Facebook的數據倉庫存儲在少量大型Hadoop/HDFS集群。Hive是Facebook在幾年前專為Hadoop打造的一款數據倉庫工具。在以前,Facebook的科學家和分析師一直依靠Hive來做數據分析。但Hive使用MapReduce作為底層計算框架,是專為批處理設計的。但隨著數據越來越多,使用Hive進行一個簡單的數據查詢可能要花費幾分到幾小時,顯然不能滿足交互式查詢的需求。Facebook也調研了其他比Hive更快的工具,但它們要么在功能有所限制要么就太簡單,以至于無法操作Facebook龐大的數據倉庫。
2012年開始試用的一些外部項目都不合適,他們決定自己開發,這就是Presto。2012年秋季開始開發,目前該項目已經在超過 1000名Facebook雇員中使用,運行超過30000個查詢,每日數據在1PB級別。Facebook稱Presto的性能比Hive要好上10倍多。2013年Facebook正式宣布開源Presto。
本文首先介紹Presto從用戶提交SQL到執行的這一個過程,然后嘗試對Presto實現實時查詢的原理進行分析和總結,最后介紹Presto在美團的使用情況。
Presto架構
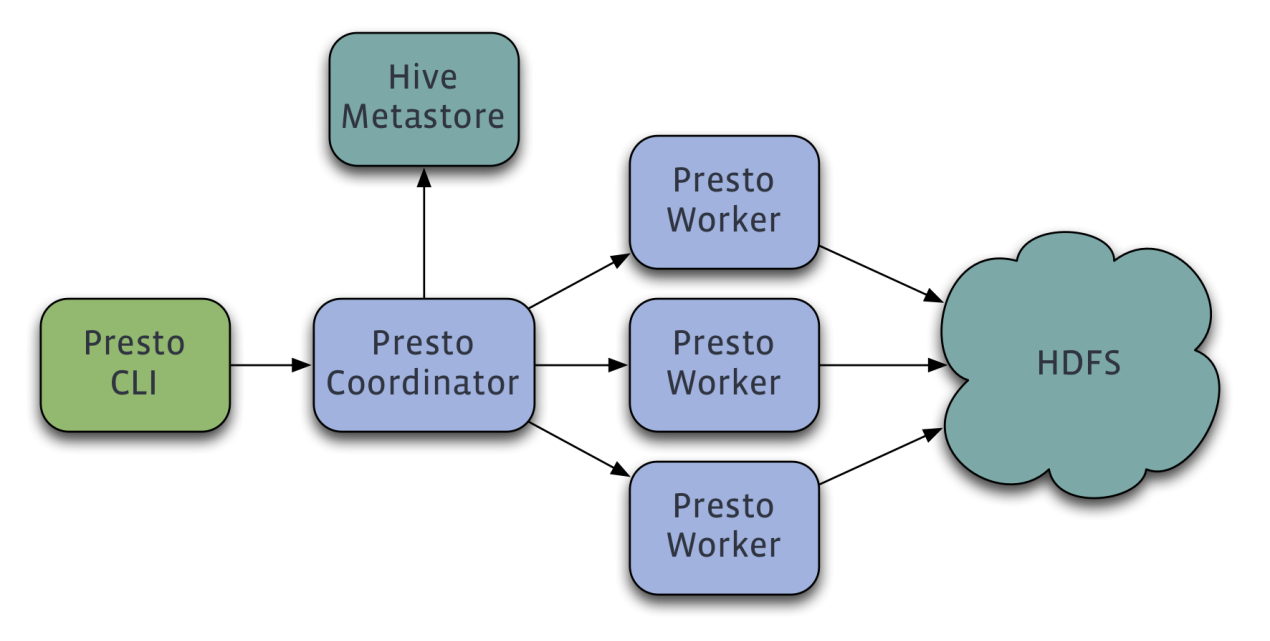
Presto查詢引擎是一個Master-Slave的架構,由一個Coordinator節點,一個Discovery Server節點,多個Worker節點組成,Discovery Server通常內嵌于Coordinator節點中。Coordinator負責解析SQL語句,生成執行計劃,分發執行任務給Worker節點執行。Worker節點負責實際執行查詢任務。Worker節點啟動后向Discovery Server服務注冊,Coordinator從Discovery Server獲得可以正常工作的Worker節點。如果配置了Hive Connector,需要配置一個Hive MetaStore服務為Presto提供Hive元信息,Worker節點與HDFS交互讀取數據。
Presto執行查詢過程簡介
既然Presto是一個交互式的查詢引擎,我們最關心的就是Presto實現低延時查詢的原理,我認為主要是下面幾個關鍵點,當然還有一些傳統的SQL優化原理,這里不介紹了。
完全基于內存的并行計算
流水線
本地化計算
動態編譯執行計劃
小心使用內存和數據結構
類BlinkDB的近似查詢
GC控制
為了介紹上述幾個要點,這里先介紹一下Presto執行查詢的過程
提交查詢
用戶使用Presto Cli提交一個查詢語句后,Cli使用HTTP協議與Coordinator通信,Coordinator收到查詢請求后調用SqlParser解析SQL語句得到Statement對象,并將Statement封裝成一個QueryStarter對象放入線程池中等待執行。
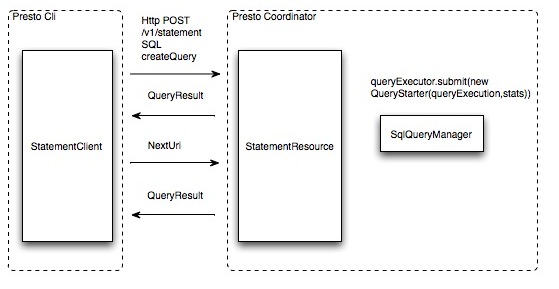
SQL編譯過程
Presto與Hive一樣,使用Antlr編寫SQL語法,語法規則定義在Statement.g和StatementBuilder.g兩個文件中。
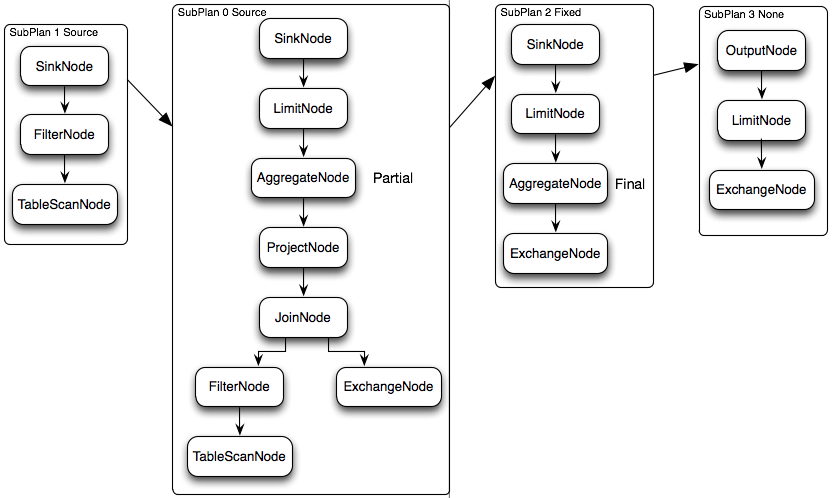
如下圖中所示從SQL編譯為最終的物理執行計劃大概分為5部,最終生成在每個Worker節點上運行的LocalExecutionPlan,這里不詳細介紹SQL解析為邏輯執行計劃的過程,通過一個SQL語句來理解查詢計劃生成之后的計算過程。

樣例SQL:
select c1.rank, count(*) from dim.city c1 join dim.city c2 on c1.id = c2.id where c1.id > 10 group by c1.rank limit 10;
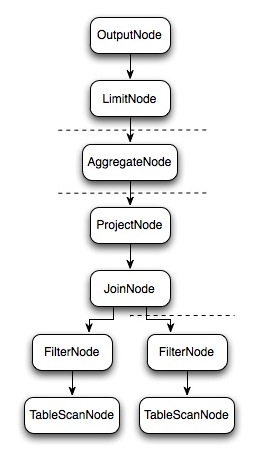
上面的SQL語句生成的邏輯執行計劃Plan如上圖所示。那么Presto是如何對上面的邏輯執行計劃進行拆分以較高的并行度去執行完這個計劃呢,我們來看看物理執行計劃。
物理執行計劃
邏輯執行計劃圖中的虛線就是Presto對邏輯執行計劃的切分點,邏輯計劃Plan生成的SubPlan分為四個部分,每一個SubPlan都會提交到一個或者多個Worker節點上執行。
SubPlan有幾個重要的屬性planDistribution、outputPartitioning、partitionBy屬性。
PlanDistribution表示一個查詢Stage的分發方式,邏輯執行計劃圖中的4個SubPlan共有3種不同的PlanDistribution方式:Source表示這個SubPlan是數據源,Source類型的任務會按照數據源大小確定分配多少個節點進行執行;Fixed表示這個SubPlan會分配固定的節點數進行執行(Config配置中的query.initial-hash-partitions參數配置,默認是8);None表示這個SubPlan只分配到一個節點進行執行。在下面的執行計劃中,SubPlan1和SubPlan0 PlanDistribution=Source,這兩個SubPlan都是提供數據源的節點,SubPlan1所有節點的讀取數據都會發向SubPlan0的每一個節點;SubPlan2分配8個節點執行最終的聚合操作;SubPlan3只負責輸出最后計算完成的數據。
OutputPartitioning屬性只有兩個值HASH和NONE,表示這個SubPlan的輸出是否按照partitionBy的key值對數據進行Shuffle。在下面的執行計劃中只有SubPlan0的OutputPartitioning=HASH,所以SubPlan2接收到的數據是按照rank字段Partition后的數據。
完全基于內存的并行計算
查詢的并行執行流程
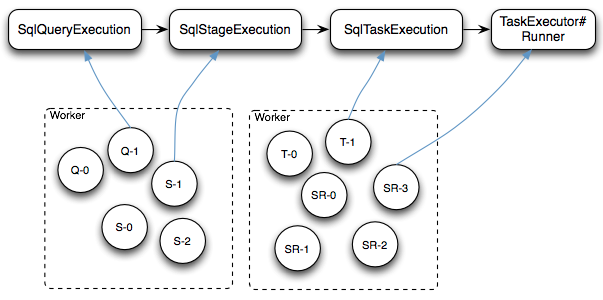
Presto SQL的執行流程如下圖所示
Cli通過HTTP協議提交SQL查詢之后,查詢請求封裝成一個SqlQueryExecution對象交給Coordinator的SqlQueryManager#queryExecutor線程池去執行
每個SqlQueryExecution線程(圖中Q-X線程)啟動后對查詢請求的SQL進行語法解析和優化并最終生成多個Stage的SqlStageExecution任務,每個SqlStageExecution任務仍然交給同樣的線程池去執行
每個SqlStageExecution線程(圖中S-X線程)啟動后每個Stage的任務按PlanDistribution屬性構造一個或者多個RemoteTask通過HTTP協議分配給遠端的Worker節點執行
Worker節點接收到RemoteTask請求之后,啟動一個SqlTaskExecution線程(圖中T-X線程)將這個任務的每個Split包裝成一個PrioritizedSplitRunner任務(圖中SR-X)交給Worker節點的TaskExecutor#executor線程池去執行
上面的執行計劃實際執行效果如下圖所示。
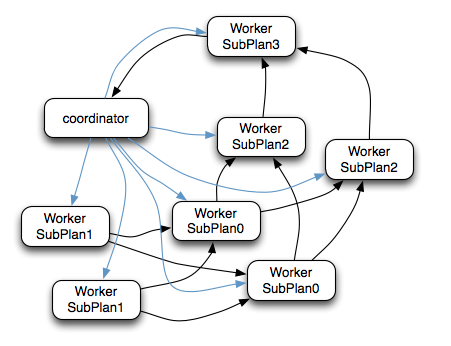
Coordinator通過HTTP協議調用Worker節點的 /v1/task 接口將執行計劃分配給所有Worker節點(圖中藍色箭頭)
SubPlan1的每個節點讀取一個Split的數據并過濾后將數據分發給每個SubPlan0節點進行Join操作和Partial Aggr操作
SubPlan1的每個節點計算完成后按GroupBy Key的Hash值將數據分發到不同的SubPlan2節點
所有SubPlan2節點計算完成后將數據分發到SubPlan3節點
SubPlan3節點計算完成后通知Coordinator結束查詢,并將數據發送給Coordinator
源數據的并行讀取
在上面的執行計劃中SubPlan1和SubPlan0都是Source節點,其實它們讀取HDFS文件數據的方式就是調用的HDFS InputSplit API,然后每個InputSplit分配一個Worker節點去執行,每個Worker節點分配的InputSplit數目上限是參數可配置的,Config中的query.max-pending-splits-per-node參數配置,默認是100。
分布式的Hash聚合
上面的執行計劃在SubPlan0中會進行一次Partial的聚合計算,計算每個Worker節點讀取的部分數據的部分聚合結果,然后SubPlan0的輸出會按照group by字段的Hash值分配不同的計算節點,最后SubPlan3合并所有結果并輸出
流水線
數據模型
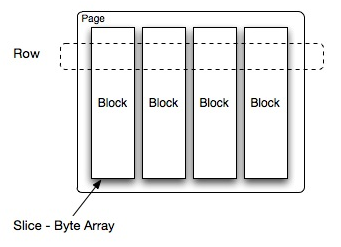
Presto中處理的最小數據單元是一個Page對象,Page對象的數據結構如下圖所示。一個Page對象包含多個Block對象,每個Block對象是一個字節數組,存儲一個字段的若干行。多個Block橫切的一行是真實的一行數據。一個Page最大1MB,最多16*1024行數據。
節點內部流水線計算
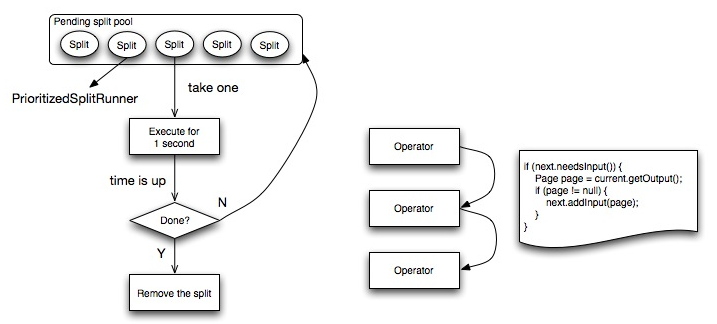
下圖是一個Worker節點內部的計算流程圖,左側是任務的執行流程圖。
Worker節點將最細粒度的任務封裝成一個PrioritizedSplitRunner對象,放入pending split優先級隊列中。每個
Worker節點啟動一定數目的線程進行計算,線程數task.shard.max-threads=availableProcessors() * 4,在config中配置。
每個空閑的線程從隊列中取出一個PrioritizedSplitRunner對象執行,如果執行完成一個周期,超過最大執行時間1秒鐘,判斷任務是否執行完成,如果完成,從allSplits隊列中刪除,如果沒有,則放回pendingSplits隊列中。
每個任務的執行流程如下圖右側,依次遍歷所有Operator,嘗試從上一個Operator取一個Page對象,如果取得的Page不為空,交給下一個Operator執行。
節點間流水線計算
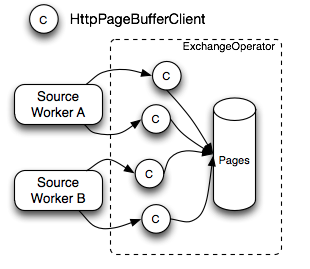
下圖是ExchangeOperator的執行流程圖,ExchangeOperator為每一個Split啟動一個HttpPageBufferClient對象,主動向上一個Stage的Worker節點拉數據,數據的最小單位也是一個Page對象,取到數據后放入Pages隊列中
本地化計算
Presto在選擇Source任務計算節點的時候,對于每一個Split,按下面的策略選擇一些minCandidates
優先選擇與Split同一個Host的Worker節點
如果節點不夠優先選擇與Split同一個Rack的Worker節點
如果節點還不夠隨機選擇其他Rack的節點
對于所有Candidate節點,選擇assignedSplits最少的節點。
動態編譯執行計劃
Presto會將執行計劃中的ScanFilterAndProjectOperator和FilterAndProjectOperator動態編譯為Byte Code,并交給JIT去編譯為native代碼。Presto也使用了Google Guava提供的LoadingCache緩存生成的Byte Code。

上面的兩段代碼片段中,第一段為沒有動態編譯前的代碼,第二段代碼為動態編譯生成的Byte Code反編譯之后還原的優化代
碼,我們看到這里采用了循環展開的優化方法。
循環展開最常用來降低循環開銷,為具有多個功能單元的處理器提供指令級并行。也有利于指令流水線的調度。
小心使用內存和數據結構
使用Slice進行內存操作,Slice使用Unsafe#copyMemory實現了高效的內存拷貝,Slice倉庫參考:https://github.com/airlift/slice
Facebook工程師在另一篇介紹ORCFile優化的文章中也提到使用Slice將ORCFile的寫性能提高了20%~30%,參考:https://code.facebook.com/posts/229861827208629/scaling-the-facebook-data-warehouse-to-300-pb/
類BlinkDB的近似查詢
為了加快avg、count distinct、percentile等聚合函數的查詢速度,Presto團隊與BlinkDB作者之一Sameer Agarwal合作引入了一些近似查詢函數approx_avg、approx_distinct、approx_percentile。approx_distinct使用HyperLogLog Counting算法實現。
GC控制
Presto團隊在使用hotspot java7時發現了一個JIT的BUG,當代碼緩存快要達到上限時,JIT可能會停止工作,從而無法將使用頻率高的代碼動態編譯為native代碼。
Presto團隊使用了一個比較Hack的方法去解決這個問題,增加一個線程在代碼緩存達到70%以上時進行顯式GC,使得已經加載的Class從perm中移除,避免JIT無法正常工作的BUG。
美團如何使用Presto
選擇presto的原因
2013年我們也用過一段時間的impala,當時impala不支持線上1.x的hadoop社區版,所以搭了一個CDH的小集群,每天將大集群的熱點數據導入小集群。但是hadoop集群年前完成升級2.2之后,當時的impala還不支持2.2 hadoop版本。而Presto剛好開始支持2.x hadoop社區版,并且Presto在Facebook 300PB大數據量的環境下可以成功的得到大量使用,我們相信它在美團也可以很好的支撐我們實時分析的需求,于是決定先上線測試使用一段時間。
部署和使用形式
考慮到兩個原因:1、由于Hadoop集群主要是夜間完成昨天的計算任務,白天除了日志寫入外,集群的計算負載較低。2、Presto Worker節點與DataNode節點布置在一臺機器上可以本地計算。因此我們將Presto部署到了所有的DataNode機器上,并且夜間停止Presto服務,避免占用集群資源,夜間基本也不會有用戶查詢數據。
Presto二次開發和BUG修復
年后才正式上線Presto查詢引擎,0.60版本,使用的時間不長,但是也遇到了一些問題:
美團的Hadoop使用的是2.2版本,并且開啟了Security模式,但是Presto不支持Kerberos認證,我們修改了Presto代碼,增加了Kerberos認證的功能。
Presto還不支持SQL的隱式類型轉換,而Hive支持,很多自助查詢的用戶習慣了Hive,導致使用Presto時都會出現表達式中左右變量類型不匹配的問題,我們增加了隱式類型轉換的功能,大大減小了用戶SQL出錯的概率。
Presto不支持查詢lzo壓縮的數據,需要修改hadoop-lzo的代碼。
解決了一個having子句中有distinct字段時查詢失敗的BUG,并反饋了Presto團隊 https://github.com/facebook/presto/pull/1104
所有代碼的修改可以參考我們在github上的倉庫 https://github.com/MTDATA/presto/commits/mt-0.60
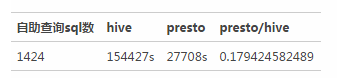
實際使用效果
這里給出一個公司內部開放給分析師、PM、工程師進行自助查詢的查詢中心的一個測試報告。這里選取了平時的5000個Hive查詢,通過Presto查詢的對比見下面的表格。