,4):
url = 'https://sucai.gaoding.com/topic/9080?p={}'.format(i)
url_list.append(url)
for url in url_list:
driver = webdriver.Chrome()
driver.get(url)
driver.maximize_window()
time.sleep(2)
i=0
while i10:
i+=1
driver.execute_script("window.scrollBy(0,500)")
driver.implicitly_wait(5)#顯式等待
items = driver.find_elements_by_xpath("http://*[@class='gdd-lazy-image__img gdd-lazy-image__img--loaded']")
for item in items:
href = item.get_attribute('src')
print(href)
2.2 選取爬蟲策略——api
眾所周知,api接口是個好東西,如果找到了它,我們就無需擔心動態加載,請求api返回給我們的是json格式的字典,里面或許有我們需要的東西也說不定。那么我們重新打開開發者工具搜索一番吧!

從Element切換到Network我們可以發現這里多了好多奇怪的東西,但是打開preview好像沒有我們能用到的。
這個時候別灰心,切換下頁面,等第二頁加載出來的時候最后又多出來了一個xhr文件,點開preview我們驚喜的發現,這個里面有每一張圖id的信息!
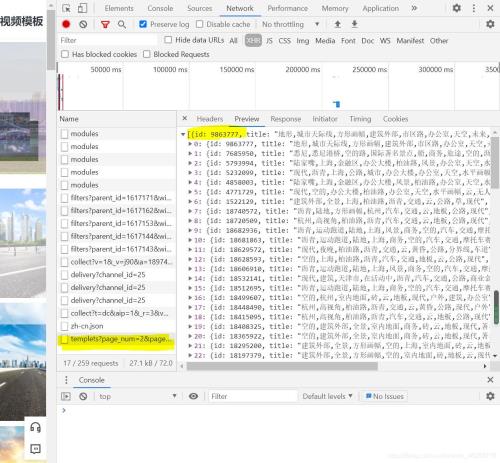
搜尋一圈發現字典里有效的只有id這個值,那么id對于我們的圖片爬取有什么意義呢?通常情況下網址+id就可以定位到具體的圖片,于是我點進去一張壁紙,驚喜的發現跟我想的一樣!

最后又到了我們老生常談的頁數環節,在看到這個api的request url之后大家有沒有觀察到它其中帶著page_num=2page_size=100這兩個看著很像頁碼的參數呢?我們再往下就看到了參數中也正好有這兩個值!也就是說我們只需要更改page_num=2就可以實現翻頁了!
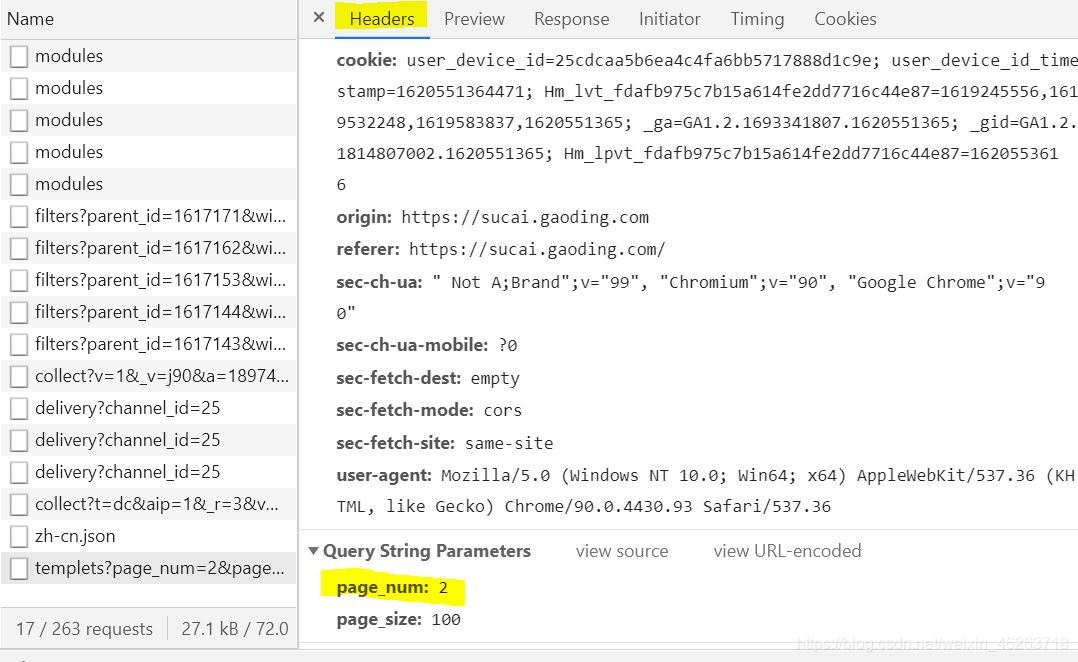
url='https://api-sucai.gaoding.com/api/csc-api/topics/9080/modules/18928/templets?'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
params_list=[]
for i in range(1,4):
parms ={
'page_num': i,
'page_size': 100
}
params_list.append(parms)
解析提取數據
for param in params_list:
response = requests.get(url=url,params=param,headers=headers).json()
for i in range(100):
try:
dict =response[i]
id = dict['id']
url_f = 'https://sucai.gaoding.com/material/'+str(id)
url_f_list.append(url_f)
except:
pass
存儲數據
for l in url_f_list:
print(l)
h = requests.get(url=l, headers=headers).content
i = 'exercise/' + l.split('/')[-1]
with open(i, 'wb') as fp:
fp.write(h)
完整代碼
import os
import requests
if not os.path.exists('./exercise'):
os.mkdir('./exercise')
url='https://api-sucai.gaoding.com/api/csc-api/topics/9080/modules/18928/templets?'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
params_list=[]
url_f_list=[]
for i in range(1,4):
parms ={
'page_num': i,
'page_size': 100
}
params_list.append(parms)
for param in params_list:
response = requests.get(url=url,params=param,headers=headers).json()
for i in range(100):
try:
dict =response[i]
id = dict['id']
url_f = 'https://sucai.gaoding.com/material/'+str(id)
url_f_list.append(url_f)
except:
pass
for l in url_f_list:
print(l)
#h = requests.get(url=l, headers=headers).content
#i = 'exercise/' + l.split('/')[-1]
#with open(i, 'wb') as fp:
# fp.write(h)
三、selenium模擬登錄
我們要爬取的網站總是免不了登錄這一關鍵環節,因此模擬登錄也是一大爬蟲基礎。
我們要模擬登錄的網站如下
https://www.icourse163.org/course/BIT-268001
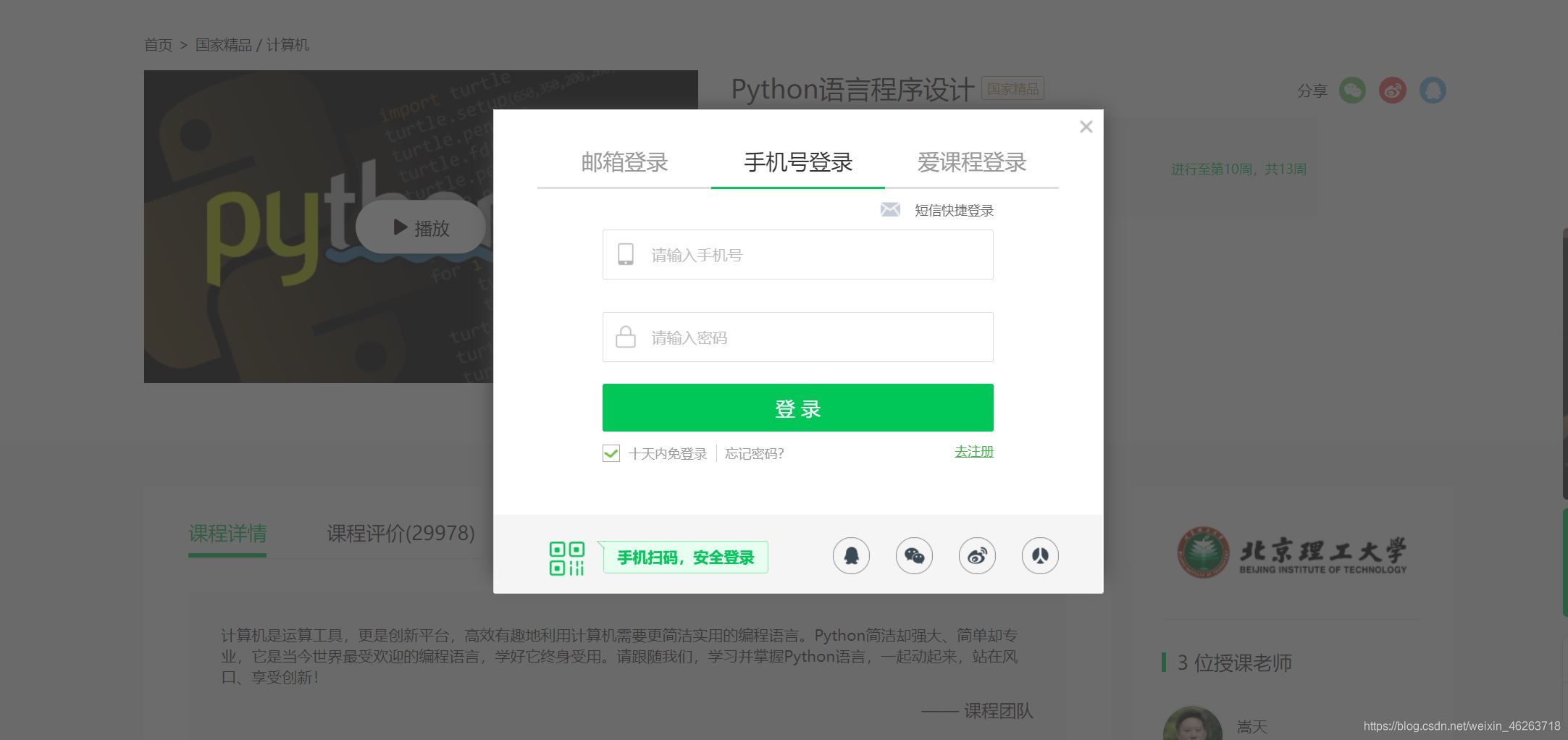
選取爬蟲策略
既然我們是用selenium模擬登陸,首先肯定要明確我們要模擬的具體內容,歸納起來就是
點擊 登錄|注冊
點擊 其他登陸方式
點擊 手機號登錄
輸入賬號
輸入密碼
點擊 登錄
在明確該干些什么之后我們就打開開發者模式觀察一下這個登錄框吧。
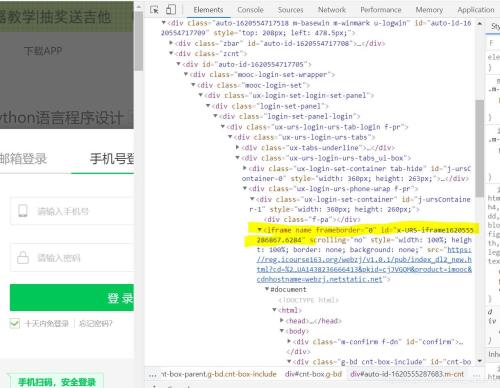
不看不知道,一看嚇一跳,原來這里有一個iframe框架,這就意味著如果我們不做任何處理就查找元素的話可能會什么都查找不到。這就相當于在王家找李家的東西一樣,我們首先需要切換到當前iframe
driver.switch_to.frame(driver.find_element_by_xpath('//*[@id="j-ursContainer-1"]/iframe'))
經過這一操作之后我們就可以正常按部就班的進行模擬登陸了!
完整代碼
from selenium import webdriver
import time
url = 'https://www.icourse163.org/course/BIT-268001'
driver = webdriver.Chrome()
driver.get(url)
driver.maximize_window()
#time.sleep(2)
driver.find_element_by_xpath('//div[@class="unlogin"]/a').click()
driver.find_element_by_class_name('ux-login-set-scan-code_ft_back').click()
driver.find_element_by_xpath('//ul[@class="ux-tabs-underline_hd"]/li[2]').click()
driver.switch_to.frame(driver.find_element_by_xpath('//*[@id="j-ursContainer-1"]/iframe'))
driver.implicitly_wait(2)#給登錄框一些加載的時間
driver.find_element_by_css_selector('input[type="tel"]').send_keys('15201359153')
driver.find_element_by_css_selector('input[class="j-inputtext dlemail"]').send_keys('Asdasd123')
driver.implicitly_wait(2)#如果不等待的話可能密碼還沒輸入結束就點按登錄鍵了
driver.find_element_by_id('submitBtn').click()
到此這篇關于python基礎之爬蟲入門的文章就介紹到這了,更多相關python入門爬蟲內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Python爬蟲數據的分類及json數據使用小結
- python爬蟲scrapy圖書分類實例講解
- Python爬蟲實現的根據分類爬取豆瓣電影信息功能示例
- Python異步爬蟲實現原理與知識總結
- Python爬蟲之線程池的使用
- python爬蟲請求庫httpx和parsel解析庫的使用測評
- Python爬蟲之爬取最新更新的小說網站
- 用Python爬蟲破解滑動驗證碼的案例解析
- Python爬蟲基礎之爬蟲的分類知識總結
