join的寫法
如果用left join 左邊的表一定是驅動表嗎�?兩個表的join包含多個條件的等值匹配����,都要寫道on還是只把一個寫到on,其余寫道where部分����?
create table a(f1 int, f2 int, index(f1))engine=innodb;
create table b(f1 int, f2 int)engine=innodb;
insert into a values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6);
insert into b values(3,3),(4,4),(5,5),(6,6),(7,7),(8,8);
select * from a left join b on(a.f1=b.f1) and (a.f2=b.f2); /*Q1*/
select * from a left join b on(a.f1=b.f1) where (a.f2=b.f2);/*Q2*/
執行結果:

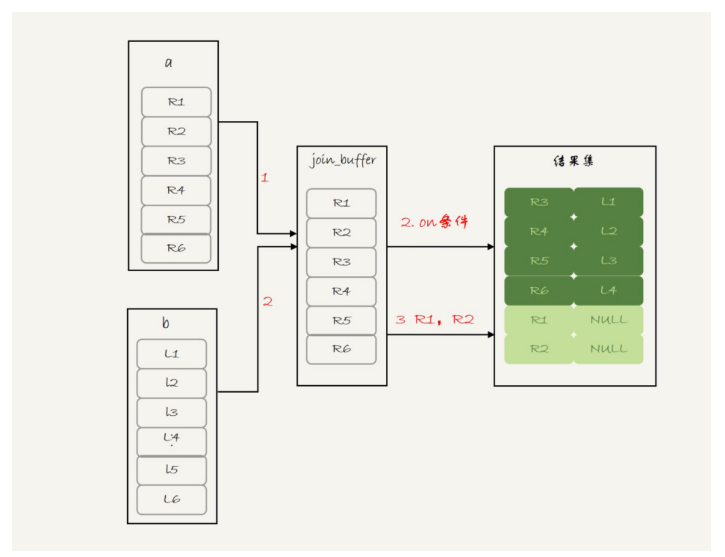
由于表b沒有索引���,使用的是Block Nexted Loop Join(BNL)算法
- 把表a的內容讀入join_buffer中,因為select * ���,所以字段f1����,f2都被放入
- 順序掃描b,對于每一行數據�,判斷join條件是否滿足,滿足條件的記錄���,作為結果集的一行����,如果有where子句�,判斷where部分滿足條件后再返回����。
- 表b掃描完成后���,對于沒有匹配的表a的行���,用null補上,放到結果集中����。
Q2語句中�,explain結果:

b為驅動表���,如果一條語句EXTRA字段什么都沒有的話�,就是Index Nested_Loop Join算法����,因此流程是:
順序掃描b���,每一行用b.f1到a中去查����,匹配a.f2=b.f2是否滿足����,作為結果集返回���。
Q1與Q2執行流程的差異是因為優化器基于Q2這個查詢語義做了優化:在mysql里,null跟任何值執行等值判斷和不等值判斷的結果都是null,包括select null = null 也返回null�。
在Q2中,where a.f2 = b.f2表示�,查詢結果里不會包含b.f2是null的行���,這樣left join語義就是找到兩個表里f1 f2對應相同的行����,如果a存在而b匹配不到�,就放棄���。因此優化器把這條語句的left join改寫成了join�,因為a的f1有索引,就把b作為驅動表���,這樣可以用NLJ算法,所以在使用left join時����,左邊的表不一定是驅動表����。
如果需要left join的語義���,就不能把被驅動表的字段放在where條件里做等值判斷或不等值判斷,必須寫在on里面����。
Nested Loop Join的性能問題
BLN算法的執行邏輯
- 將驅動表的數據全部讀入join_buffer中,里面是無序數組����。
- 順序遍歷被驅動表的所有行���,每一行都跟join_buffer做匹配����,成功則作為結果集的一部分返回���。
Simple Nested Loop Join算法邏輯是:順序去除驅動表的每一行數據���,到被驅動表做全表匹配。
兩者差異:
在對被驅動表做全表掃描時,如果數據沒有在buffer pool中����,需要等待部分數據從磁盤讀入���。會影響正常業務的buffer pool命中率����,而且會對被驅動表做多次訪問�,更容易將這些數據頁放到buffer pool頭部����。所以BNL算法性能會更好。自增id
mysql中自增id定義了初始值,不停的增長�,但是有上限,2^32-1����,自增的id用完了會怎么樣呢�。
表定義的自增值達到上限后���,再申請下一個id時�,得到的值保持不變����。再次插入時會報主鍵沖突錯誤。所以在建表時���,如果有頻繁的增刪改時�,就應該創建8個字節的bigint unsigned�。
innodb 系統自增row_id
如果創建了Innodb表沒有指定主鍵,那么innodb會創建一個不可見的����,長度為6個字節的row_id���,所有無主鍵的innodb表���,每插入一行數據,都將當前的dict_sys.row_id值作為要插入數據的row_id���,然后自增1�。
實際上�,代碼實現時����,row_id是一個長度為8字節的無符號長整形,但是innodb在設計時,給row_id只是6個字節的長度���,這樣寫道數據時只放了最后6個字節。所以:
- row_id寫入表的范圍是0到2^48-1;
- 當達到最大時,如果再有插入數據的行為來申請row_id���,拿到以后再去最后6個字節就是0,然后繼續循環。
- 再innodb的邏輯里,達到最大后循環���,新數據會覆蓋已經存在的數據。
從這個角度看,我們應該主動創建自增主鍵�,這樣達到上限后���,插入數據會報錯�。數據的可靠性會更加有保障���。
XID
redo log 和 binlog相互配合的時候����,它們有一個共同的字段就是xid,在mysql中對應事務的�。xid最大時2^64次方���,用盡只存在理論����。
thread_id
系統保存了全局變量thread_id_counter����,每新建一個連接����,就將thread_id_counter賦值給這個新連接的線程變量。thread_id_counter定義的大小是4個字節����,因此到2^32-1就會重置為0����,然后繼續增加�。但是show processlist里不會看到兩個相同的thread_id,這是因為mysql設計了一個唯一數組邏輯,給新線程分配thread_id的時候:
do {
new_id= thread_id_counter++;
} while (!thread_ids.insert_unique(new_id).second);
以上就是本文的全部內容,希望對大家的學習有所幫助�,也希望大家多多支持腳本之家���。
您可能感興趣的文章:- Mysql自增主鍵id不是以此逐級遞增的處理
- Mysql主鍵UUID和自增主鍵的區別及優劣分析
- 詳解mysql插入數據后返回自增ID的七種方法
- MySQL的自增ID(主鍵) 用完了的解決方法
- 關于mysql自增id�,你需要知道的
- MySQL表自增id溢出的故障復盤解決
- 關于MySQL自增ID的一些小問題總結
- mysql id從1開始自增 快速解決id不連續的問題
